HTTP协议简介:
一些基本概念:
- 协议:指计算机通信网络中两台计算机之间进行通信所必须共同遵守的规定或规则。
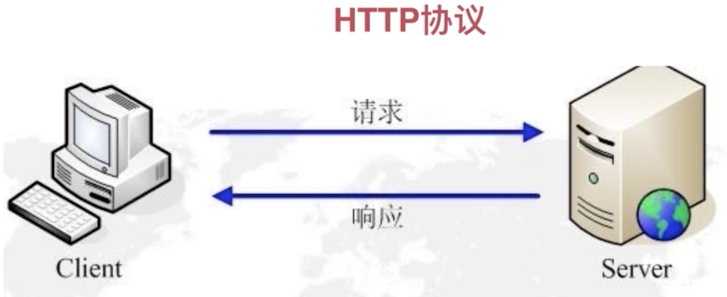
- HTTP协议:超文本传输协议(HTTP)是一种通信协议,它允许将超文本标记语言(HTML)文档从Web服务器传送给客户端的流览器。下面看一个图:
URI和URL的区别:
URI:是uniform resource identifier,统一资源标识符,用来唯一的标识一个资源。它主要是由三部分主成:
- 访问资源的命名机制。
- 存放资源的主机名。
- 资源自身的名称,由路径表示,着重强调于资源。
举个粟子:file://a:1234/b/c/d.txt,其中file://表示访问资源的命名机制;a:1234表示存放资源的主机名;b/c/d.txt表示资源自身的路径。
URL:是uniform resource locator,统一资源定位器,它是一种具体的URI,用URL可以用来标识一个资源,而且还指明了如何locate这个资源。
它主要是由以下三部分组成:
- 协议【如http或htpps协议】。
- 存在该资源的主机ip地址。
- 主机资源的具体地址。
所以URL是具体的URI,它强调用的是路径,而URI强调的是资源。
HTTP协议的特点:
- 简单快速。
- 无连接。每次请求就会自动断开。
- 无状态。这个协议对于以前的数据是没有记忆的。
request / reponse:
打开浏览器,在地址栏中输入URL,然后我们看到了网页,那原理是怎样的呢?
其简单的原理是:当输入URL时浏览器会向Web服务器发送一个request请求,而Web服务器收到请求之后会进行相应的处理,然后再将response发送给浏览器,接着浏览器就解析这个response的html文档,这样就看到了咱们的网页,而有可能request是经过代理服务器【它是一个中转站,能提高访问速度,因为大多数代理服务器都有缓存功能,如果访问地址时先走缓存,最后再走Web服务器】最后再到达Web服务器。
而对于request和response的头信息有哪些是值得咱们在面试时需要观注的呢?这里采用charles对请求进行拦截进行查看:
request:
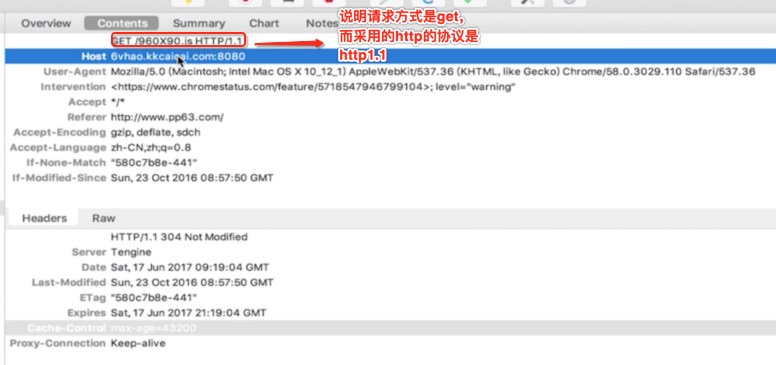

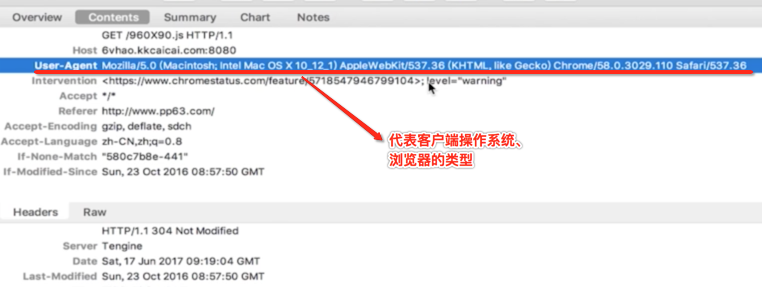

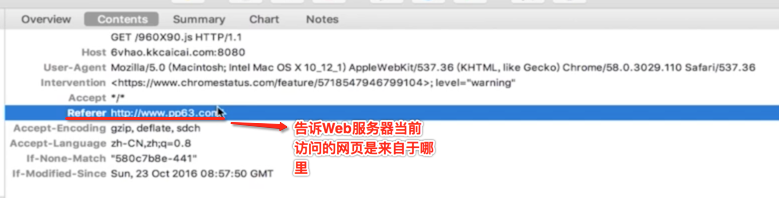
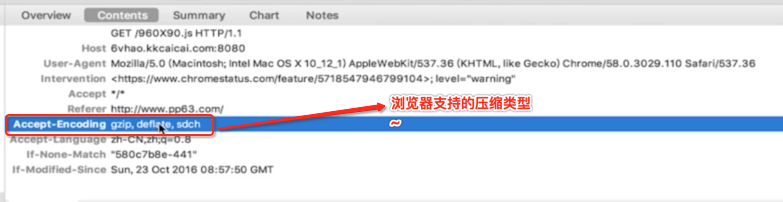
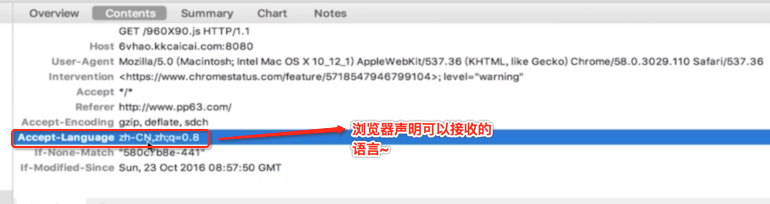
接下来两个头信息是比较容易忽略但是很重要,如下:

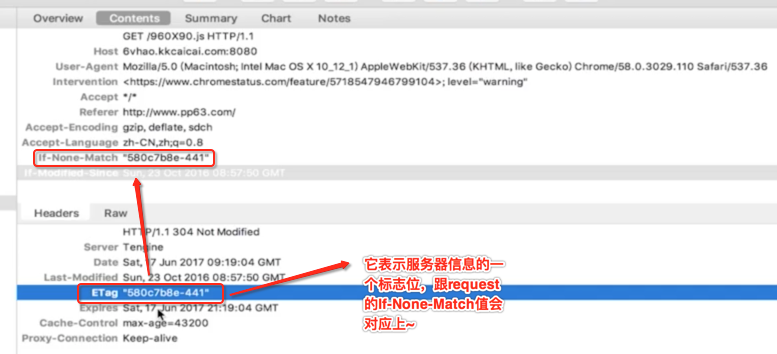
它通常需要与response中请求头中的ETag联合使用的,它的大概工作原理是:告诉reponse中可以添加ETag进去,如果再次请求时则会在请求头添的If-No-Match中ETag的值,这时就可以通过服务器来验证该ETag值有木有改变,如果木有改变的话则会给客户端返回一个304状态码来告诉客户端可以使用本地缓存文件,这就大大提高了客户端的性能。

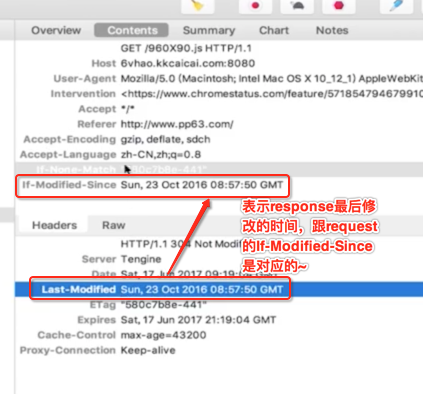
它是将缓存页面的最后修改时间发送给服务器,而服务器会根据这个时间再来和服务器实际文件的最后修改时间进行比较,如果一致则返回304给客户端,如果不一致则会返回200并将最新的内容下发给客户端。
纵观整个请求头,Referer和If-No-Match这两个请求头在面试中是经常会被问到的,所以这里需要注意。
response:
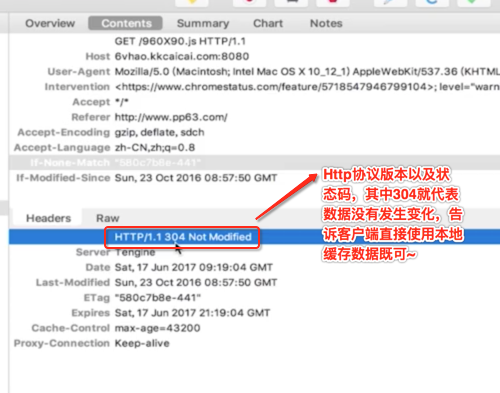

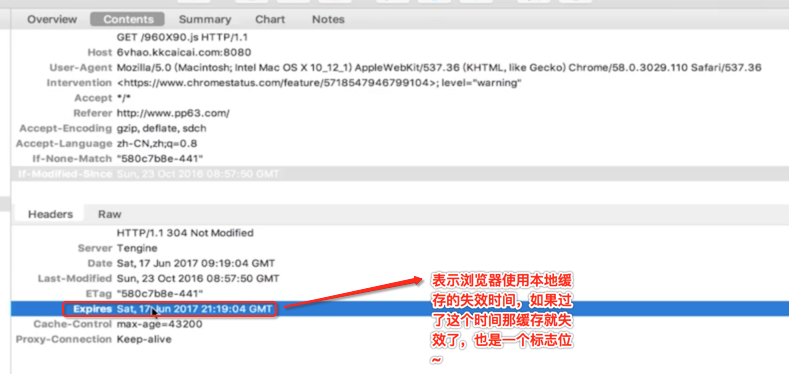
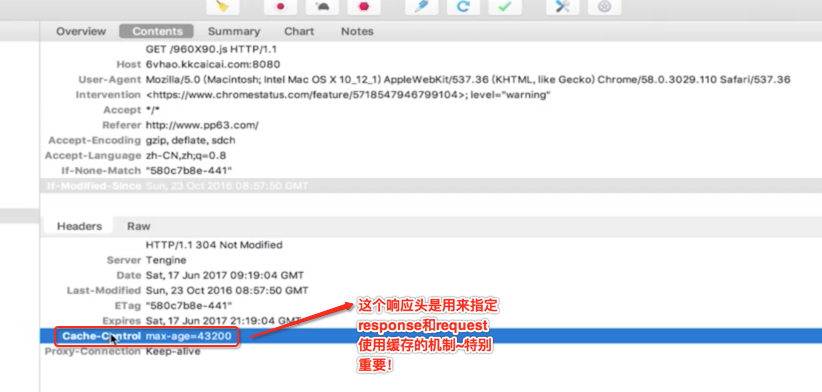
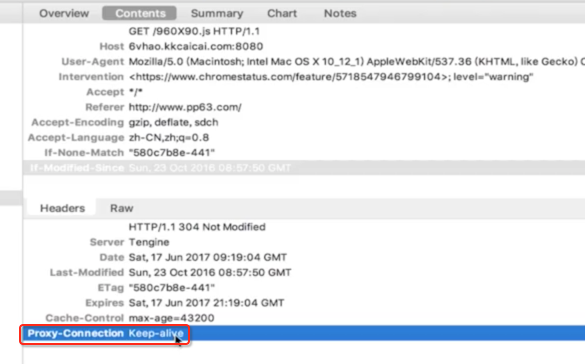
最后一个代理连接响头是非常重要的,keep-alive表示当客户端访问服务端的http的Tcp连接不会被关闭,如果客户端再次访问,那么就会继续用这个建议好的TCP连接而不会再次建立连接。
HTTP协议中比较容易混淆的知识点:
http1.1/http1.0的区别:
- http1.0产生的背景
