为了逼迫自己每周能做一下复习和总结,计划每周都写一个周学习总结。哪怕是草草写一点流水账,也比浪费周末的时间强。
1、计算机组成原理
1) 体系结构与组成
● 计算机体系结构是指对成员可见的系统属性 ,直接影响程序的逻辑执行。
体系结构的属性包括指令集、输入输出机制与内存寻址技术等。
● 计算机组成是指对体系结构所体现属性的实现方法,是实现结构规范的操作单元及其相互连接。
组成的属性包括对程序员可见的硬件细节,如控制信号、计算机和塞舌的接口以及存储器使用的技术。
2) 结构与功能
计算机是一个复杂的系统,包含数百万个电子元件,复杂系统的关键是分层性质。层次系统是一系列相互关联的子系统,每个子系统又在结构上分层,直到分成我们所能达到的一些基本子系统的最低级。
● 结构:部件相互关联的方法。
● 功能:作为结构组成部分的各个独立部件的操作。
● 基本功能:数据处理、数据存储、数据传输和控制。
数据的处理、存储和传输都必须经过控制。控制是由计算机提供指令施加的。
3) 结构组件
计算机中有四种主要的结构组件:中央处理器(CPU)、主存储器(主存或内存)、输入/输出(I/O)和总线系统。
● 中央处理器:控制计算机的操作(控制器)并执行数据处理功能(算术逻辑单元ALU)。
● 主存储器:存储程序和数据。
● 输入/输出:在计算机与外部之间传输数据。
● 总线系统:为CPU、主存和I/O之间提供通信机制。
4) 冯氏结构
美籍匈牙利数学家冯•诺依曼在1945年提出了存储程序控制的概念。概括内容如下:
● 计算机硬件由运算器、控制器、存储器、输入设备和输出设备这五个基本设备组成。
● 计算机内部采用二进制来表示指令和数据。
● 把编好的程序和原始数据事先存入存储器中。
● 把编好的程序和原始数据预先存入计算机的主存储器中,使计算机在工作时能连续、自动、高速地从存储器中取出一条条指令并加以执行,从而自动完成预定的任务。
5) 计算机层次结构
计算机的层次结构可分为0~6共七个层次。
● 第零级是硬联逻辑级,是计算机的内核,由门、触发器等逻辑电路组成。
● 第一层微程序级。这级的机器语言是微指令集,用微指令编写的微程序一般是直接由硬件执行的。
● 第二层是传统机器级。这级的机器语言是指机器的指令集,用机器指令编写的程序由微程序进行解释。
● 第三层是操作系统级。从操作系统的基本功能来看,直接管理传统机器的软硬件资源。
● 第四层是汇编语言层。语言是汇编语言,完成汇编语言翻译的程序叫汇编程序。
● 第五层是高级语言层。这级的语言是各种高级语言,面向用户的,由各种高级语言程序支持和执行。通常用编译程序来完成各种高级语言的翻译工作。
● 第六级是应用语言级,这一级是为了使计算机满足某种用途而专门设计的,因此这一级语言就是各种面向问题的应用语言。
6) 主要性能指标
计算机的性能可由如下技术指标表示:机器字长、数据通路宽度、主存容量和运算速度表示。运算速度又有如下指标:
● 吞吐量:计算机系统在单位时间内处理请求的数量。
● 响应时间:计算机系统对请求做出响应的时间,包括CPU时间和等待时间的总和。
● 主频(时钟频率):CPU内数字脉冲信号振荡的速度。
● 时钟周期:主频的倒数,CPU中最小的时间元素。每个动作至少需要一个时钟周期。
● CPI:每条指令所用的时钟周期数。
● IPC:CPI的倒数;由于指令高度并行化,现代计算机一个时钟周期内可以处理多条指令。IPC表示一个时钟周期内处理的指令个数。
● CPU执行时间 = CPU时钟周期数 / 时钟频率 = 指令数 * CPI / 时钟频率
● MIPS:每秒执行多少百万条指令。MIPS = 指令条数 * 10-6 / 执行时间 = 主频 / CPI = 主频 * IPC
● MFLOPS:每秒执行多少百万次浮点运算。MFLOPS = 浮点运算次数 * 10-6 / 执行时间
7) 非数值类数据
● ASCII码
在计算机中通常使用美国国家信息交换标准字符码即ASCII码表示字符。ASCII码的编码特点:
1、用7位二进制表示1个字符,最高位用作奇偶校验。
2、可表示128个字符(包括数字字符、英文大小写字母、专用字符和控制字符)
3、数字0-9的ASCII码对应30H-39H
4、同一英文字母的大写和小写的ASCII码相差20H
字符串:字符串可用两种不同的存放方法 向量法 和 串表法。
