整理转载,非原创。参考:
[1] 基于卷积的神经网络的时间序列预测——WaveNet
[2] Forecasting with Neural Networks - An Introduction to Sequence-to-Sequence Modeling Of Time Series
[3] 谷歌WaveNet如何通过深度学习方法来生成声音?
预测未来
使用过去的数据试图了解未来已经存在,因为人类已经并且应该随着计算和数据资源的扩展而变得越来越普遍。公司可以使用预测方法来预测其业务核心趋势,改善决策制定和资源分配。实例比比皆是:杂货连锁店和在线零售商预测产品对库存的需求,热门网站预测页面访问以管理服务器需求。
这些不同的应用程序在时间序列预测的保护下共享一个共同的量化框架。每个感兴趣的单元(项目,网页,位置)具有随时间变化的定期测量值(购买,访问,乘坐),从而产生大量时间序列。
为什么要引入神经网络模型
在传统的时间序列预测中,系列通常是单独考虑的,然后预测模型与特定于系列的参数相匹配。这种风格的一个例子是经典的自回归集成移动平均(ARIMA)模型。特定于系列的模型通常可以做出很好的预测,但不幸的是,它们无法很好地适应预测系列数量扩展到数千甚至数十万个系列的问题。此外,拟合系列特定模型无法捕捉到可以从研究许多基本相关系列中学到的表达性一般模式。从上面的例子中,我们可以看到许多公司都面临着这种具有挑战性的“高维”时间序列设置。
幸运的是,多步时间序列预测可以表示为序列到序列的监督预测问题,这是一个适合现代神经网络模型的框架。以增加构建和调整模型的复杂性为代价,可以使用一个模型捕获所有系列中的整个预测问题。由于神经网络是自然特征学习者,因此在准备模型时也可以采用简约的方法来进行特征工程。当需要将外生变量集成到模型中时(例如产品类别,网站语言,星期几等),由于神经网络架构的灵活性,实现很简单。
WaveNet
优点
WaveNet模型的架构允许它利用卷积层的效率,同时减轻在大量时间步长(1000+)内学习长期依赖性的挑战。后者是复发神经网络的常见痛点,即使是那些包含一些长期记忆机制(如LSTM)的神经网络。
简介
WaveNet的核心是扩张的因果卷积层(Dilated Casual Convolutions),它允许它正确处理时间顺序并处理长期依赖,而不会导致模型复杂性的爆炸。以下是DeepMind帖子中其结构的可视化:

因果卷积 Casual Convolutions
首先,是什么造成了卷积因果关系?在传统的一维卷积层中,我们在输入序列上滑动权重过滤器,顺序地将其应用于系列的(通常是重叠的)区域。但是当我们使用时间序列的历史来预测它的未来时,我们必须要小心。当我们形成最终将输入步骤连接到输出的层时,我们必须确保输入不会影响及时进行输出的输出步骤。否则,我们将使用未来预测过去,所以我们的模型会作弊!
