介紹
Servlet(Server Applet)是Java Servlet的简称,称为小服务程序或服务连接器,用Java编写的服务器端程序,具有独立于平台和协议的特性,主要功能在于交互式地浏览和生成数据,生成动态Web内容。
狭义的Servlet是指Java语言实现的一个接口,广义的Servlet是指任何实现了这个Servlet接口的类,一般情况下,人们将Servlet理解为后者。Servlet运行于支持Java的应用服务器中。从原理上讲,Servlet可以响应任何类型的请求,但绝大多数情况下Servlet只用来扩展基于HTTP协议的Web服务器。
Post/Get
doGet()
哪些是get方式呢?
- form默认的提交方式
- 如果通过一个超链访问某个地址
- 如果在地址栏直接输入某个地址
- ajax指定使用get方式的时候
doPost()
哪些是post方式呢?
- 在form上显示设置 method="post"的时候
- ajax指定post方式的时候
service()
实际上,在执行doGet()或者doPost()之前,都会先执行service()
由service()方法进行判断,到底该调用doGet()还是doPost()
可以发现,service(), doGet(), doPost() 三种方式的参数列表都是一样的。
所以,有时候也会直接重写service()方法,在其中提供相应的服务,就不用区分到底是get还是post了。
中文问题
在doPost()方法最开始加上
request.setCharacterEncoding("UTF-8");
response.setContentType("text/html; charset=UTF-8");其中第一句是把获取到的参数转为UTF-8编码
第二句是把返回的相应设为UTF-8编码
在html中加上
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8">跳转
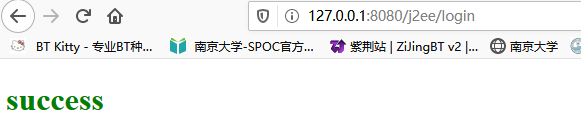
首先在web目录下准备两个页面 success.html,fail.html
protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { request.setCharacterEncoding("UTF-8"); response.setContentType("text/html; charset=UTF-8"); String name = request.getParameter("name"); String psw = request.getParameter("password"); System.out.println("name: "+name); System.out.println("password: "+psw); String html = null; if ("admin".equals(name) && "123456".equals(psw)) request.getRequestDispatcher("success.html").forward(request, response); else response.sendRedirect("fail.html"); }
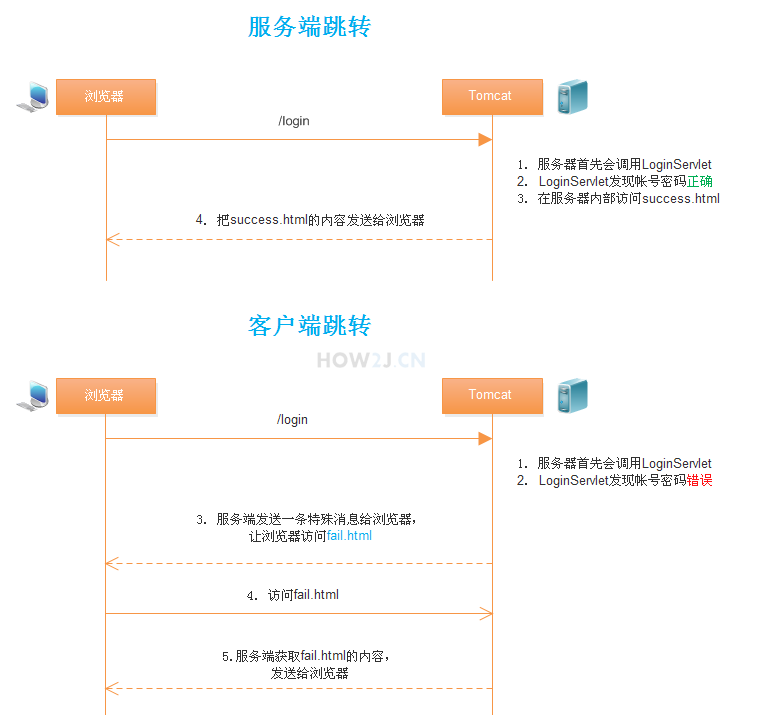
服务端跳转
request.getRequestDispatcher("success.html").forward(request, response);服务端跳转可以看到浏览器的地址依然是/login 路径,并不会变成success.html
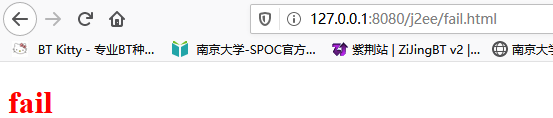
客户端跳转
response.sendRedirect("fail.html");可以观察到,浏览器地址发生了变化
原理
自启动
有的时候会有这样的业务需求:
tomcat一启动,就需要执行一些初始化的代码,比如校验数据库的完整性等。
但是Servlet的生命周期是在用户访问浏览器对应的路径开始的。如果没有用户的第一次访问,就无法执行相关代码。
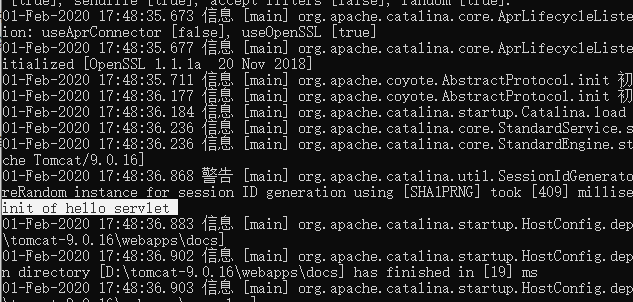
这个时候,就需要Servlet实现自启动 即,伴随着tomcat的启动,自动启动初始化,在初始化方法init()中,就可以进行一些业务代码的工作了。
方法
在web.xml中,相应的