● 汉字编码
汉字的编码涉及4种编码:
1.、汉字交换码:国标码GB-2312。
2.、输入码:主要用于从键盘输入汉字。常见的有区位码、拼音码等。:国标码=区位码(十六进制)+2020H。
3.、机内码:计算机系统内部用来标识汉字的编码。机内码=国标码+8080H;机内码=区位码+A0A0H
4.、字形码:汉字字形码是指确定一个汉字字形点阵的代码,又叫汉字字模码或汉字输出码。
● Unicode编码
Unicode是国际组织制定的可以容纳世界上所有文字和符号的字符编码方案。
1、编码方式
用一个16位的二进制数(两个字节)来表示Unicode的每一个符号。
2、实现方式
Unicode的实现方式称为Unicode的转换格式(unicodeTranslation Format, UTF)。
8) 数值类数据
计算机中参与运算的数值有两大类:无符号数与有符号数。无符号数相当于数的绝对值;有符号数在最高位设置符号位。
常见的有符号机器数如下:
● 原码
原码的编码规则:在数值前加一位符号位。正号用0表示,符号用1表示,数值部分保持不变。
整数原码定义:正数不变,负数[x]原=2n - x = 2n + |x| 例如:[+1011]原 = 01011;[-1011]原 = 11011
小数原码定义:正数不变,负数[x]原=1 - x = 1 + |x| 例如:[+0.1011]原 = 1.1011;[-0.1011]原 = 1.1011
原码时,0有两种表示方式,两位二进制数为例,[+0]原 = 00 ;[-0]原 = 10 ;8位能表示 -(27 -1) ~ 27 -1 (去掉最高符号位)
● 反码
反码的编码规则:在数值前加一位符号位。正号用0表示,符号用1表示;正数的数值部分保持不变,负数的数值部分按位取反。
整数反码定义:正数不变,负数[x]反=2n+1-1 + x 例如:[+1011]反 = 01011;[-1011]反 = 10100
小数反码定义:正数不变,负数[x]反=(2 - 2-n) + x 例如:[+0.1011]反 = 1.1011;[-0.1011]反 = 1.0100
反码时,0有两种表示方式,两位二进制数为例,[+0]反 = 00 ;[-0]反 = 11 ;8位能表示 -(27 -1) ~ 27 -1 (去掉最高符号位)
● 补码
补码的编码规则:在数值前加一位符号位。正号用0表示,符号用1表示;对于正数,数值部分保持不变;对于负数,数值部分按位取反末尾加1。
整数补码定义:正数不变,负数[x]补=2n+1 + x 例如:[+1011]补 = 01011;[-1011]补 = 10101
小数补码定义:正数不变,负数[x]补=2 + x 例如:[+0.1011]补 = 1.1011;[-0.1011]补 = 1.0101
补码时,0仅有一种表示形式。两位二进制为例,[+0]补=[-0]补=00;8位能表示 -27 ~ 27 -1 (去掉最高符号位)
● 常用求补码方法
1、 由定义求补码
由真值求补码,直接利用补码的定义。反过来,由补码求真值,只需将公式左右进行交换就可以了
2、由原码求补码
正数的补码和原码相同;负数的补码,将原码除符号位以外的其余各位求反,末位加1。
3、求负数补码的简便原则
可以将原码除符号位以外,其余各位按位取反,从最低位开始遇到的第一个1以前的各位保持不变。
2、计算机网络
定义:计算机网络就是一种通信网络,是互连的、自治的计算机集合。
● 协议
硬件是计算机网络的基础,而计算机网络中的数据交换必须遵守事先约定好的规则,这一规则就是协议。
定义:网络协议,简称为协议,是为进行网络中的数据交换而建立的规则、标准或约定。
协议的三要素:语法、语义、时序:
1、语法:数据与控制信息的结构或格式。
2、语义:需要发出何种控制信息、完成何种动作以及做出何种响应以及差错控制。
3、时序:事件顺序与速度匹配。
● 计算机网络结构
计算机网络结构可分为三块:网络边缘、接入网络/物理介质、网络核心。
1、网络边缘:由运行网络应用的主机组成。
基本模型:客户/服务器应用模型(C/S)与对等应用模型(P2P)。
2、接入网络:分为住宅(家庭)接入网络、机构接入网络 (学校,企业等)、移动接入网络。
接入方式:数字用户线路 (DSL)和电缆网络。
