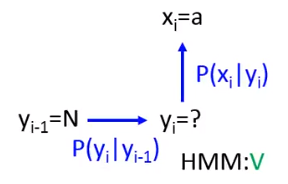来看看定义(这里的定义其实并不严格,先暂时假定输入和输出的Sequence的长度都是相等的,为L,实际上有很多种情况,其实在前面的课程有讲过): RNN can handle this task, but there are other methods based on structured learning(two steps, three problems). 典型应用: •Name entity recognition • Identifying names of people, places, organizations, etc. from a sentence • Harry Potter is a student of Hogwarts and lived on Privet Drive. 识别结果: people: Harry Potter organizations: Hogwarts places: Privet Drive not a name entity: 其他部分 但是对于中文的抽取很麻烦,例如下面两句要抽取人名: 楊公再興之神(出自金庸《笑傲江湖》) 馮氏埋香之塚(出自金庸《射雕英雄传》) 下面来看例子
Example Task: POS tagging
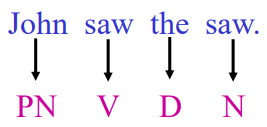
Annotate each word in a sentence with a part-of-speech.输入一个句子,输出每个词的类型,例如名词,动词什么的。 Useful for subsequent syntactic parsing and word sense disambiguation, etc. 下面是一个小例子,看到都是saw,有不一样的词性。 这个看起来很简单的东西,明显是不可以直接把词和词性保存下来,然后直接做简单的查询就行了。 “saw” is more likely to be a verb V rather than a noun N,为什么会知道第二个saw是名词呢?因为它在the后面 the second “saw” is a noun N because a noun N is more likely to follow a determiner. 也就是说词性和词序有很大关系。下面就将考虑词序的structed learning的技术依次介绍。
Hidden Markov Model (HMM)
先来看看人是如何构造一个句子: Step 1 • Generate a POS sequence • Based on the grammar Step 2 • Generate a sentence based on the POS sequence • Based on a dictionary 这实际上和HMM假设是一样的。
HMM – Step 1
根据脑中的语法建立一个POS的sequence: 实际上这就是一个马尔科夫链,例如: 要说一句话,放在句首的0.5的几率是冠词,0.4的几率是专有名词,0.1的几率是动词 这里随机sample一下,假设第一个词是专有名词PN,PN后面80%几率是动词V,10%几率是冠词,10%几率直接结束。然后再随机sample一下。一直往下,直到end。 注意:每一个词后面接什么词合起来的几率应该是1,不是1就是ppt有问题。 当我们要计算"PN V D N"这样的一个序列的概率,就是上图中的式子。
•Obtaining from training data 找一堆句子,并找砖家把每个词的词性标注出来。每一个句子就是一笔training data 那么算公式1中的P(yl+1∣yl)这个就是数数: P(yl+1=s′∣yl=s)=count(s)count(s→s′) s和s′是tag(词性标签) 公式2中的P(xl∣yl) P(xl=t∣yl=s)=count(s)count(s→t) s是tag(词性标签),t是词。 讲到这里,老师解释了一下HMM在处理语音序列的时候表达式不是这样的,处理语音序列的时候,HMM里面的都是一个个搞屎分布形成的GMM,不是像这里用统计的方法算出来的,GMM要用EM来解,这里不用。为什么?老师也没说,自己想。。。 回到之前的POS tagging这个问题 现在y是不知道的,也就是为什么叫Hidden的原因,现在我们知道怎么算P(x,y)和x,要求y 用概率来说就是,在给定x的条件下出现的几率的y就是我们要求的y y=argy∈YmaxP(y∣x) 上式可以写成: y=argy∈YmaxP(x)P(x,y) 由于分母P(x)是固定的,所以上式等价于: y=argy∈YmaxP(x,y) 这个最有可能的y就是穷举所有的y,然后带入公式P(x,y)里面,然后找到最大的那个~!,我们把它记为y~ 下面来分析一下这个做法:
HMM – Viterbi Algorithm
y~=argy∈YmaxP(x,y) • Enumerate all possible y会发生什么? 假设我们有S个词性标签,sequence y长度为L,那么y的可能性就是: SL 这个玩意超大,不好算,于是有Viterbi Algorithm来解决这个问题,其算法时间复杂度为:O(L(S)2)