为了确保我们不以这种方式作弊,我们调整卷积设计以明确禁止未来影响过去。换句话说,我们只允许输入连接到因果结构中的未来时间步输出,如下图所示,来自WaveNet论文的可视化。实际上,这种因果一维结构很容易通过将传统的卷积输出移动多个时间步来实现。
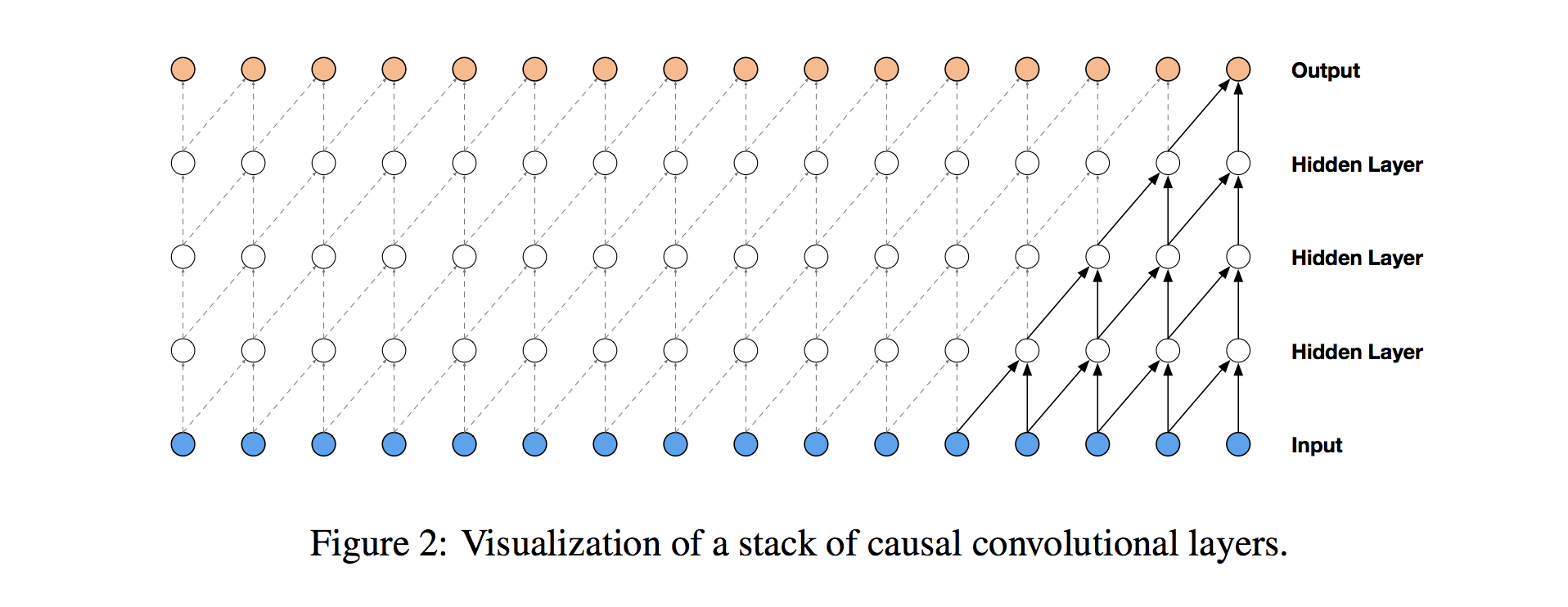
因果卷积提供了处理时间流的适当工具,但我们需要进行额外修改以正确处理长期依赖性。在上面的简单因果卷积图中,您可以看到只有5个最近的时间步长可以影响突出显示的输出。事实上,我们需要每个时间步一个额外的层才能在系列中更远的地方(使用适当的术语,以增加输出的感受野)。对于具有大量步骤的时间序列,使用简单的因果卷积来从整个历史中学习将很快使得模型方式在计算上和统计上更加复杂。
扩张的卷积 Dilated convolutions

WaveNet使用扩张的卷积而不是犯这个错误,这使得感知场随着卷积层深度的增加呈指数增长。