数字用户线路:利用已有的电话线连接中心局的DSLAM,数据通信通过DSL电话线接入Internet;电话通过DSL电话线接入电话网。采用频分多路复用(FDM):>50 kHz - 1 MHz用于下行;4 kHz - 50 kHz用于上行;0 kHz - 4 kHz用于传统电话。设备独占接入网络。
电缆网络:使用混合光纤同轴电缆(HFC),采用频分多路复用(FDM):在不同频带(载波)上传输不同频道。各家庭(设备)通过电缆网络→光纤接入ISP路由器,各家庭共享家庭至电缆头端的接入网络。
3、网络核心:互联的路由器网络
关键功能:路由+转发(路由:确定分组从源到目的传输路径;转发:将分组从路由器的输入端口交换至正确的输出端口)
● 数据交换
所有设备相互连接导致的问题:N2链路问题、连通性与网络规模。因此需要交换设备与交换网络进行数据交换。
数据交换需要达成的目标:动态转接和动态分配传输资源。
数据交换的类型:电路交换、报文交换、分组交换。
1、电路交换
电路交换的三个阶段:建立连接(呼叫/电路建立)、通信、释放连接(拆除电路)。期间资源由该交换独享。
2、报文交换
源(应用)发送信息整体。串行:当上一步交换完成后才进行下一步交换。
3、分组交换
报文分拆出来的一系列相对较小的数据包,需要报文的拆分与重组,会产生额外开销。
并行:多个分组的交换可以同时进行。例如:当电脑1向路由器A发送分组时,路由器A也可以向路由器B发送分组,同时路由器B也可以向电脑2发送分组。
报文交换VS分组交换:更为节约时间,对路由器缓存需求更低。
电路交换VS分组交换:分组交换允许更多用户同时使用网络!
分组交换适用于突发数据传输网络。
优点:资源充分共享,简单、无需呼叫建立。
缺点:可能产生拥塞(congestion): 分组延迟和丢失。需要协议处理可靠数据传输和拥塞控制。
● 多路复用
多路复用的特点:链路/网络资源(如带宽)划分为“资源片”;将资源片分配给各路呼叫;每路呼叫独占分配到的资源片进行通信;资源片可能闲置。
经典多路复用方法:频分多路复用(FDM)、时分多路复用(TDM)、波分多路复用(WDM)、码分多路复用(CDM)。
1、频分多路复用:各用户占用不同的频率带宽资源。用户在分配到一定的频带后,在通信过程中自始至终都占用这个频带。
2、时分多路复用:将时间划分为一段段等长的时分复用帧(TDM 帧),每个用户在每个 TDM 帧中占用固定序号的时隙每用户所占用的时隙是周期性出现(其周期就是TDM 帧的长度)。所有用户是在不同的时间占用相同的频带宽度。
3、波分多路复用:波分复用就是光的频分复用。
4、码分多路复用:每个用户分配一个唯一的m bit 码片序列(其中“0”用“-1”表示、“1”用“+1”表 示)。各用户使用相同频率载波,利用各自码片序列编码数据。编码信号 = (原始数据) × (码片序列)。各用户码片序列相互正交。解码: 码片序列与编码信号的内积。
3、算法分析与设计
● 算法与程序
算法是指解决问题的一种方法或一个过程。
算法是若干指令的有穷序列,满足性质:
(1) 输入:有外部提供的量作为算法的输入。
(2) 输出:算法产生至少一个量作为输出。
(3) 确定性:组成算法的每条指令是清晰,无歧义的。
(4) 有限性:算法中每条指令的执行次数是有限的,执行每条指令的时间也是有限的。
程序是算法用某种程序设计语言的具体实现。程序可以不满足算法的性质,例如操作系统。
● 设计算法的步骤
理解问题:在设计一个算法前,我们需要做的第一件事就是完全理解所给出的问题。同时,严格确定算法需要处理的实例范围是非常重要的。一个正确的算法不仅应该能处理大多数的情况,而且应该能正确处理所有合法的输入。
了解计算机设备的性能:今天使用的大多数算法仍然要运行于冯·诺依曼计算机上。它最主要的随机存取机设想是:指令逐条运行,每次执行一步操作,称为顺序算法。一些更新式的计算机可以在同一时间执行多条操作,即并行计算。
在精确和近似间做选择:精确的解法称为精确算法,近似的解法称为近似算法。无法求得精确解或由于某些问题固有的复杂性,用已知的精确算法来解决该问题可能会慢得无法接受。
确定适当的数据结构: 算法和数据结构是计算机编程的重要基础。程序=算法+数据结构
● 分析算法的指标
对于一个任何一个算法或解决方案,有下面的两个问题:
(1) 问题能解决吗?
