最近压测一项目,遇到的性能问题比较典型,过程记录下来,给大家做定位调优参考;
表象:
单接口负载测试,qps最高到300,响应时间200ms,应用cpu达到90%以上,8c机器,如下图,写到这里可能有部分同学就想说:处理能力还可以,不行就加机器,扩节点!

当然这是一种解决方案,但我认为如果直接这么去做,这是一种最low的方案,而且并不能发现本质问题;回到刚刚说的,我仅仅描述了应用服务器的状态,从完整的性能测试来看,整个链路各个指标都需要监控,把链路撸了一遍之后,应用到数据层流量也是较大的如下图(请不要说扩带宽)
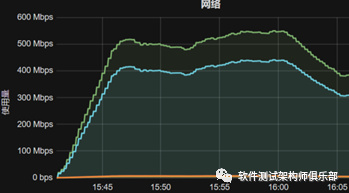
从监控中发现了这两个问题,继续看应用cpu,查看部署细节,该服务器部署了约10个docker节点,查看各个docker节点状态,其中一台达到623.59%(*核数)如图,

找到排查重点,进入相关容器,jstat查看gc状态,ygc可以达到1s三次,也是可以的,刚刚还说了啥,流量,Iftop后发现主要集中在应用跟redis服务器交互,从上面描述看,我们可以总结应用获取到redis大量的数据,导致流量较高,且大量数据会频繁的ygc会导致应用cpu的飙升,这么解释没毛病,道理上是通的,但这只是你的猜测,还要去做进一步验证,说了大量数据,那是什么业务的数据,在不做代码走读的情况下,我一般就dump,获取cpu消耗热点方法,dump到文件中发现用户信息中带大量优惠券的jedis方法(如图),
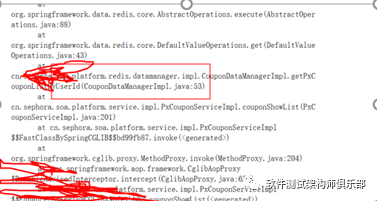
ok,到了这一步问题基本就已经很明朗了,跟开发确认后,确实业务层面获取了大量无效优惠券信息导致,开发进行业务层过滤后,qps达到1500,网络,cpu回归正常。
更多交流关注公众号:猿桌派