超文本传输协议(HyperText Transfer Protocol)伴随着计算机网络和浏览器的诞生,HTTP1.0也随之而来,处于计算机网络跌应用层,在TCP协议之上的, - http1.0所做的优化
带宽:现阶段已经解决。
延迟:1.浏览器阻塞:浏览器对于同一个域名,同时只能有4个连接。
延迟:2.DNS查询:浏览器需要知道目标服务器的IP才能建立连接。
延迟:3.建立连接:三次握手。由于Http是基于Tcp的~ - http1.1/http1.0的具体区别
1、缓存处理:在http1.0时代,缓存主要是利用请求头的If-Modified-Since来做为缓存策略的标准,而在http1.1引入了更多的缓存策略,比如If-None-Match。
2、带宽优化及网络连接的使用:在http1.0中存在一些浪费带宽的现象,比如客户端请求服务器只需要一小部份数据,但是服务端会一股脑的将整个数据都返回,同时又不支持断点续传功能,而在http1.1中请求头中引入了一个range请求头,它允许只请求某个范围的数据。
3、Host头处理:在http1.0中一台主机只对应一个唯一一个IP地址,因为请求的消息头中并没有传递主机名,而随着虚拟主机的发展,一台物理机可以存在多个虚拟主机,并且共享一个IP地址,在http1.1中request和response都带有host头消息,如果木有则会报400错误。
4、长连接【这是最大的区别~】:在http1.0中每次请求都需要创建连接,而在http1.1中默认就支持keep-alive长连接,性能大大提高。 - http1.1/http1.0存在的问题
1、Http1.X在传输数据时,每次都需要重新建立连接,无疑增加了大量的延迟时间。【指的http1.0,换成http1.1可以解决此问题】
2、Http1.X在传输数据时,所有传输的数据都是明文,客户端与服务器端都无法验证对方的身份【用https可以解决此问题】
3、Http1.X在使用时,header里携带的内容过大,在一定程序上增加了传输的成本。
4、虽然在Http1.X支持了keep-alive,来弥补多次创建连接产生的延迟,但是keep-alive使用多了同样会给服务器带来大量的性能压力。
get/post方法的区别:
- 提交的数据:get在提交时数据会在URL当中体现,post一般提交时都会在body中。
