在图像处理相关的代码中,我们经常有类似于以下的代码,去遍历多维数组(张量)的每一个元素:
#define LENGTH 10000
void proc(){
uint8 datas[LENGTH][LENGTH];
int i, j;
long long sum = 0;
for (i = 0; i < LENGTH; i++){
for (j = 0; j < LENGTH; j++){
sum += datas[i][j];
}
}
}
其中的sum += datas[i][j];从语义上是和sum += datas[j][i];效果一致的,然而从性能上来说是否是一致的呢?答案是不是的,要看程序的编译优化程度。我们会发现,当循环变量处于内循环和外循环时,其性能是不一样的,即便是运算结果一致。
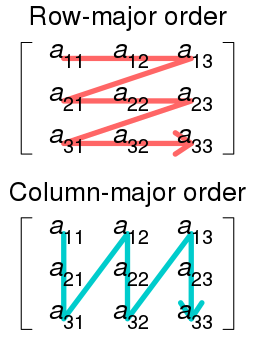
我们知道不管是一维数组还是多维数组,在内存中都是线性排列的,以二维数组为例子,为了能将二维的数组拉成一维的,一般需要考虑编译器在编译代码时,其在内存中是行优先(row-major)排列还是列优先(colum-major)排列的。如下图所示,如果一个数组是行优先排列的,那么其在连续内存上的排列顺序如红色线的顺序。举个例子,比如现在有个数组int vars[3][3],如果是行优先排列的,那么有:(===的意思是等价, (vars+i)表示对以vars作为数组指针的前提下,偏移i个元素的地址,而*(vars+i)是对其进行取内容。)
vars[0, 0] === *(vars+0);
vars[0, 1] === *(vars+1);
vars[1, 0] === *(vars+3);
==>
vars[i, j] === *(vars+3*i+j)
如果是列优先排列呢,则是
vars[0, 0] === *(vars+0);
vars[0, 1] === *(vars+1*3+1);
vars[1, 0] === *(vars+0*3+1);
==>
vars[i, j] === *(vars+3*j+i)
到这里为止都好理解,不过后续我们需要理解的一点是,我们现在跑得程序很多都不是在裸机上跑的。这里指的裸机就是没有操作系统的计算机,比如单片机等,或者是没有任何操作系统的其他CPU。在操作系统上跑程序,那么我们的程序的内存空间其实都是虚拟内存空间,是一种逻辑地址,其和物理的内存位置是没有必然关联的,需要受到操作系统的控制。采用虚拟内存有很多好处,其中最明显的就是:
- 不需要考虑不同程序之间的相对地址偏移,每个程序都有其独自的内存空间,其地址范围都是从0到系统定义的最大值
max_mem。 - 虚拟内存可以看成是一个巨大的线性内存空间,不需要考虑内存不足的情况,因为当内存不足的情况或者需要访问的数据不在内存上时,就发生了缺页错误(page fault),操作系统会自动进行“换页”(paging),将物理内存暂时不用了的内存页保存到存储空间巨大的硬盘上,然后把需要读取的内存加载到内存上。在这种情况下,可以把整个硬盘都看成是一个可以换入和切出的内存(虽然速度很慢,没法和真正的内存比)
虚拟内存的细节太多,是操作系统设计的一个主要概念,其他细节需要参考其他书籍,比如[1,2]。我们在这里需要知道的是,我们程序中随时可能遇到数据在内存中找不到的事情发生,这个时候就会发生换页的操作,从硬盘中加载数据到内存(IO操作)是非常花时间的,因此很多程序的瓶颈都会在此。我们这里的关键点也正是在此。
在一个以行优先排序的编译器上,每一行的数据在内存地址上都是比较接近的,而列数据的地址总是相差着sizeof(data_type) * N,其中
是每一行的元素数量。这就导致每一行的数据可能是处于同一个内存页帧(page frame)上的,而每一个列的数据处于不同的页帧上。在以行优先排序的编译器上,如果外循环是列索引,内循环是行索引,有可能会发生频繁地进行缺页,换页的操作(准确地说是n*m次),严重影响程序的性能。当然,这里只是可能,具体情况和你的数组大小,系统的页大小设置等有关。(这里的缺页特别在物理内存比较小的时候更为严重)
这里举个代码例子,说明性能上的差别。
考虑代码:
# code 1
#define LENGTH 20000
int main(){
float vector[LENGTH][LENGTH];
int i, j;
float sum = 0.0f;
for (i = 0; i < LENGTH; i++){
for (j = 0; j < LENGTH; j++){
sum += datas[i][j];
}
}
return 0;
}
# code 2
#define LENGTH 20000
int main(){
float vector[LENGTH][LENGTH];
int i, j;
float sum = 0.0f;
for (i = 0; i < LENGTH; i++){
for (j = 0; j < LENGTH; j++){
sum += datas[j][i];
}
}
return 0;
}
这两个代码除了索引的顺序不同(相当于内外循环调换)之外,其他别无差别。我们为了防止编译器对代码进行优化,影响分析,我们采用-O0编译参数以去掉任何gcc的优化。(其实用其他优化等级效果也是类似的,读者可以自行尝试,并且用指令gcc -O0 -S code1.c观察分析其汇编代码。)
gcc -O0 code1.c
/usr/bin/time -v ./a.out
我们用/usr/bin/time分析程序的运行时间,我们有这两者的运行时间分别为:
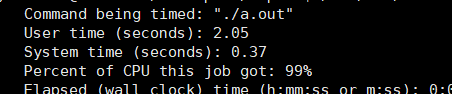
code 1的运行时间为2.05s

而code 2的时间则变成了5.68s,性能明显差code 1很多。
但是如果我们把数组的大小从20000改成200会怎么样呢?我们发现其性能将不会有明显区别了,就是因为尺寸大小的不同影响了页帧的换页过程。
Reference
[1]. Bryant R E, David Richard O H, David Richard O H. Computer systems: a programmer’s perspective[M]. Upper Saddle River: Prentice Hall, 2003.
[2]. Tanenbaum A S. Structured computer organization[M]. Pearson Education India, 2016.
