模块导入方法
1、import 语句
import module1[,module2[,...moduleN]]
当我们使用import语句的时候,Python解释器是怎么找到对应对文件对呢?
答案是解释器有自己的搜索路径,存在sys.path里
2、form ...import 语句
from modname import name1[,name2,[,...nameN]]
3、from...import *
from...import *
注意:
使用impor会执行下面的动作
1、执行对应文件
2、引入变量名
引用多个模块时,可以用逗号隔开
例子:


def add(x,y): return x+y def sub(x,y): return x-y
引入该模块有下面的写法
import cal from cal import add from cal import sub from cal import * #引入所有,不推荐
例子:
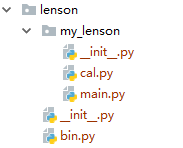
import cal def run(): print(cal.add(3,7))
from my_lenson import main main.run()
结果:
执行bin.py文件报错,找不到模块名cal。main.py中的模块引用应改成 from my_lenson import cal
另一种方式是把路径添加到sys.path列表中。
引入的路径只认执行文件的路径。执行bin文件程序会把..\lenson添加到sys.path列表中。能通过头部模块引用找到my_lenson下的main文件,但是main文件中代码import cal只能在路径..\lenson中找所以找不到。
#补充
import sys
sys.path.append() 只是做临时修改,永久修改在系统的环境变量里操作。
例子:
如果目录结构为web\web1\web2\cal.py,要调用cal中的cal函数,写法
from web.web1.web2 import cal print(cal.add(2,5)) from web.web1.web2.cal import add print(add(2,6)) from web.web1 import web2 #引用都会执行web,web1,web2的__init__文件,唯一不支持的调用方式 print(web2.cal.add(2,5)) #报错
补充:
print(__name__)在执行文件的执行结果是__main__;在调用文件的执行结果是显示文件名。
if __name__=="__main__":#调试的时候可以使用:执行的时候会执行,引用的时候不会执行
功能1:用于被调用函数的测试
功能2:不让其他人随意执行自己的程序
如果我们是直接执行某个.py文件的时候,该文件中"__name__=='__main__'"是true,但是我们如果从另一个.py文件通过import导入该文件对时候,这时__name__的值是这个py文件名字而不是__main__。结果是false所以不会运行下面的代码。
调试代码的时候,在"if __name__=='__main__'"中加入一些我们的调试代码,我们可以让外部模块调用的时候不执行我们的调试代码,但是如果我们想排查问题的时候,直接执行该模块文件,调试代码能够正常执行
补充:
执行bin,调用my_lenson下的main
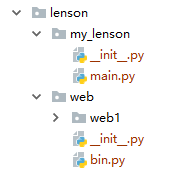
有这三种写法:
import sys,os #方式一 sys.path.append(r"D:\PycharmProjects\test1\lenson") #写死的。不推荐 #方式二 BASE_DIR=os.path.dirname(os.path.dirname(__file__))#pycharm可以,在终端下执行不行.__file__只能得到文件名 sys.path.append(BASE_DIR) #方式三 BASE_DIR=os.path.dirname(os.path.dirname(os.path.abspath(__file__))) sys.path.append(BASE_DIR) from my_lenson import main main.run()
time时间模块
1、time模块时间的格式转化
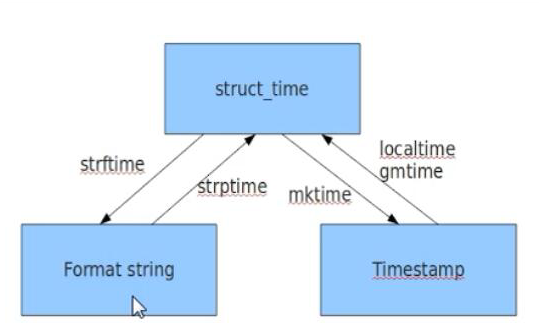
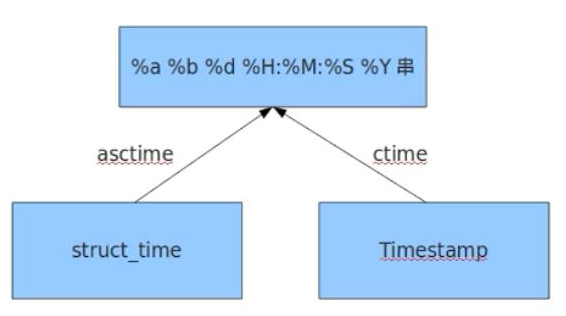
import time #时间戳 print(time.time()) #1970年1月1日。到现在经过的秒数 print(time.localtime()) #结构化时间对象,当地时间 #默认相当于localtime(time.time()) t=time.localtime() print(t.tm_year) print(t.tm_wday) #一周的第几天 print(time.gmtime()) #标准时间UTC,世界统一时间。 #=====时间格式的转化===== #结构化时间转化成时间戳 print(time.mktime(time.localtime())) #将结构化时间转化成字符串时间 print(time.strftime("%Y-%m-%d %X",time.localtime())) #%X表示时分秒 #将字符串时间转化成结构化时间 print(time.strptime("2016:12:24:15:50:36","%Y:%m:%d:%X")) #=========将时间格式转化成一种一种固定好的格式=========== #将结构化时间转化成一种固定好的时间格式 #默认是转化的当前时间 print(time.asctime()) #显示格式为:Wed Feb 12 18:24:02 2020 #将时间戳转化成一种固定好的时间格式 print(time.ctime()) #显示格式为:Wed Feb 12 18:24:02 2020
