一、CephFs介绍
二、CephFS架构
三、配置CephFS MDS
1、创建一个Ceph文件系统
1.1、以kernel client 形式挂载CephFS
1.2、以FUSE client 形式挂载CephFS
四、MDS主备与主主切换
1、配置主主模式
2、还原单主MDS
一、CephFs介绍
Ceph File System (CephFS) 是与 POSIX 标准兼容的文件系统, 能够提供对 Ceph 存储集群上的文件访问. Jewel 版本 (10.2.0) 是第一个包含稳定 CephFS 的 Ceph 版本. CephFS 需要至少一个元数据服务器 (Metadata Server - MDS) daemon (ceph-mds) 运行, MDS daemon 管理着与存储在 CephFS 上的文件相关的元数据, 并且协调着对 Ceph 存储系统的访问。
说在前面的话,cephfs其实是为用户提供的一个文件系统,把ceph这个软件把里面的空间,模拟一个文件系统的格式来提供服务,它有posix标准的文件系统的接口能够为ceph集群存储文件,能够提供访问,目前在大多数公司用cephfs也是比较少的,也是由于性能原因,但是也有一些场景也会用到。
对象存储的成本比起普通的文件存储还是较高,需要购买专门的对象存储软件以及大容量硬盘。如果对数据量要求不是海量,只是为了做文件共享的时候,直接用文件存储的形式好了,性价比高。
二、CephFS 架构
底层是核心集群所依赖的, 包括:
OSDs (ceph-osd): CephFS 的数据和元数据就存储在 OSDs 上
MDS (ceph-mds): Metadata Servers, 管理着 CephFS 的元数据
Mons (ceph-mon): Monitors 管理着集群 Map 的主副本
因为这个map里面维护着很多数据的信息索引,所有的数据都要从mons中map里获取去osd里找这个数据,其实获取这个数据的流程大概都是一样的,只不过它存在的是不同的库,不同的map
Ceph 存储集群的协议层是 Ceph 原生的 librados 库, 与核心集群交互.
CephFS 库层包括 CephFS 库 libcephfs, 工作在 librados 的顶层, 代表着 Ceph文件系统.最上层是能够访问 Ceph文件系统的两类客户端,由于有这个libcephfs这个库,cephfs才能对外提供服务,因为底层是不能提供服务的,都得通过它这个第三方的lib库才能去提供访问,
元数据:文件的名字和属性信息叫元数据,和数据是隔离开的
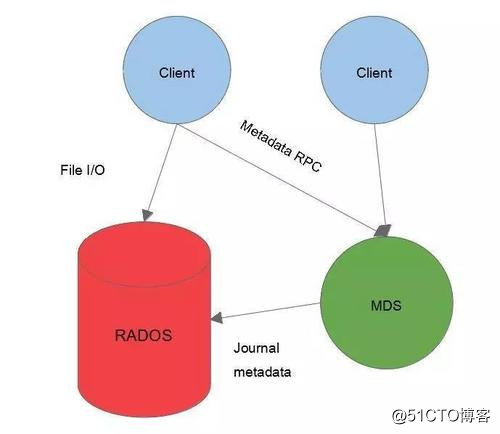
CephFs的数据是怎么访问的?
首先客户端通过RPC协议到达MDS,从MDS获取到元数据的信息,客户端与RADOS获取文件的一个IO操作,那么有了这两份信息,用户就能得到了想要的那份文件,MDS和RADOS之间通过journal metadate,这个Journal是记录文件写入日志的,这个也是存放到OSD当中的,MDS和rados之间也是由交互的,因为所有最终的数据都会存到rados当中
 !
!
三、配置 CephFS MDS
要使用 CephFS, 至少就需要一个 metadata server 进程。可以手动创建一个 MDS, 也可以使用 ceph-deploy 或者 ceph-ansible 来部署 MDS。
登录到ceph-deploy工作目录执行
hostname指定ceph集群的主机名
#ceph-deploy mds create $hostname

四、部署Ceph文件系统
部署一个 CephFS, 步骤如下:
在一个 Mon 节点上创建 Ceph文件系统.
若使用 CephX 认证,需要创建一个访问 CephFS 的客户端
挂载 CephFS 到一个专用的节点.
以 kernel client 形式挂载 CephFS
以 FUSE client 形式挂载 CephFS
1、创建一个 Ceph 文件系统
1、首先要创建两个pool,一个是cephfs-data,一个是cephfs-metadate,分别存储文件数据和文件元数据,这个pg也可以设置小一点,这个根据OSD去配置
#ceph osd pool create cephfs-data 256 256
#ceph osd pool create cephfs-metadata 64 64查看已经创建成功
[root@cephnode01 my-cluster]# ceph osd lspools
1 .rgw.root
2 default.rgw.control
3 default.rgw.meta
4 default.rgw.log
5 rbd
6 cephfs-data
7 cephfs-metadata关于ceph的日志,可以在/var/log/ceph下可以查看到相关信息
[root@cephnode01 my-cluster]# tail -f /var/log/ceph/ceph
ceph.audit.log ceph.log ceph-mgr.cephnode01.log ceph-osd.0.log
ceph-client.rgw.cephnode01.log ceph-mds.cephnode01.log ceph-mon.cephnode01.log ceph-volume.log注:一般 metadata pool 可以从相对较少的 PGs 启动, 之后可以根据需要增加 PGs. 因为 metadata pool 存储着 CephFS文件的元数据, 为了保证安全, 最好有较多的副本数. 为了能有较低的延迟, 可以考虑将 metadata 存储在 SSDs 上.