<Servlet>标签中加上<load-on-startup>10</load-on-startup>取值范围是1-99
10表示启动顺序
如果有多个Servlet都配置了自动启动,数字越小,启动的优先级越高
给相应的Servlet补充一个方法
public void init(ServletConfig config){ System.out.println("init of hello servlet"); }
效果
request
常用方法
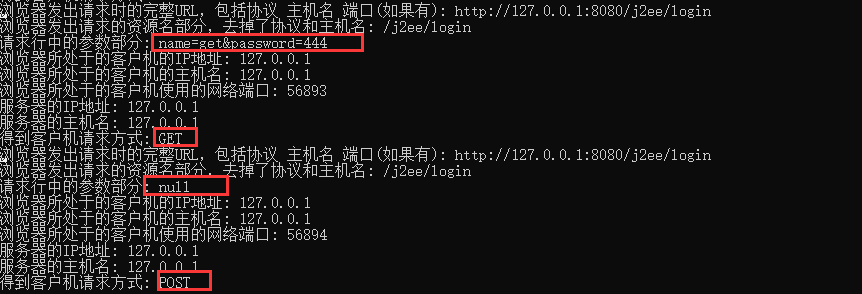
request.getRequestURL():浏览器发出请求时的完整URL,包括协议 主机名 端口(如果有)"request.getRequestURI(): 浏览器发出请求的资源名部分,去掉了协议和主机名"- `
request.getQueryString(): 请求行中的参数部分,只能显示以get方式发出的参数,post方式的看不到(只适用于post) request.getRemoteAddr(): 浏览器所处于的客户机的IP地址request.getRemoteHost(): 浏览器所处于的客户机的主机名request.getRemotePort(): 浏览器所处于的客户机使用的网络端口request.getLocalAddr(): 服务器的IP地址request.getLocalName(): 服务器的主机名request.getMethod(): 得到客户机请求方式一般是GET或者POST
@Override
protected void service(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String name = request.getParameter("name");
String password = request.getParameter("password");
System.out.println("浏览器发出请求时的完整URL,包括协议 主机名 端口(如果有): " + request.getRequestURL());
System.out.println("浏览器发出请求的资源名部分,去掉了协议和主机名: " + request.getRequestURI());
System.out.println("请求行中的参数部分: " + request.getQueryString());
System.out.println("浏览器所处于的客户机的IP地址: " + request.getRemoteAddr());
System.out.println("浏览器所处于的客户机的主机名: " + request.getRemoteHost());
System.out.println("浏览器所处于的客户机使用的网络端口: " + request.getRemotePort());
System.out.println("服务器的IP地址: " + request.getLocalAddr());
System.out.println("服务器的主机名: " + request.getLocalName());
System.out.println("得到客户机请求方式: " + request.getMethod());
String html = null;
if ("admin".equals(name) && "123".equals(password))
html = "<div style='color:green'>登录成功</div>";
else
html = "<div style='color:red'>登录失败</div>";
response.setContentType("text/html; charset=UTF-8");
PrintWriter pw = response.getWriter();
pw.println(html);
}
获取参数
request.getParameter(): 是常见的方法,用于获取单值的参数request.getParameterValues(): 用于获取具有多值的参数,比如注册时候提交的 "hobits",可以是多选的。request.getParameterMap(): 用于遍历所有的参数,并返回Map类型。
例子:
写一个html
<form action="register" method="get">
账号 : <input type="text" name="name"> <br>