2、其他方法
sleep():
clock() #不常用,在win系统中指时间差
*time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
3、datetime模块
import datetime print(datetime.datetime.now())#2020-02-12 18:32:05.267959
random模块
import random ret=random.random() #(0,1)--float print(ret) print(random.randint(1,3)) #[1,2,3] print(random.randrange(1,3))#[1,3),不含3 print(random.choice([1,'23',[4,5]]))#从列表里随机取值 print(random.sample([11,22,33,44],2))#随机选2个,结果是列表 print(random.uniform(1,4)) #1到4的浮点数 ret=[1,2,3,4,5] random.shuffle(ret) print(ret) #把顺序打乱的一个列表 [1, 3, 5, 2, 4]
例子:生成一个随机验证码
def v_code(): ret='' for i in range(5): num=random.randint(0,9) alf=chr(random.randint(65,122)) s=str(random.choice([num,alf])) ret+=s return ret print(v_code())
os模块
import os
print(os.getcwd()) #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("lenson")# 改变当前脚本工作目录,相当于shell下cd print(os.curdir) #返回当前目录:("."),不常用 print(os.pardir) #获取当前目录的父目录字符串名:("..") ,不常用 os.makedirs("dirname1/dirname2") #可生成多层递归目录 os.removedirs(r"D:\PycharmProjects\test1\lenson\dirname1\dirname2") #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依次类推 os.mkdir("dirname") #生成单级目录;相当于shell中mkdir dirname os.rmdir(r"D:\PycharmProjects\test1\lenson\dirname1\dirname2") #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname print(os.listdir(r"D:\PycharmProjects\test1\lenson")) #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() #删除一个文件 os.rename("oldname","newname") #重命名文件/目录 print(os.stat(r"D:\PycharmProjects\test1\lenson\bin.py"))#获取文件/目录信息,大小,修改时间等 os.sep #输出操作系统特定的路径分割符,win下为"\\",linux下为"/" print(os.linesep) #输出当前平台的行终止符,win 下为"\r\n",linux下为"\n" print(os.pathsep) #输出用于分割文件路径的字符串 win下为;,linux下为: print(os.name) #输出字符串指示当前使用平台。win->"nt";linux->"posix" ,不常用 os.system("bash command") #运行shell命令,直接显示,不常用 print(os.environ)# 获取系统环境变量,不常用 os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) #返回path最后的文件名。如果path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exist(path) #如果path存在,返回true;不存在返回false os.path.isabs(path) #如果path是绝对路径,返回true os.path.isfile(path) #如果path是一个存在的文件,返回true,否则返回false os.path.isdir(path) #如果path是一个存在的目录,则返回true,否则返回false os.path.join(path1[,path2[,...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
