本文不做任何商业用途,仅仅用于知识分享。如有侵权行为,请联系我谢谢。
通过阅读书籍查阅相关资料总结得出
本人片面理解:
map 相当于数据准备阶段,主要负责从HDFS中读取分块,因为每个分块的大小近乎相等,所以通过集群调度任务将数据采集到map中。实现读取效率最大化
reduce。处理各个节点上map的值(利用网络传输)传输到reduce节点。由reduce 完成 聚合,排序等一系列处理。最终写入hdfs中。
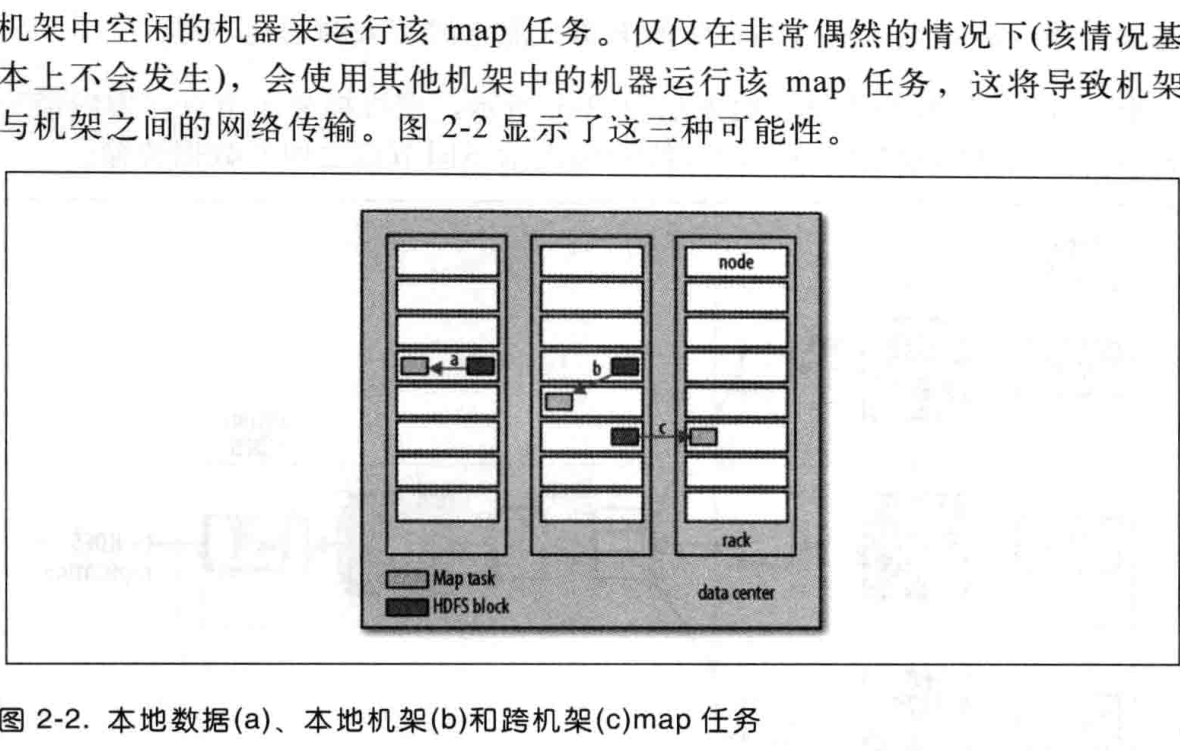
注意:集群上调度的每个tasktrigger 任务在处理map会遇到如下情况。
绝大部分处理都是箭头a,如果a走不通。会利用网络传输到其他map节点上继续准备数据,箭头b。箭头c的情况也有。不过几乎非常小。
如图:
数据准备好后 就要交给 reduce来处理数据了。不过需要注意的是,map属于准备数据阶段。不会将数据存储到 hdfs中。如果在传输到 reduce时数据发生丢失,则会重新跑丢失的map传递给reduce。
流程图如下:

。