爱好 : LOL<input type="checkbox" name="hobits" value="lol">
DOTA<input type="checkbox" name="hobits" value="dota"> <br>
<input type="submit" value="注册">
</form>
Servlet
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
System.out.println("获取单值参数name:" + request.getParameter("name"));
String[] hobits = request.getParameterValues("hobits");
System.out.println("获取具有多值的参数hobits: " + Arrays.asList(hobits));
System.out.println("通过 getParameterMap 遍历所有的参数: ");
Map<String, String[]> parameters = request.getParameterMap();
Set<String> paramNames = parameters.keySet();
for (String param : paramNames) {
String[] value = parameters.get(param);
System.out.println(param + ":" + Arrays.asList(value));
}
}
获取头信息
request.getHeader()获取浏览器传递过来的头信息。比如
getHeader("user-agent")可以获取浏览器的基本资料,这样就能判断是firefox、IE、chrome、或者是safari浏览器request.getHeaderNames()获取浏览器所有的头信息名称,根据头信息名称就能遍历出所有的头信息
public void doGet(HttpServletRequest request, HttpServletResponse response){
Enumeration<String> headerNames= request.getHeaderNames();
while(headerNames.hasMoreElements()){
String header = headerNames.nextElement();
String value = request.getHeader(header);
System.out.printf("%s\t%s%n",header,value);
}
}
response
设置响应内容
PrintWriter pw= response.getWriter();
有println(),append(),write(),format()等方法
设置响应格式
response.setContentType("text/html");设置响应编码
设置响应编码有两种方式
response.setContentType("text/html; charset=UTF-8");response.setCharacterEncoding("UTF-8");
这两种方式都需要在response.getWriter调用之前执行才能生效。
他们的区别在于:
- 前者不仅发送到浏览器的内容会使用UTF-8编码,而且还通知浏览器使用UTF-8编码方式进行显示。所以总能正常显示中文
- 后者仅仅是发送的浏览器的内容是UTF-8编码的,至于浏览器是用哪种编码方式显示不管。 所以当浏览器的显示编码方式不是UTF-8的时候,就会看到乱码,需要手动再进行一次设置。
301 302 跳转
302 表示临时跳转
response.sendRedirect("fail.html");301 表示永久性跳
response.setStatus(301); response.setHeader("Location", "fail.html");
设置不使用缓存
使用缓存可以加快页面的加载,降低服务端的负担。但是也可能看到过时的信息,可以通过如下手段通知浏览器不要使用缓存
response.setDateHeader("Expires",0 );
response.setHeader("Cache-Control","no-cache");
response.setHeader("pragma","no-cache");