贝叶斯
内容:
贝叶斯定理由英国数学家贝叶斯 ( Thomas Bayes 1702-1761 ) 发展,用来描述两个条件概率之间的关系,比如 P(A|B) 和 P(B|A)。按照乘法法则,可以立刻导出:
P(A∩B) = P(A)*P(B|A)=P(B)*P(A|B)。
如上公式也可变形为:
*P(B|A) = P(A|B)P(B) / P(A)。
所谓贝叶斯公式,是指当分析样本大到接近总体数时,样本中事件发生的概率将接近于总体中事件发生的概率。
支持某项属性的事件发生得愈多,则该属性成立的可能性就愈大。
例如:一座别墅在过去的 20 年里一共发生过 2 次被盗,别墅的主人有一条狗,狗平均每周晚上叫 3 次,在盗贼入侵时狗叫的概率被估计为 0.9,问题是:在狗叫的时候发生入侵的概率是多少?
我们假设 A 事件为狗在晚上叫,B 为盗贼入侵,则以天为单位统计,P(A) = 3/7,P(B) = 2/(20365) = 2/7300,P(A|B) = 0.9,按照公式很容易得出结果:P(B|A) = 0.9(2/7300) / (3/7) = 0.00058
即在狗叫时有盗贼的概率,不等于有盗贼的时候有狗叫的概率,生活中我们经常把二者等价。
以下网址的文章非常清晰的讲述了贝叶斯公式和对MNIST识别的原理,本文中用matlab,使用贝叶斯对MNIST进行分类,收藏!
贝叶斯公式其实是考虑最大后验概率,即当已知结果对应的某一项原因的可能性最大,这项原因就被认定为真正的原因。
在数据集中,每个图片作为一个样本,它的分类结果共有10类,分别为0,1,2,3,…9 。对于一个图片,从结果看最有可能是哪一类就把他分为哪一类。
程序:
这里我使用matlab,分别设置不同函数对MNIST进行识别
clear all;clc
labels = loadMNISTLabels('E:\数据挖掘\train-labels-idx1-ubyte.txt');%读取MNIST
images = loadMNISTImages('E:\数据挖掘\train-images-idx3-ubyte.txt');
%二值化图像
images(images>0) = 1;
%label +1
labels = labels+1;
m = bc_train(images,labels,10);%进行训练bc_show_model(m);%显示模型中的种类
labels = loadMNISTLabels('E:\数据挖掘\t10k-labels-idx1-ubyte.txt')+1;
images = loadMNISTImages('E:\数据挖掘\t10k-images-idx3-ubyte.txt');
images(images>0) = 1;
yp = bc_predit(images,labels,m);%进行检测
acc = sum(yp' == labels)/length(labels)%输出正确率
结果:
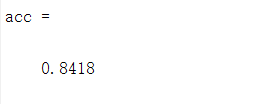

loadMNISTLabels和loadMNISTImages使用的是.txt格式的mnist数据集,并且正确率是84.18%,
比之前的SVM正确率低,但是训练和检测的速度要快很多。
‘
’
‘
’
随机森林算法(RondomForest)
实现MNIST手写体数字识别
内容:
随机森林(random forest)是2001年提出来同时支持数据的回归与分类预测算法,在具体了解随机森林算法之前,首先看一下决策树算法(Decision Tree)决策树算法通过不断的分支条件筛选,最终预测分类做出决定,
举个简单的例子,你去找工作,对方给了你一个offer,下面可能就是你决定是否最终接受或者拒绝offer一系列条件就是内部节点(矩形)最终的决定就是外部节点(叶子-椭圆)后你自己可能一个人根据上述条件决定接受了offer,但是有时候你还很不确定,你就会去很随机的问问你周围的几个朋友,他们也会根据你的情况与掌握的信息作出一系列的决策,做个形象的比喻,他们就是一棵棵单独存在的决策树,最终你根据这些结果决定接受还是拒绝offer,
前一种情况你自己做出接受还是拒绝offer就叫决策树算法,****后面一种情况,你一个人拿不定主意,还会随机问你周围的几个朋友一起给你参谋,最终做出接受还是拒绝offer的决定方式,你的那些朋友也是一棵棵单独存在的决策树,他们合在一起做决定,这个就叫做随机森林。
**当你在使用随机森林做决定时候,有时候分支条件太多,有些不是决定因素的分支条件其实你可以不考虑的,**比如在决定是否接受或者拒绝offer的时候你可能不会考虑公司是否有程序员鼓励师(啊!!!!),这个时候需要对这么小分支看成噪声,进行剪枝算法处理生成决策树、最终得到随机森林。同时随机森林的规模越大(决策树越多)、它的决策准确率也越高。随机森林算法在金融风控分析、股票交易数据分析、电子商务等领域均有应用。
程序:
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import tensorflow.examples.tutorials.mnist.input_data as input_data
data_dir = 'MNIST_data/'
mnist = input_data.read_data_sets(data_dir, one_hot=False)#从内部加载mnist数据集
batch_size = 50000
batch_x, batch_y = mnist.train.next_batch(batch_size)#进行决策树训练
test_x = mnist.test.images[:10000]
test_y = mnist.test.labels[:10000]
print("start random forest")#随机森林
for i in range(10, 200, 10):
clf_rf = RandomForestClassifier(n_estimators=i)#选取不同数量的决策树
clf_rf.fit(batch_x, batch_y)
y_pred_rf = clf_rf.predict(test_x)#进行检测
acc_rf = accuracy_score(test_y, y_pred_rf)#计算正确率
print("n_estimators = %d, random forest accuracy:%f" % (i, acc_rf))
结果:

在测试过程中,随着n_estimators数量增加,正确率不断增加,但是出现了好几次下降再增加的现象。总体来讲选择随机森林算法较慢,正确率较高。
