前面我自己写的我看着都头大,我看看能不能给大家写的精简点,好理解。
我们需要的数据:
链接:https://pan.baidu.com/s/1xr4x43bfEe4hVWYtwiFGRw
提取码:yabw
如果链接失效一定要在评论区说一下。
数据的预处理
1.数据分析的步骤:
获取数据---->数据预处理---->数据分析---->数据挖掘
2.数据预处理:数据分析和数据挖掘的瓶颈(这里看看就行,具体方法就是使用pandas和numpy包进行操作,这在之前是讲过的)
包括的内容:
-获取数据
-载入数据
-清洗数据:异常
-清洗数据:维度
-清洗数据:粒度
-缺失值;无效值;格式转换;命名转换;类型转换
3、数据的载入:
import pandas as pd
#打开文件(数据分析数据可视化的时候讲过打开文件用的几个函数)
data=pd.read_csv(r'D:\BaiduNetdiskDownload\数据挖掘打包资料\数据挖掘打包资料\tips.csv')
print(data.head())
#输出前五行
total_bill,tip,sex,smoker,day,time,size
0 16.99,1.01,Female,No,Sun,Dinner,2
1 10.34,1.66,Male,No,Sun,Dinner,3
2 21.01,3.5,Male,No,Sun,Dinner,3
3 23.68,3.31,Male,No,Sun,Dinner,2
4 24.59,3.61,Female,No,Sun,Dinner,4
print(data.tail())
#输出后五行
total_bill,tip,sex,smoker,day,time,size
239 29.03,5.92,Male,No,Sat,Dinner,3
240 27.18,2.0,Female,Yes,Sat,Dinner,2
241 22.67,2.0,Male,Yes,Sat,Dinner,2
242 17.82,1.75,Male,No,Sat,Dinner,2
243 18.78,3.0,Female,No,Thur,Dinner,2
data1=pd.read_table(r'D:\BaiduNetdiskDownload\数据挖掘打包资料(1)\数据挖掘打包资料\douban.dat',sep='::')
#我们的数据已经读出来了,3648103行就不去多看了。
print(data1.tail())
输出的是
45874270 2348372 4
3648098 1131322 2189780 5
3648099 1131322 1856338 3
3648100 1131322 1322066 3
3648101 1131322 1371409 5
3648102 1131322 2115040 3
4.偏度和峰度
(1) 峰度:峰度又称峰态系数,表征概率密度分布曲线在平均值处峰值高低的特征数,即是描述总体中所有取值分布形态陡缓程度的统计量。直观看来,峰度反映了峰部的尖度。这个统计量需要与正态分布相比较。
公式:峰度是样本的标准四阶中心矩(standardized 4rd central moment)。随机变量的峰度计算方法为随机变量的四阶中心矩与方差平方的比值。
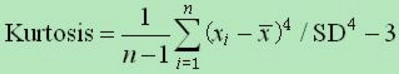
峰度 =0表示该总体数据分布与正态分布的陡缓程度相同;峰度 >0表示该总体数据分布与正态分布相比较为陡峭,为尖顶峰;峰度 <0表示该总体数据分布与正态分布相比较为平坦,为平顶峰。

(2)偏度:是描述数据分布形态的统计量,其描述的是某总体取值分布的对称性的特征统计量。这个统计量需要与正态分布相比较。
公式:偏度是样本的标准三阶中心矩。
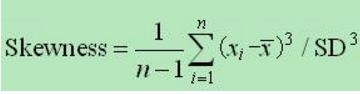
若偏度=0则其偏度与正态分布的偏斜程度相同;若偏度<0那么其偏度与正态分布相比负偏(左偏);若偏度>0那么其偏度与正态分布相比正偏(右偏)。

(3)补充(可能一些小伙伴不知道中心距是啥):
中心距:
对于正整数k,如果E(X)存在,且E[|X-E(X)k]<∞,则称E{[X-E(X)]k}为随机变量X的k阶中心矩。
公式:
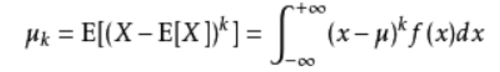
k是几就是几阶中心距。
SD:就是标准差。
5.评价数据质量
(1)通过三个方面:格式,逻辑,业务。
格式:第一步数据清洗解决:数据类型、数据范围
逻辑:计算或者判断后解决。
业务:得出结果后看一下结果是否准确
(2)数据格式问题的错误和措施
数据缺失;类型错误;数值错误
创建一个数据缺失的数据集的方法
numpy.nan
空格值处理缺失值处理,之前在数据分析数据可视化(二)里已经写了。
总结一下pandas常用的方法:
--count,describe,min.max,argmin,argmax,idxmin,idxmax
--quantile,sum,mean,median,mad,var,std
--skew,kurt
--cumsum,summin,cummax,cumprod
--diff,pct_change
(3)异常点(离群点):是与大部分其他对象显著不同的对象。大部分情况下都将这种差异信息视为噪声而丢弃
对离群点的态度:
噪声:可能是值输入错了,我们之间丢弃掉。
新模式:在想小概率事件为什么发生,既然发生了证明舅有一个新模式。可能少部分样本符合这个条件,咱们找一下这个样本的其他信息有什么特点,可能有重大发现。
6.可视化分析补充(大家感觉前面讲过的,咱们还重新再写一遍吗,我复制粘贴倒是不累,征求下大家意见,谢谢大家)
(1)列联表
import pandas as pd
data1=pd.read_csv(r'D:\BaiduNetdiskDownload\数据挖掘打包资料(1)\数据挖掘打包资料\tips.csv')
#我们的数据已经读出来了,3648103行就不去多看了。
#列联表
count=pd.crosstab(data1.sex,data1.day)
#day Fri Sat Sun Thur
#sex
#Female 9 28 18 32
#Male 10 59 58 30
#这就是一个列联表,第一个参数是行,第二个是列
count.plot(kind='bar')
#得到图在下面

count.T.plot(kind='bar')#转置一下,列和行会换过来。
得到下图

count.T.plot(kind='bar',stacked=True)
得到重合的图

(2)直方图;
import pandas as pd
data1=pd.read_csv(r'D:\BaiduNetdiskDownload\数据挖掘打包资料(1)\数据挖掘打包资料\tips.csv')
#我们的数据已经读出来了,3648103行就不去多看了。
data1['tips_pct']=data1['tip']/data1['total_bill']
data1['tips_pct'].hist(bins=50)
#横坐标是取值,纵坐标是取值的频率。bins的值我们有n条记录通常取根号下n。

那几个落单的点是异常点。
7.数据的获取
方式:
(1)已有的系统数据
(2)数据建模后采样
怎么存:
数据库;日志
数据建模:
已有数据的提取和转换:入图像处理,指标构建
“埋点”:指的是针对特定用户行为或事件进行捕获、处理和发送的相关技术及其实施过程。比如用户某个按钮点击次数、浏览某个一刻吗时长等等。
练习:一只股票每日预期收益为0.1%,每日波动率为0.5%。估计100日后的预期收益。需要绘图。
import pandas,numpy
a=pandas.DataFrame(numpy.random.normal(loc=0.1,scale=0.25,size=(100,10)))
#μ=0.1,σ²=0.25,随机生成了十组数据,每组有100行
re=a.cumsum(0)#每天的变化量累加起来
re.plot()#绘图