sys模块
sys.argv 命令行参数list,第一个元素是程序本身路径 #sys.argv[1],sys.argv[2]。显示传的参数。比如上传下载的时候可以使用。 sys.exit(n) 退出程序,正常退出时exit(0) sys.version 获取python解释程序的版本信息 sys.maxint() 最大Int值 sys.path 返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值 sys.platform 返回操作系统平台名称
例子:进度条显示
import time for i in range(100): sys.stdout.write("#") #向屏幕显示对应的内容。print是以此为基础的。 time.sleep(0.2) sys.stdout.flush() #程序通过sys的接口把要输出的内容放在了缓存里,最后才显示到终端,所以加个刷新。
json&pickle模块
之前讲用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
如:
import json x="[null,true,false,1]" print(eval(x)) #报错 print(json.loads(x))
方法:
json.dumps() 转化成字符串,封装成json格式的字符串
json.loads()
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
序列化之后,就可以把序列化后的内容写入磁盘,或者通过网络传输到别的机器上。
反过来,把变量内容从序列化的对象重新读到内存里称之为反序列化,即unpickling。
json
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下
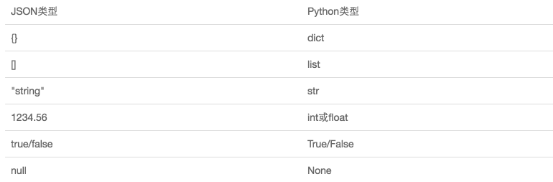
import json ''' dic={'name':'jobs'} #-->{"name":"jobs"}-->'{"name":"jobs"}' i=8 #-->'8' s='hello' #-->"hello"-->'"hello"' l=[11,22] #-->"[11,22]" ''' #------序列化----- dic={'name':'jobs'} f=open("序列化对象","w") dic_str=json.dumps(dic) #转化成json格式的字符串,如上的形式,单引号会变成双引号 f.write(dic_str) #----等价于json.dump(dic,f) f.close() #------反序列化----- import json f=open("序列化对象") data=json.loads(f.read()) #---等价于data=json.load(f)
注意:无论数据是怎样创建的,只要满足json格式,就可以json.loads出来,不一定非要dumps的数据才能loads
import json # dct="{'a':'111'}" #报错,json不认单引号 # dct=str({"a":"111"}) #报错,因为生成的数据还是单引号 dct='{"a":"111"}' print(json.loads(dct))
pickle
#pickle与json在使用上是完全一致的。pickle在序列化处理成字节bytes。json是处理成字符串str
#pickle支持的数据类型更多。类,函数。但是用处需求少很少用。
如:
import pickle #------序列化----- dic={'name':'jobs'} f=open("序列化对象","wb") #注意是w是写入str,wb是写入bytes dic_p=pickle.dumps(dic) #dic_p是'bytes' f.write(dic_str) #----等价于pickle.dump(dic,f) f.close() #------反序列化----- import pickle f=open("序列化对象","rb") data=pickle.loads(f.read()) #---等价于data=pickle.load(f)
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型
import shelve f=shelve.open(r'shelve') #目的:将一个字典放入文本 f['stu1_info']={'name':'steven','age':'18'} f['stu2_info']={'name':'job','age':'20'} f.close() print(f.get('stu1_info')['age']) #反序列化
xml模块
xml是实现不同语言或程序之间进行数据交换的协议,跟json差不多,但json使用起来更简单,不过,古时候,在json还没诞生的黑暗年代,大家只能选择用xml呀,至今很多传统公司如金融行业的很多系统的接口还主要是xml。
xml的格式如下,就是通过<>节点来区别数据结构的:
import xml.etree.ElementTree as ET tree=ET.parse(r"C:\Users\Administrator\Desktop\test.xml") root=tree.getroot() print(root.tag) #----遍历----- for child in root: print(child.tag,child.attrib) for i in child: print(i.tag,i.text) #----只遍历某个节点---- for node in root.iter('year'): print(node.tag,node.attrib) #----修改---- for node in root.iter('year'): new_year=int(node.text)+1 node.text=str(new_year) node.set("updated","yes") tree.write("abc.xml") #-----删除---- for country in root.findall("country"): rank=int(country.find("rank").text) if rank > 50: root.remove(country) tree.write("output.xml") #-----创建----- import xml.etree.ElementTree as ET new_xml=ET.Element("data") country=ET.SubElement(new_xml,"country",attrib={"name":"American"}) rank=ET.SubElement(country,"rank") rank.text='2' year=ET.SubElement(country,"year",attrib={"checked":"no"}) year.text='200' country=ET.SubElement(new_xml,"country",attrib={"name":"china"}) rank=ET.SubElement(country,"rank") rank.text='2' year=ET.SubElement(country,"year",attrib={"checked":"yes"}) year.text='5200' et=ET.ElementTree(new_xml) #生成文档对象 et.write("test.xml",encoding="utf-8",xml_declaration=True) ET.dump(new_xml)
re模块
本质而言,正则表达式(或 RE)是一种小型的、高度专业化的编程语言,(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
字符匹配(普通字符,元字符):
1 普通字符:大多数字符和字母都会和自身匹配
>>> re.findall('jobs','yuanaleSxjobszhoumo')
['jobs']
2 元字符:. ^ $ * + ? { } [ ] | ( ) \
import re #.:通配符,什么都能匹配,除了换行符 re.findall("a..x","adsfaeexkksdjfis") #^:表示以什么开头 re.findall("^a..x","adsxfajdkfjkadfjka") #匹配以a开头。。。 #$:表示以什么结尾 re.findall("a..x$","adfakfjakfjasix")#匹配结尾是x #*+{}? 可以匹配重复 #*:表示0到无穷次 #+:1到无穷次 re.findall("^d*","ddddfajdfkajdfk") re.findall("seex*","asdkfafdaseexxx") re.findall("seex+","asdkfafdaseexxx") re.findall("seex*","asdkfafdseele")#0次能匹配上 ['see'] re.findall("seex+","asdkfafdseele")#不能匹配上 #?:表示0或1次 #{};表示自己定义次数 ''' {0,} == * {1,} == + {0,1}== ? {6} 表示匹配重复6次 {1,6} 表示重复1到6次 '''
注意:
前面的*,+,?等都是贪婪匹配,也就是尽可能匹配,后面加?使其变成惰性匹配
ret=re.findall("abc*?","abcccc") print(ret)#["ab"]
3 字符集[]
#[]:字符集 - ^ \这三个字符有特殊意义,^在里面表示非。 re.findall("a[bc]","abccc") #['ab'] re.findall("q[a-z]","akjdkfqba")#["qb"] 中括号里只有-有特殊意义。 表示a-z任一字符 re.findall("q[a*z]","adkfjakqadkq*kk")#["qa",q*] 这里的*没有特殊意思。 re.findall("q[a-z]*","qdfjakdjka")#["qdfjakdjka"] re.findall("q[a-z]*","qdfjakdjka877")#["qdfjakdjka"] re.findall("q[0-9]*","q38423fkafdkfjq")#["q38423","q"] re.findall("q[^a-z]","q38djffjk")#["q38"]
4 元字符之转义符\
反斜杠后边跟元字符去除特殊功能,比如\.
