一.项目架构
SpringCloud Dalston.SR1 + SpringBoot 1.5.9 + Mysql +Redis + RabbitMQ
所有的业务模块的应用服务都部署在同一个服务器,且单实例部署,服务器配置4核32G,
Redis和RabbitMQ也是单实例部署在另一个服务器;
MySQL不是在另一个服务器;
二. 原因分析:
自己所负责的data模块这两天OOM较多,导致服务重启;
data服务主要业务是报表相关,数仓对接的业务以及多个外部数据相关的小程序的后台,与数据库的交互比较多,业务逻辑相对其他模块较为简单,
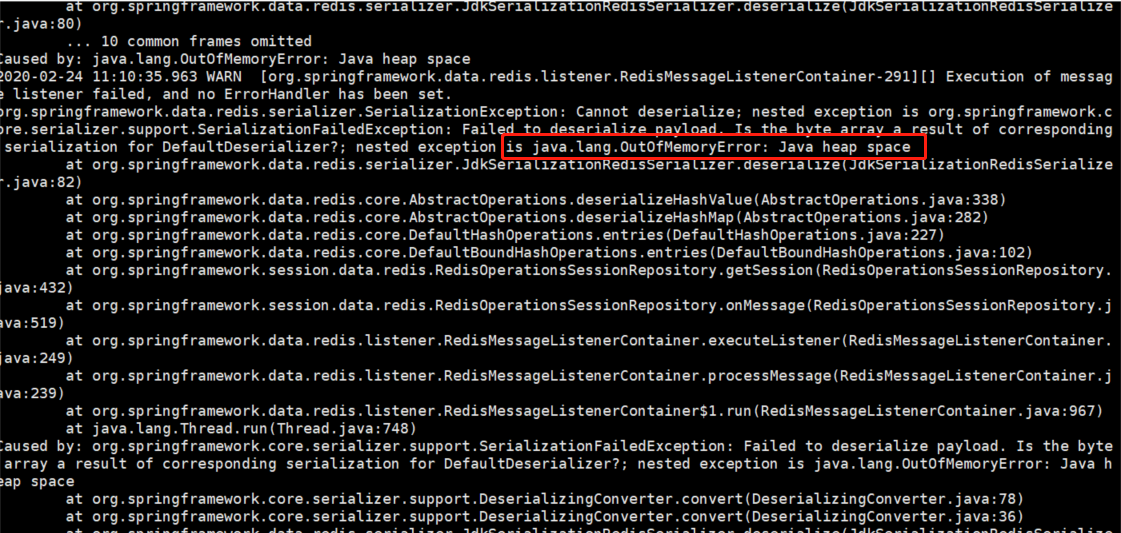
第一次:2月25日OOM情况:
由于Redis反序列化失败导致的OOM
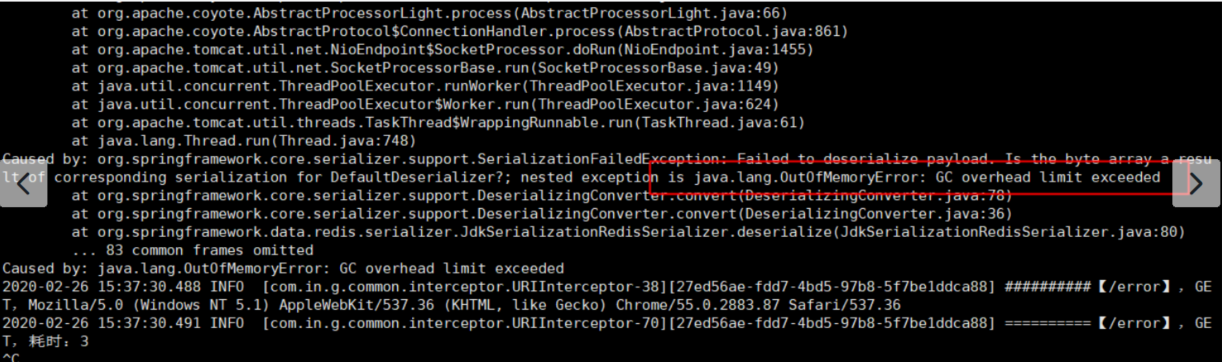
第二次:2月26日的OOM情况:
由于GC无法回收对象导致
第一次发生OOM时,觉得可能就是由于Redis序列化器和反序列化器不一致,原有的JVM参数仅设置时-Xmx:512m -Xms:512m, 老年代:年轻代=2:1 ,老年代大概分配有300M内存
时候排查问题时,发现Redis的使用都是用自己用RedisTemplate封装的工具类,按道理说不会出现什么问题,并未过多关注;
第二次发生OOM时,与第一次相距的时间仅为1天,当时就觉得问题不对了,
1.首先使用jmap -histo:live pid 查看 服务内存活的对象,发现 [C 类型的数组和ConcurrentHashMap对象都存活较多;
检查代码后发现并未有显示的使用该两类类型,怀疑时String字符串过多导致的;
2.其次使用JDK自带的分析工具:jmap -dump:format=b,file=文件名 [pid] 导出OOM时的dump日志;
导出时间非常慢,且占用线上系统的CPU,导致CPU达到100%
3.使用jstat -gc pid /jstat -gcutil pid 查看gc的状况
发现gc和fgc的都非常多,特别是fgc已经达到1000多次;

最后仍然是重启服务,-添加参数Xmx1024m -Xms:1024m
然后添加JVM参数(使用jinfo -flag可以在生产环境上直接添加)
jinfo -flag +HeapDumpBeforeFullGC pid
jinfo -flag +HeapDumpAfterFullGC pid
jinfo -flag +HeapDumpOnOutOfMemoryError pid
jinfo -flag +HeapDumpPath=/home/xxx/xxx pid 添加dump日志的目录(需要提前建好)
jinfo -flag -XX:+PrintGCDetails pid 开启gc日志
jinfo -flag -XX:+PrintGCDateStamps -Xloggc:/xxx/xxx 设置gc日志的目录
修改完成后第二天根据fgc产生的dump日志,加载到jvisualVM里面之后发现也是[C占用内存较多
下午 2点左右,监控线上服务时发现Old老年代的内存占用为300M,总大小为700M,经过一次FGC之后占用70M,这就比较正常了;但是最终原因还是没找到,
可能还要分析一下gc日志,分析具体原因,目前看到加大内存是最有效的方法;