最近在系统学习文本分类领域的论文,刚读完第一篇2014年Yoon Kim的文章textcnn,下面记录的是对textcnn的论文的一些重要部分的阅读笔记。
论文链接:Convolutional Neural Networks for Sentence Classification
1 文章的主要贡献
(1)提出了用于文本分类的卷积神经网络textcnn
(2)验证了使用预训练的词向量比使用随机初始化的词向量能获得更好的效果,而使用预训练的词向量初始化,并在具体任务中进行词向量的fine-tuning可能会得到更好的效果
2 textcnn的网络结构
论文提出的textcnn的网络结构如下:
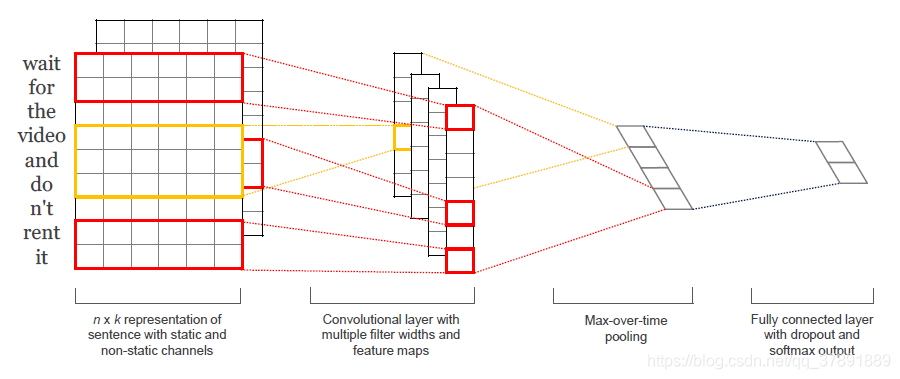
textcnn由Embedding层,卷积层,池化层以及全连接层组成
Embedding层
Embedding层的作用是将输入的词由one-hot形式转化为密集词向量形式,可以使用参数随机初始化的方式或者直接使用word2vec等预训练好的参数。
论文的目的是对句子进行分类,首先将句子分词后通过Embedding层将词转化为词向量(常用的词向量维度为300,即一个词经过Embedding层后转化为1x300的向量),然后词按照次序从上往下排列,构成一个二维的矩阵。为了使得二维矩阵尺寸一致,论文规定输入句子的词数为n,当句子词数小于n时进行填充处理。得到的二维矩阵的尺寸为n x k(n为句子分词后的词数,k为词向量的维度)
卷积层
论文使用的卷积核尺寸为h x k(h表示了卷积核窗口包含的词的个数,k为词向量的维度),为了获取多尺度特征,论文使用了卷积核数量为100,h大小为3,4,5三种尺寸的卷积提取特征,得到了300通道的特征图。
池化层
论文采用max-pooling对特征图的每一个通道取最大值,即300通道的特征图经过池化层后转化为300个值
全连接层
最后加上一个神经元个数为类别数的全连接层,后面接着softmax函数得到概率分布,并在倒数第二层使用了dropout防止过拟合,值为0.5。
论文使用的激活函数为relu,batch_size为50,优化器为Adadelta。
3 实验部分
论文重点对4种使用不同形式的词向量的模型进行了对比实验
(1)CNN-rand:词向量使用随机初始化的方式,在训练过程中学习词向量
(2)CNN-static:使用word2vec预训练好的词向量(该预训练词向量是Mikolov在2013年开源的,训练预料为100 bilion words的google news),并在训练过程中不更新词向量
(3) CNN-non-static: 使用word2vec预训练好的词向量初始化,并在训练中更新词向量
(4) CNN-multichannel:使用两个通道的词向量,一个通道为预训练好的词向量并在训练中不更新,另一个使用预训练的词向量初始化并在训练中更新。后面的卷积同时对两通道进行特征提取。
实验结果为:
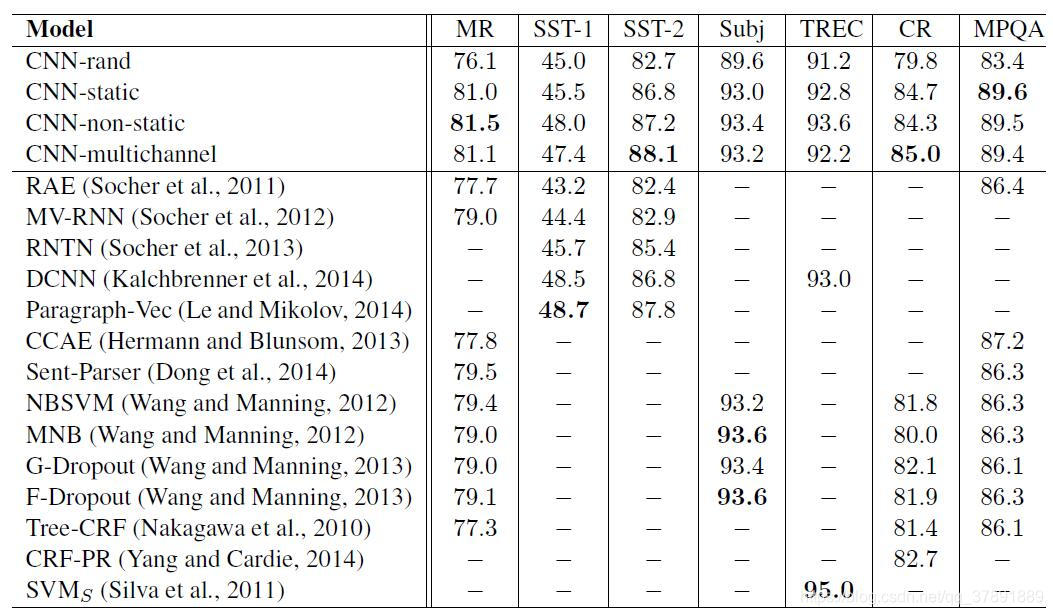
实验结论:
使用预训练的词向量(在训练过程中不更新)的效果比使用随机初始化并在训练中更新的词向量的效果好很多,而使用预训练的词向量初始化,并在训练中更新也可能会继续提高效果。
之后会更新和讲解textcnn的具体代码实现哦~