反斜杠后边跟普通字符实现特殊功能,比如\d
\d 匹配任何十进制数;相当于类[0-9]
\D 匹配任何非数字字符;相当于类[^0-9]
\s 匹配任何空白字符;相当于类[\t\n\r\f\v]
\S 匹配任何非空白字符;相当于类[^\t\n\r\f\v]
\w 匹配任何字母数字字符;相当于类[a-zA-Z0-9_]
\W 匹配任何非字母数字字符;相当于类[^a-zA-Z0-9_]
\b 匹配一个特殊字符边界,比如空格,&,#等
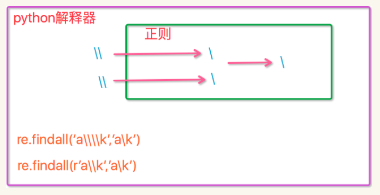
print(re.findall("I\b","hello I am LIST")) #匹配不上,因为\b在ASCII表中是有意义的 print(re.findall(r"I\b","hello I am LIST"))#加r表示字符串不做转义 ['I'] print(re.findall("I\\b","hello I am LIST"))#['I'] print(re.findall("c\\\\l","abc\lerwt")) #['c\\l']
5元字符()分组
import re re.findall(r"(ab)+","abccc") #['ab'],未命名的分组 re.search("(?P<name>\w+)","abcccc") #获得一个匹配的对象,命名的分组 re.search("(?P<name>\w+)","abcccc").group()#'abcccc' #?P是固定的,这个方式可以将匹配的结果赋给一个变量。用于在匹配的结果较多时获取想要的特定值,如下 re.search("(?P<name>[a-z]+)(?P<age>\d+)","steven33jobs22smile45").group("name")#'steven' re.search("(?P<name>[a-z]+)(?P<age>\d+)","steven33jobs22smile45").group("age")#'33'
注意
#有分组时,匹配的结果会优先返回分组里匹配的内容
re.findall("www\.(baidu|hao123)\.com","www.baidu.com")#['baidu']
#想要匹配的内容,用?:取消权限即可
re.findall("www\.(?:baidu|hao123)\.com","www.baidu.com")#['www.baidu.com']
6元字符|或
ret=re.search('(ab)|\d','rabhdg8sd') print(ret.group())#ab
7、re模块常用方法
import re #1.findall re.findall('a','alvin yuan') #返回所有满足匹配条件的结果,放在列表里 #2.search re.search('a','alvin yuan').group() #函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以 #通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。 #3.match re.match("a","abc").group() #同search类似,但是是在字符串开头处进行匹配 #4.split re.split(" ","hello abc def") re.split("[ |]","hello abc|def")#['hello', 'abc', 'def'] re.split("[ab]","abc") #['', '', 'c'] 先按a分得到""和"bc",再对""和"bc"按b分割 re.split("[ab]","asdabcd") #['', 'sd', '', 'cd'] #5.sub 替换 re.sub("\d+","A","dafj12dkf345kj88")#'dafjAdkfAkjA' 将匹配的结果用第二个参数替换 re.sub("\d+","A","dafj12dkf345kj88",2)#'dafjAdkfAkj88' 第四个参数为最多匹配替换的次数 re.subn("\d+","A","dafj12dkf345kj88")#('dafjAdkfAkjA', 3) 获取替换后的结果和次数 #6.compile com=re.compile("\d+") com.findall("qwe232iieu2123iii666")#['232', '2123', '666'] #7.finditer 把结果放在迭代器里面 ret=re.finditer("\d","dadf873kiiue887") print(ret)#<callable_iterator object at 0x0399D0B0> print(next(ret).group())#8 print(next(ret).group())#7
logging模块
一、简单应用
import logging logging.debug("debug message") logging.info("info message") logging.warning("warning message") logging.error("error message") logging.critical("critical message")
结果为:

结论:
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG > NOTSET),
默认的日志格式为:日志级别:Logger名称:用户输出消息。
二、灵活配置
import logging logging.basicConfig( level=logging.DEBUG,#配置日志的级别 filename="logger.log", #输出到制定文件中 filemode="w",#写文件的方式 format="%(asctime)s %(filename)s[%(lineno)d] %(message)s" ) #logger对象 logger=logging.getLogger() fh=logging.FileHandler("test_log") #配置输出到文件句柄 ch=logging.StreamHandler() #配置输出到控制台 fm=logging.Formatter("%(asctime)s %(message)s") fh.setFormatter(fm) ch.setFormatter(fm) logger.addHandler(fh) logger.addHandler(ch) logger.setLevel("DEBUG") logger.debug("debug") logger.info("hello") logger.warning("warning") logger.error("error") logger.critical("critical")