Viterbi-Algorithm算法 维特比算法是一个特殊但应用最广的动态规划算法。利用动态规划,可以解决任何一个图中的最短路径问题。而维特比算法是针对一个特殊的图-篱笆网了(Lattice)的有向图最短路径问题而提出来的。它之所以重要,是因为凡是使用隐马尔科夫模型描述的问题都可以用它解码,包括当前的数字通信、语音识别、机器翻译、拼音转汉字、分词等。 ———————————————— 版权声明:本文为CSDN博主「皮乾东」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。 原文链接:https://blog.csdn.net/meiqi0538/article/details/80960128
HMM - Summary
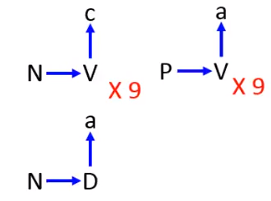
HMM的过程: HMM的缺点: 假如输入x对应的正确标签为y,根据inference,我们希望y的概率大于其他所有标签的概率: P(x,y)>P(x,y) 但是这个式子不一定成立,因为P(x,y)不一定很小,我们来看个例子: Transition probability: P(V|N)=9/10 P(D|N)=1/10 … Emission probability: P(a|V)=1/2 P(a|D)=1… 用图表示: 如下图所示,如果yl−1=N,在l时刻观察到的xl是a,那么yl最有可能是谁呢? 根据yl=P(yl∣yl−1)×P(xl∣yl) 如果放V,yl=0.9∗0.5=0.45 如果放D,yl=0.1∗1=0.1 按这个算法放V比较合适~! 现在我们来看看我们的training data是什么样子: 在training data中明显的出现的序列是:N→D→a,从来没有出现过:N→V→a,按HMM算法算出来来的序列却是:N→V→a,也就是说HMM算法只会按照概率的高低来进行估计,并不管这个序列是否出现过(HMM自己脑补了未出现过的东西)。这个脑补的过程也不能说就是个坏事 The (x,y) never seen in the training data can have large probability P(x,y). •Benefit: •When there is only little training data 由于训练数据很少,也就是意味在真实的数据中是有可能出现训练数据中没有出现过的序列的,因此HMM在训练数据很少的时候性能反而比较好。也就是说训练数据多的时候HMM的表现并没有比较好。 出现这个现象的根本原因是HMM把Transition probability和Emission probability是分开作为独立的概率来看待的,因此解决这个现象就是用更加复杂的模型,把这两个东西都考虑起来。 下面要讲的CRF就是用同样的模型,解决这个问题。
Conditional Random Field (CRF)
CRF也是要描述P(x,y),但是它描述的方式是: P(x,y)∝exp(w⋅ϕ(x,y)) ∝是正比于的意思,ϕ(x,y)是feature vector, w is a weight vector to be learned from training data, exp(w⋅ϕ(x,y)) 是一个正数,可以大于1. 下面是全概率公式出来: P(y∣x)=∑y′P(x∣y′)P(x,y)(4) 由于P(x,y)和exp(w⋅ϕ(x,y))成正比,所以: P(x,y)=Rexp(w⋅ϕ(x,y))(5) 把公式5带入4后,4中的分母互相消掉: P(y∣x)=∑y′∈Yexp(w⋅ϕ(x,y′))exp(w⋅ϕ(x,y)) 分母中是对所有的y进行求和,因此和x是相互独立的,可以把上式写成: P(y∣x)=Z(x)exp(w⋅ϕ(x,y))
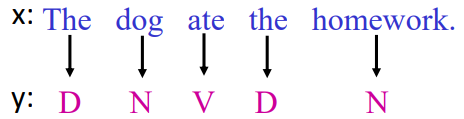
下面来看CRF的Feature Vector是什么样子,就是ϕ(x,y)这个东西。直接看例子: 假如输入输出(x,y)如下图: ϕ(x,y) has two parts Part 1: relations between tags and words(是一个vector,它的dimension为:s×t,其中s是词性标签,t是词表中所有的单词,这个vector是很sparse的) Part 2: relations between tags Ns,s′(x,y): Number of tags s and s’ consecutively in x,y 例如:下面ND,D(x,y)=0表示词性D出现在D后面在所有(x,y)中出现的次数是0. ND,N(x,y)=0表示词性D出现在D后面在所有(x,y)中出现的次数是2 这个玩意也是一个vector,他的维度为:S×S+2×S 意思是如果有S个词性,每个词性之间都会有一个组合S×S,每个S都和start有一个组合,和end有一个组合,就是2×S 最后要说的是,CRF牛叉的地方在于,这个特征向量可以不这样定义,可以自己来定义ϕ(x,y)的形式。
CRF – Training Criterion