在扩张的卷积层中,滤波器不以简单的顺序方式应用于输入,而是跳过恒定的扩张速率在它们处理的每个输入之间输入,如下面的WaveNet图中所示。通过在每一层(例如1,2,4,8,…)乘法增加膨胀率,我们可以实现我们所需的层深度和感受野大小之间的指数关系。在图中,您可以看到我们现在如何只需要4层将所有16个输入系列值连接到突出显示的输出(比如第17个时间步长值)。通过扩展,当使用每日时间序列时,人们可以捕获超过一年的历史,只有9个这种形式的扩张卷积层。
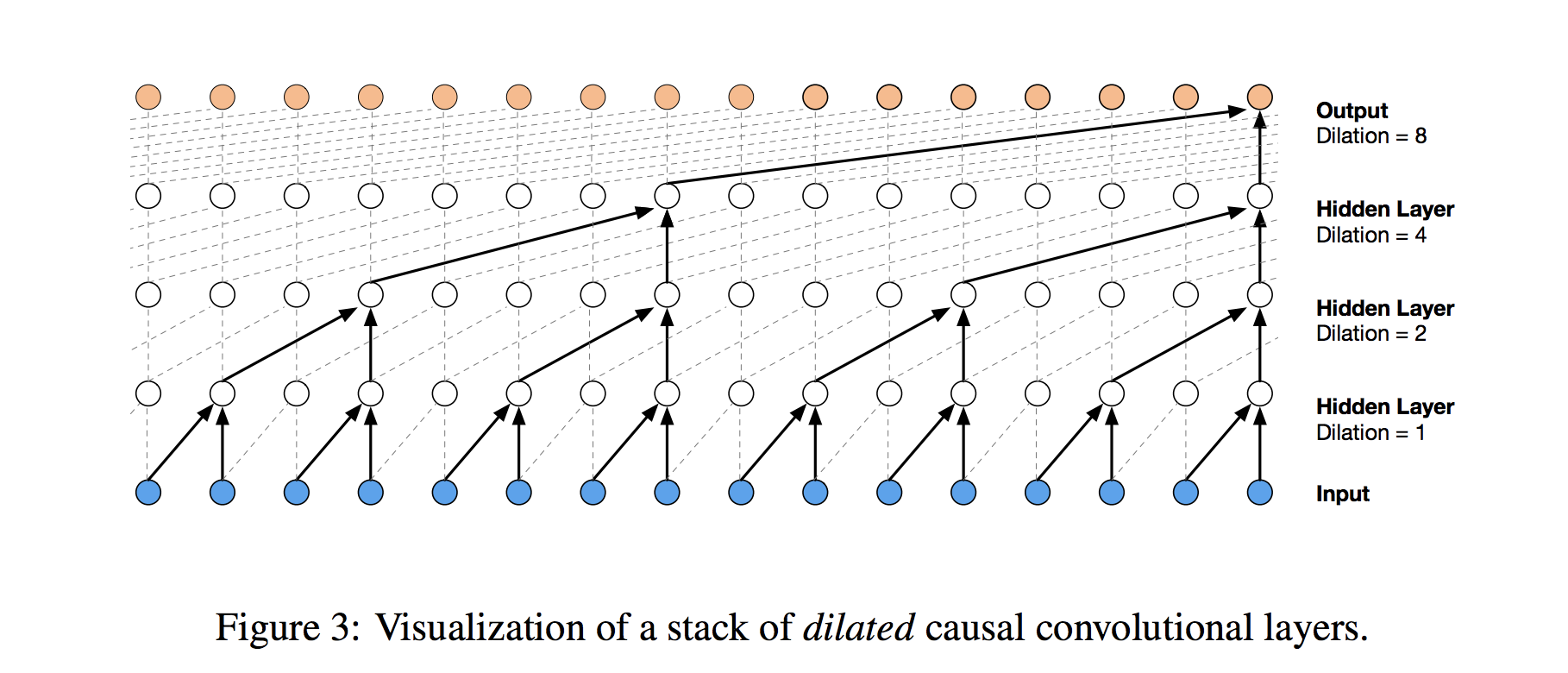
扩张卷积可以使模型在层数不大的情况下有非常大的感受野。在图2中,一般的Causal CNN网络,当层数增加,涵盖的范围是线性增加;而在图3的扩张卷积网络中,范围是指数增加。因此只要增加一层,就可以多关联至一倍的时间范围。用9层的dilation CNN(dilation=[1,2,4,8,16,32,64,128,256,512]),其作用相当于一个1层1x1024的卷积层,但更好训练,非线性表现也更强。