- 提交的数据大小是否有限制:对于get方法有大小限制,而post方法没有限制,因为在body中。
- 取得变量的值:get方式是通过Request.QueryString取得,而post方式是通过Request.From来取得。
- 安全问题:get方式肯定是不太安全,因为数据是携带在URL当中的,而post则比较安全。
cookie和session的区别:
cookie:
- 什么是cookie?
Cookie技术是客户端的解决方案,Cookie就是由服务器发给客户端的特殊信息,而这些信息以文本文件的方式存放在客户端,然后客户端每次向服务器发送请求的时候都会带上这些特殊的信息。而cookie的设置主要是分为如下以个步骤:
它的机制的引入就解决了Http无状态的问题。
- 工作原理:
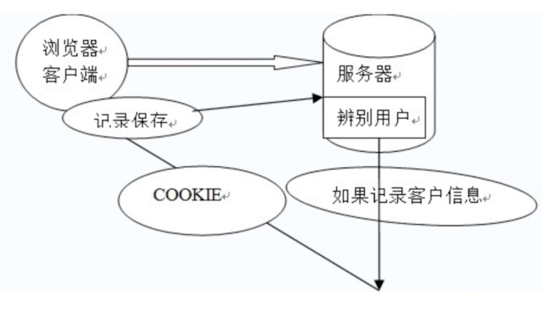
它是保存在客户端的。
session:
- 什么是session?
Session是另一种记录客户状态的机制,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上。客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上。 - session的工作原理:
1、第一步当然是创建session了:在服务端运行时来创建。
2、在创建了session的同时,服务器会为该session生成唯一的session id。
3、在session被创建之后,就可以调用session相关的方法往session中增加内容。
4、当客户端再次发送请求的时候,会将这个session id带上,服务器接受了请求之后就会依据session id找到相应的session。
区别:
- 存储位置不同:session是保存在服务器端,而cookies是保存在客户端。
- 存取方式的不同:session可以存存任何数据类型,而cookies只能保存字符串。
- 安全性(隐私策略)不同:session安全,cookies不安全。
- 有效期上的不同:session有效期较短,而cookies可以比较长。
- 对服务器造成的压力不同:session对服务器压力较大,而cookies是保存在客户端完全对服务器不会造成压力。