2、创建一个 CephFS, 名字为 cephfs:需要指定两个创建的pool的名字
#ceph fs new cephfs cephfs-metadata cephfs-data
new fs with metadata pool 7 and data pool 63、验证至少有一个 MDS 已经进入 Active 状态,也就是活跃
另外可以看到两个备用的是cephnode01,和cephnode03
#ceph fs status cephfs
cephfs - 0 clients
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 1536k | 17.0G |
| cephfs-data | data | 0 | 17.0G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode01 |
| cephnode03 |
+-------------+
MDS version: ceph version 14.2.7 (3d58626ebeec02d8385a4cefb92c6cbc3a45bfe8) nautilus (stable)4、在 Monitor 上, 创建一个叫client.cephfs的用户,用于访问CephFs
#ceph auth get-or-create client.cephfs mon 'allow r' mds 'allow rw' osd 'allow rw pool=cephfs-data, allow rw pool=cephfs-metadata'
这里会生成一个key,用户需要拿这个key去访问
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==查看权限列表,有哪些用户创建了权限
[root@cephnode01 my-cluster]# ceph auth list
client.cephfs
key: AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps: [mds] allow rw
caps: [mon] allow r
caps: [osd] allow rw pool=cephfs-data, allow rw pool=cephfs-metadata
client.rgw.cephnode01
key: AQBOAl5eGVL/HBAAYH93c4wPiBlD7YhuPY0u7Q==
caps: [mon] allow rw
caps: [osd] allow r5、验证key是否生效
#ceph auth get client.cephfs
可以看到这个用户是拥有访问cephfs的读写权限的
exported keyring for client.cephfs
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"6、检查CephFs和mds状态
#ceph -s 查看集群已经增加mds配置
cluster:
id: 75aade75-8a3a-47d5-ae44-ec3a84394033
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 2h)
mgr: cephnode01(active, since 2h), standbys: cephnode02, cephnode03
mds: cephfs:1 {0=cephnode02=up:active} 2 up:standby
osd: 3 osds: 3 up (since 2h), 3 in (since 2h)
rgw: 1 daemon active (cephnode01)
data:
pools: 7 pools, 96 pgs
objects: 263 objects, 29 MiB
usage: 3.1 GiB used, 54 GiB / 57 GiB avail
pgs: 96 active+clean
#ceph mds stat
这里显示1个是active状态,2个备用状态
cephfs:1 {0=cephnode02=up:active} 2 up:standby
#ceph fs ls
这里有两个pool
name: cephfs, metadata pool: cephfs-metadata, data pools: [cephfs-data ]
#ceph fs status1.1 以 kernel client 形式挂载 CephFS
这里使用其他的机器进行挂载,这里是是以prometheus主机挂载,不过这个在哪挂载都可以,kernel主要联系系统内核,和系统内核进行做相互,用这种方式进行挂载文件系统
1、创建挂载目录 cephfs#mkdir /cephfs
2、挂载目录,这里写集群ceph节点的地址,后面跟创建用户访问集群的key
#mount -t ceph 192.168.1.10:6789,192.168.1.11:6789,192.168.1.12:6789:/ /cephfs/ -o name=cephfs,secret=AQDHjeddHlktJhAAxDClZh9mvBxRea5EI2xD9w==3、自动挂载#echo "mon1:6789,mon2:6789,mon3:6789:/ /cephfs ceph name=cephfs,secretfile=/etc/ceph/cephfs.key,_netdev,noatime 0 0" | sudo tee -a /etc/fstab
4、验证是否挂载成功
#stat -f /cephfs
文件:"/cephfs"
ID:4f32eedbe607030e 文件名长度:255 类型:ceph
块大小:4194304 基本块大小:4194304
块:总计:4357 空闲:4357 可用:4357
Inodes: 总计:0 空闲:-11.2 以 FUSE client 形式挂载 CephFS
1、安装ceph-common,安装好可以使用rbd,ceph相关命令
这里还是使用我们的内网yum源来安装这些依赖包
yum -y install epel-release
yum install -y ceph-common2、安装ceph-fuse,ceph的客户端工具,也就是用ceph的方式把这个文件系统挂上yum install -y ceph-fuse
3、将集群的ceph.conf拷贝到客户端
scp [email protected]:/etc/ceph/ceph.conf /etc/ceph/
chmod 644 /etc/ceph/ceph.conf4、使用 ceph-fuse 挂载 CephFS
如果是在其他主机挂载的话,需要这个使用cephfs的key,这个是刚才我们创建好的
直接拿这台服务器上用就可以
[root@prometheus ~]# more /etc/ceph/ceph.client.cephfs.keyring
exported keyring for client.cephfs
[client.cephfs]
key = AQA5IV5eNCwMGRAAy4dIZ8+ISfBcwZegFTYD6Q==
caps mds = "allow rw"
caps mon = "allow r"