下面来看CRF如何训练,假设我们有一组训练数据 {(x1,y1),(x2,y2),...,(xN,yN)} Find the weight vector w∗ maximizing objective function O(w): w∗=argwmaxO(w) O(w)=n=1∑NlogP(yn∣xn) 根据CRF的定义: logP(yn∣xn)=log(∑y′P(xn,y′)P(xn,yn)) log中除法变减法: 下面看梯度如何求,由于上面是求最大值,所以是梯度上升求解Gradient Ascent: Find a set of parameters θ maximizing objective function O(θ) θ→θ+η▽O(θ) 下面看具体怎么弄,先写出目标函数: O(w)=n=1∑NlogP(yn∣xn)=n=1∑NOn(w) 计算梯度 ▽On(w)=⎣⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎢⎡⋮∂ws,t∂On(w)⋮∂ws,s′∂On(w)⋮⎦⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎥⎤ 下面先看看∂ws,t∂On(w)如何计算,另外一个∂ws,s′∂On(w)是类似的,就不说了。(哭晕,具体过程在附录,没看懂,不贴过程了,上结果) ∂ws,t∂On(w)=Ns,t(xn,yn)−y′∑P(y′∣xn)Ns,t(xn,y′) 第一项:If word t is labeled by tag t in training examples (xn,yn), then increase ws,t 第二项:If word t is labeled by tag t in (xn,y′) which not in training examples, then decrease ws,t,这项也可以用Viterbi algorithm 来算 ▽O(w)=ϕ(xn,yn)−y′∑P(y′∣xn)ϕ(xn,y′) Stochastic Gradient Ascent w→w+η(ϕ(xn,yn)−y′∑P(y′∣xn)ϕ(xn,y′))
也写出三板斧: Problem 1: Evaluation F(x,y)=w⋅ϕ(x,y) 这里的ϕ(x,y)可以自定义,如果不知道咋定义,可以直接和CRF定义一样的即可 Problem 2:Inference y~=argy∈Ymaxw⋅ϕ(x,y) 这个可以Viterbi算法来解 Problem 3: Training ∀n,∀y∈Y,y=yn:w⋅ϕ(xn,yn)>w⋅ϕ(xn,y)y~n=argymaxw⋅ϕ(xn,y) w→w+ϕ(xn,yn)−ϕ(xn,y~n) 比较一下Structured Perceptron和CRF Structured Perceptron: y~n=argymaxw⋅ϕ(xn,y) w→w+ϕ(xn,yn)−ϕ(xn,y~n) CRF: w→w+η(ϕ(xn,yn)−y′∑P(y′∣xn)ϕ(xn,y′)) 如果不看CRF的学习率η,发现两个参数更新的方式很像,其中ϕ(xn,yn)这项是一样的,后面那个不一样,直接的可以理解为:Structured Perceptron直接减掉错误几率的那个y~,CRF减掉所有错误的y的加权平均和,因此我们把ϕ(xn,y~n)称为硬间隔,∑y′P(y′∣xn)ϕ(xn,y′)软间隔。
Structured SVM
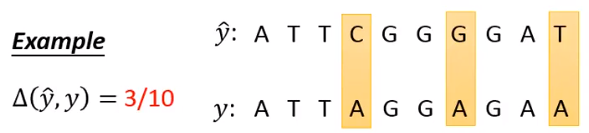
它的三板斧前面两板和Structured Perceptron的一样: Problem 1: Evaluation F(x,y)=w⋅ϕ(x,y) 这里的ϕ(x,y)可以自定义,如果不知道咋定义,可以直接和CRF定义一样的即可 Problem 2:Inference y~=argy∈Ymaxw⋅ϕ(x,y) 这个可以Viterbi算法来解 Problem 3: Training Consider margin and error: Way 1. Gradient Descent Way 2. Quadratic Programming (Cutting Plane Algorithm) Structured SVM还要考虑error: Error function:Δ(yn,y) Δ(yn,y):Difference between y and yn Structured SVM的cost函数就是Δ(yn,y)的upper bound,也就是说cost函数实际上是最小化error的upper bound。 理论上,Δ(yn,y)可以我们自己随意定义,只要能衡量y and yn之间的差异就可以。 但是我们要考虑解决Problem 2.1 yˉn=argymax[Δ(yn,y)+w⋅ϕ(xn,y)] 下面是一个很好算的错误率Δ(yn,y) 在这个情况下, problem 2.1 can be solved by Viterbi Algorithm
Performance of Different Approaches
POS Tagging Ref: Nguyen, Nam, and Yunsong Guo. “Comparisons of sequence labeling algorithms and extensions.” ICML, 2007. Name Entity Recognition Ref: Tsochantaridis, Ioannis, et al. “Large margin methods for structured and interdependent output variables.” Journal of Machine Learning Research. 2005.