(2) 问题解决的好吗?
效率分析并不是算法分析的唯一目的。虽然算法追求的目标是速度,但算法必须首先正确才有存在的意义。设计算法时,或者对多个算法进行比较时,就要分析它们的正确性和时间效率。这种对算法进行解剖而获得其正确性和时间效率的操作就是算法分析。如果两个算法的时间效率一样,我们就要对算法实现所使用的空间进行比较,空间使用较少的为优。
因此,算法分析可以分为如下3个方面:
(1) 正确性分析
(2) 时空效率分析
(3) 时空特性分析
算法复杂性 = 算法所需要的计算机资源
算法的时间复杂性T(n);算法的空间复杂性S(n)。
其中n是问题的规模(输入大小)。
算法的时间复杂性有如下分析方法:
(1)最坏情况下的时间复杂性
Tmax(n) = max{ T(I) | size(I)=n }
(2)最好情况下的时间复杂性
Tmin(n) = min{ T(I) | size(I)=n }
(3)平均情况下的时间复杂性
Tavg(n) =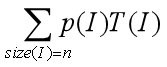
其中I是问题的规模为n的实例,p(I)是实 例I出现的概率。
若对 T(n) →∞ , as n→∞ ;
有(T(n) - t(n) )/ T(n) →0 ,as n→∞;
则称t(n)是T(n)的渐近性态,为算法的渐近复杂性。
在数学上, t(n)是T(n)的渐近表达式,是T(n)略去低阶项留下的主项。它比T(n) 简单。
渐近分析的记号:在下面的讨论中,对所有n,f(n) ≥ 0,g(n) ≥ 0。
(1) 渐近上界记号O
O(g(n)) = { f(n) | 存在正常数c和n0使得对所有n≥ n0有:0 ≤ f(n) ≤ cg(n) }
(2) 渐近下界记号Ω
Ω(g(n)) = { f(n) | 存在正常数c和n0使得对所有n≥ n0有:0 ≤ cg(n) ≤ f(n) }
(3) 非紧上界记号o
o(g(n)) = { f(n) | 对于任何正常数c>0,存在正数和n0 >0使得对所有n≥ n0有:0 ≤ f(n) < cg(n) }
等价于 f(n) / g(n) →0 ,as n→∞。
(4) 非紧下界记号ω
ω(g(n)) = { f(n) | 对于任何正常数c>0,存在正数和n0 >0使得对所有n ≥ n0有:0 ≤ cg(n) < f(n) }
等价于 f(n) / g(n) →∞ ,as n→∞。
f(n) ∈ ω (g(n)) 等价于 g(n) ∈ o (f(n))
(5) 紧渐近界记号Θ
Θ(g(n)) = { f(n) | 存在正常数c1,c2和n0使得对所有n ≥ n0有:c1g(n) ≤ f(n) ≤ c2g(n) }
对于算法的时间函数f(n),如果f(n)和g(n)是同一数量级的(同阶),可用f(n)=O(g(n))的形式来表示。称上式为算法的时间复杂度,或称该算法的时间复杂度为O(g(n)) 。
一般常用的时间复杂度有如下的关系:
O(1) ≤O (log2n) ≤O (n) ≤O (n*log2n) ≤O (n2) ≤O (n3) ≤ … ≤O (nk) ≤O (2n)<O(n!)
● 算法的分类
算法大致分为以下三类:
(1) 有限的、确定性算法
这类算法在有限的一段时间内终止。它们可能要花很长时间来执行指定的任务,但仍将在一定的时间内终止。这类算法得出的结果常取决于输入值。
(2) 有限的、非确定算法
这类算法在有限的时间内终止。然而,对于一个(或一些)给定的数值,算法的结果并不是唯一的或确定的。
(3) 无限的算法
指那些由于没有定义终止条件,或定义的条件无法由输入的数据满足而不终止运行的算法。通常,无限算法的产生是由于未能确定地定义终止条件。
经典算法:
1.穷举搜索法
2.迭代算法
3.递推算法
4.递归算法
5.分治算法
6.贪心算法
7.动态规划算法
8.回溯算法
9.分支限界算法
不知不觉看书复习加码字花了4个小时,下次总结需要再认真整理归纳一遍,只要记录重点。