caps osd = "allow rw pool=cephfs-data, allow rw pool=cephfs-metadata"
#ceph-fuse --keyring /etc/ceph/ceph.client.cephfs.keyring --name client.cephfs -m 192.168.1.10:6789,192.168.1.11:6789,192.168.1.12:6789 /cephfs/5、验证 CephFS 已经成功挂载
#df -h
ceph-fuse 18G 0 18G 0% /cephfs
#stat -f /cephfs
文件:"/cephfs/"
ID:0 文件名长度:255 类型:fuseblk
块大小:4194304 基本块大小:4194304
块:总计:4357 空闲:4357 可用:4357
Inodes: 总计:1 空闲:06、自动挂载
#echo "none /cephfs fuse.ceph ceph.id=cephfs[,ceph.conf=/etc/ceph/ceph.conf],_netdev,defaults 0 0"| sudo tee -a /etc/fstab
或
#echo "id=cephfs,conf=/etc/ceph/ceph.conf /mnt/ceph2 fuse.ceph _netdev,defaults 0 0"| sudo tee -a /etc/fstab7、卸载#fusermount -u /cephfs
五、MDS主备与主主切换
1、配置主主模式
当cephfs的性能出现在MDS上时,就应该配置多个活动的MDS。通常是多个客户机应用程序并行的执行大量元数据操作,并且它们分别有自己单独的工作目录。这种情况下很适合使用多主MDS模式。
配置MDS多主模式
每个cephfs文件系统都有一个max_mds设置,可以理解为它将控制创建多少个主MDS。注意只有当实际的MDS个数大于或等于max_mds设置的值时,mdx_mds设置才会生效。例如,如果只有一个MDS守护进程在运行,并且max_mds被设置为两个,则不会创建第二个主MDS。
添加设置max_mds 2,也就是成2个activity,1个standby,称为主主备模式
#ceph fs set cephfs max_mds 2
[root@cephnode01 ceph]# ceph fs status
cephfs - 1 clients
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 11 | 14 |
| 1 | active | cephnode01 | Reqs: 0 /s | 10 | 13 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 2688k | 16.8G |
| cephfs-data | data | 521M | 16.8G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode03 |
+-------------+也就是当你cephfs用的多的话,数据量大的话,就会出现性能的问题,也就是当配置多个avtive的mds的时候会遇到系统瓶颈,这个时候就需要配置主主模式,把这个数据做一个类似的负载均衡,多主的话也就是这些主会同时提供服务
# 1.3、配置备用MDS
即使有多个活动的MDS,如果其中一个MDS出现故障,仍然需要备用守护进程来接管。因此,对于高可用性系统,实际配置max_mds时,最好比系统中MDS的总数少一个。
但如果你确信你的MDS不会出现故障,可以通过以下设置来通知ceph不需要备用MDS,否则会出现insufficient standby daemons available告警信息:
#ceph fs set <fs> standby_count_wanted 0
2、还原单主MDS
2.1、设置max_mds
要是还原的话,直接设置为max_mds 1也就是一个activity两个standby
#ceph fs set max_mds 1
[root@cephnode01 ceph]# ceph fs status
cephfs - 1 clients
======
+------+--------+------------+---------------+-------+-------+
| Rank | State | MDS | Activity | dns | inos |
+------+--------+------------+---------------+-------+-------+
| 0 | active | cephnode02 | Reqs: 0 /s | 11 | 14 |
+------+--------+------------+---------------+-------+-------+
+-----------------+----------+-------+-------+
| Pool | type | used | avail |
+-----------------+----------+-------+-------+
| cephfs-metadata | metadata | 2688k | 16.8G |
| cephfs-data | data | 521M | 16.8G |
+-----------------+----------+-------+-------+
+-------------+
| Standby MDS |
+-------------+
| cephnode03 |
| cephnode01 |
+-------------+如果想在客户端去执行相关的ceph命令的话,需要安装ceph-common以及ceph-fuse客户端工具将这个ceph.client.admin.keyring以及ceph.conf文件拷到相应的客户端也可以执行ceph命令了
[root@cephnode01 ceph]# scp ceph.client.admin.keyring [email protected]:/etc/ceph
[email protected]'s password:
ceph.client.admin.keyring
[root@prometheus ceph]# ceph -s
cluster:
id: 75aade75-8a3a-47d5-ae44-ec3a84394033
health: HEALTH_OK
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 4h)
mgr: cephnode01(active, since 4h), standbys: cephnode02, cephnode03
mds: cephfs:2 {0=cephnode02=up:active,1=cephnode03=up:active} 1 up:standby
osd: 3 osds: 3 up (since 4h), 3 in (since 4h)
rgw: 1 daemon active (cephnode01)
data:
pools: 7 pools, 96 pgs
objects: 345 objects, 203 MiB
usage: 3.6 GiB used, 53 GiB / 57 GiB avail
pgs: 96 active+clean