注意1:如果用logger1=logging.getLogger("mylogger")创建。相当于创建了一个root下的子用户mylogger。并且是唯一的。
再创建一个同名的用户指向的是同一个对象。logger1=logging.getLogger("mylogger.sontree")创建子用户的子用户
注意2:logger=logging.getLogger();logger1=logging.getLogger("mylogger")
子对象和父对象都存在并且都在输出时。子对象会多输出一次。每向上多一个层级多输出一次。
configparser模块
配置解析
import configparser config=configparser.ConfigParser() #config={} config["DEFAULT"]={'ServerAliveInterval':"45", "Compression":"yes", "CompressionLevel":"9" } config["bitbucket.org"]={} config["bitbucket.org"]["User"]="hg" config["topsecret.server.com"]={} topsecret=config["topsecret.server.com"] topsecret["Host Port"]="50022" topsecret["ForwardX11"]="no" config["DEFAULT"]["ForwardX11"]="yes" with open("example.ini","w") as configfile: config.write(configfile)
结果:
[DEFAULT] serveraliveinterval = 45 compression = yes compressionlevel = 9 forwardx11 = yes [bitbucket.org] user = hg [topsecret.server.com] host port = 50022 forwardx11 = no
增删改查
#----查询---- import configparser config=configparser.ConfigParser() config.read("example.ini") print(config.sections())#['bitbucket.org', 'topsecret.server.com'] print('bitbucket.org' in config)#True print(config["bitbucket.org"]["User"])#hg
for key in config["topsecret.server.com"]:#遍历下面的键,结果会包含了默认[DEFAULT]下面的键。 print(key)
print(config.options("bitbucket.org"))#['user', 'serveraliveinterval', 'compression', 'compressionlevel', 'forwardx11'].显示所有的键同上,但是以列表的形式 print(config.items("bitbucket.org"))#[('serveraliveinterval', '45'), ('compression', 'yes'), ('compressionlevel', '9'), ('forwardx11', 'yes'), ('user', 'hg')] #把键和值组成元祖的形式显示 print(config.get("bitbucket.org","compression"))#yes #----删改增---- config.add_section("yuan") #增加一个块 config.set("yuan","k1","11111")#增加块下面的一个键值对 config.remove_section("yuan") #删除一个块 config.remove_option("yuan","k1")#删除块下面的键值对 config.write(open("example.ini","w"))
hashlib 模块
用于加密相关的操作,3.x里代替了md5模块和sha模块,主要提供SHA1,SHA224,SHA256,SHA384,SHA512,MD5算法
import hashlib obj=hashlib.md5()#可以用其他加密算法等 obj=hashlib.sha256() obj.update("hello".encode("utf8")) print(obj.hexdigest()) #5d41402abc4b2a76b9719d911017c592 把不定长的字符串转换成定长的秘文 obj.update("admin".encode("utf8"))#只执行admin的加密,结果为:21232f297a57a5a743894a0e4a801fc3 print(obj.hexdigest()) #执行上面"hello"加密和"admin"加密,相当于对"helloadmin加密",结果为:dbba06b11d94596b7169d83fed72e61b
以上加密算法虽然依然非常厉害,但也有存在缺陷,即:通过撞库可以反解。所以,有必要对加密算法中添加自定义key再来做加密
import hashlib hash=hashlib.sha256("23192idfaljfie82".encode("utf8")) hash.update("alvin".encode("utf8")) print(hash.hexdigest())#ea1936a49f75518528fe0f2a60a412b8ff89360bcfe882ff4290bac45fbd26fa
python还有一个hmac模块,它内部对我们创建key和内容再进行处理然后再加密:
import hmac h=hmac.new("alvin".encode("utf8")) h.update("hello".encode("utf8")) print(h.hexdigest())#320df9832eab4c038b6c1d7ed73a5940