免责声明:代码仅作技术交流使用,如有侵权请联系本人删除!
起因就是想白嫖形政作业时这个网站告诉我复制要扫码或者收费
我:???
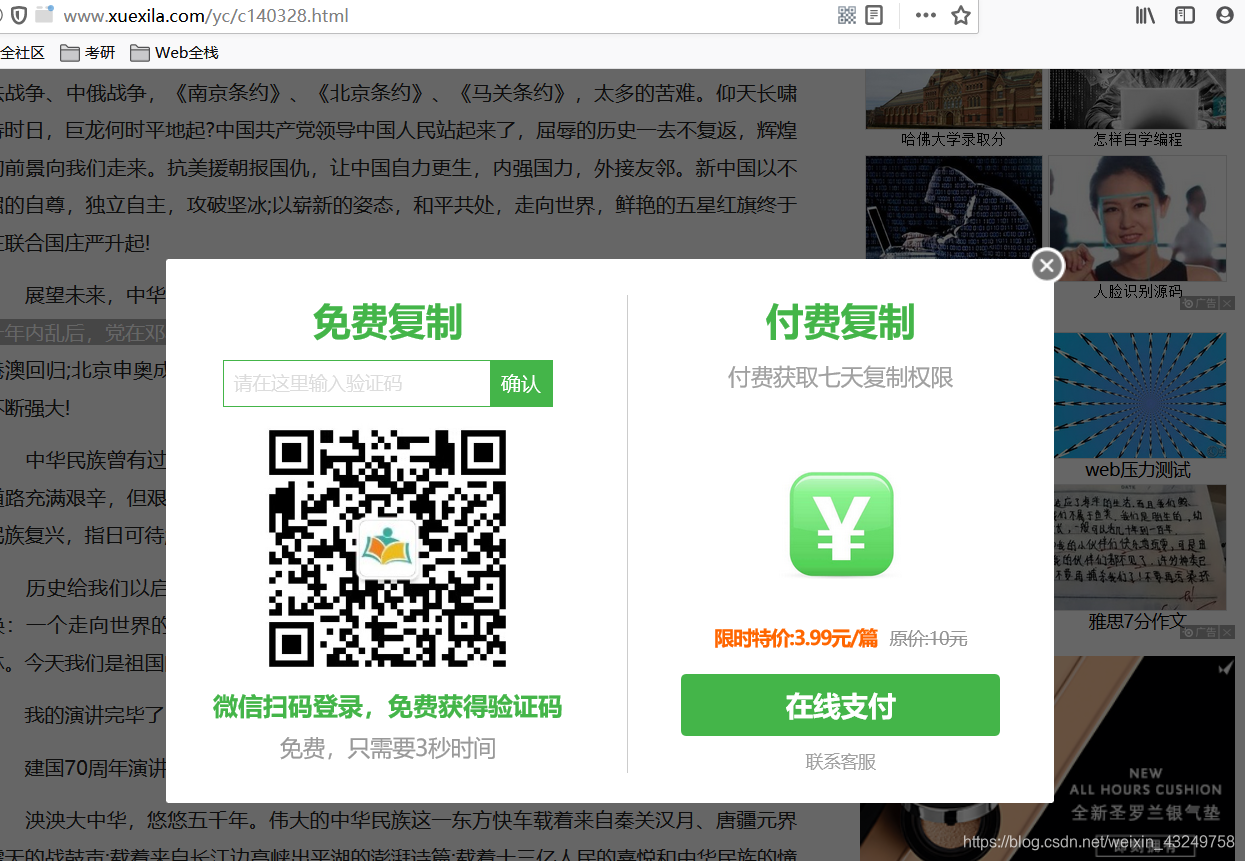
不好意思
流氓会武术
谁也挡不住
import requests
from requests.exceptions import HTTPError
import re
def GetHTML(url,path):
try:
res=requests.get(url)
res.raise_for_status()
coding=res.encoding
with open(path,"w+",encoding=coding) as MyFile:
MyFile.write(res.text)
except HTTPError:
print("HTTP Error!")
except ConnectionError:
print("Failed to connect!")
def DataWash(path):
mid=[]
final=[]
with open(path,"r",encoding="gbk") as ReadFile:
MyLines=ReadFile.readlines()
for ML in MyLines:
if re.search("img",ML)==None and re.search("</p>",ML)!=None:
mid.append(ML)
for i in mid:
i=re.sub("<.+?>"," ",i)
i=re.sub("&.+?;"," ",i)
final.append(i)
return final
def SaveFile(final,path):
with open(path,"w+",encoding="gbk") as FinalFile:
for i in final:
if len(i)!=0:
FinalFile.write(i)
FinalFile.write("\n")
if __name__=='__main__':
url=input('输入学习啦url')
path=input('输入存放路径')
GetHTML(url,path)
final=DataWash(path)
SaveFile(final,path)
print('Done')
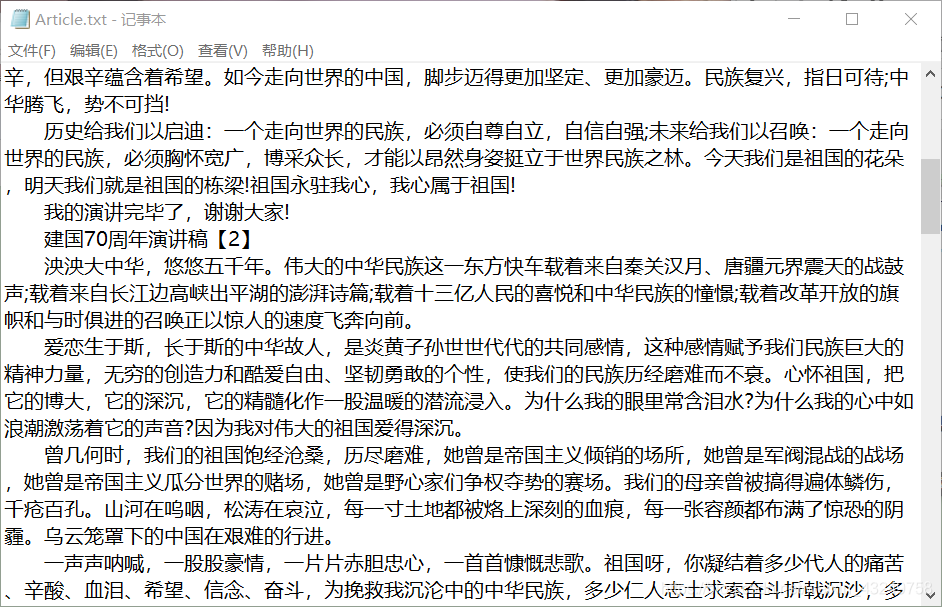
效果如下