HashMap结构及存储原理
- 数组的机制是存储连续,所以空间复杂度很高。表现出来就是插入,删除很慢但是查询很快
- 链表的机制是存储分散,所以空间复杂度很小。表现出来就是插入,删除很快但是查询不快
在这里解释一种最常用的方法:拉链法
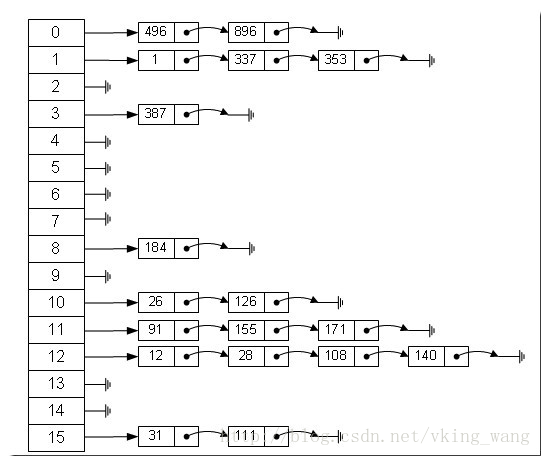
如图所示,
纵向的0,1,2,3,4..表示的是数组,
横向的则是链表结构用于存储entry键值对
例如这是一个长度为16的数组,键值对将根据
hash(key)%len进行分组划分到纵向的数组之中去,比如上述哈希表中,12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在数组下标为12的位置。HashMap的基础就是一个线性数组,即Entry []数组。其中null统一放在第一个链表中

那么当多个hash(key)%Entry[].length的值相同,Entry[]中应该怎么存放呢?例如当键值对A的index=0,这时候又一个键值对B的index也为0。那么存放的键值对Entry[0]存放的为B,并且设置B.next=A,后面的键值对以此类推,形成链表结构。若不同key的 hascode相同,可以通过存储格式为entry的(key,value)格式来获取值,但是会降低效率
HashSet和HashMap
对于 HashSet 而言,系统采用 Hash 算法决定集合元素的存储位置,这样可以保证能快速存、取集合元素;对于 HashMap 而言,系统 key-value 当成一个整体进行处理,系统总是根据 Hash 算法来计算 key-value 的存储位置,这样可以保证能快速存、取 Map 的 key-value 对。