摘要
最近的研究成果证明只要在网络靠近输入层和输出层之间建立short connections,就可以高效地训练一个足够深、足够精确的CNN网络。本文中,作者基于上述观察提出了DenseNet,该网络中任意两个层之间都包含short connection,所以DenseNet共包含了L(L+1)/2个direct connections。对于每一个网络层,它前面所有的层的feature maps都是它的输入,它自身的feature map也都是它后面所有网络层的输入。
使用DenseNet,有几个好处,一是减轻了梯度弥散;二是加强了特征的传播;三是鼓励了特征复用;四是减少了参数数量。
在cifar10,cifar100,svhn和ImageNet数据集上都证明了网络的良好的目标分类效果,在需要更小的计算量的情况下取得了state-of-art的效果。
代码和模型:https://github.com/liuzhuang13/DenseNet
简介
CNN网络深度变大之后,会造成一个新的问题:输入信号或者梯度传播过很多层之后,会造成弥散,无法传播到应该到的输出层或输入层。
最近很多文献都在致力于解决上述问题,ResNet和Highway Network是在一个网络层和它的下一层之间加入了identity connection;Stochastic depth网络是在训练ResNet网络的过程中随机drop一些层以便于更好的进行数据和梯度的传递;FractalNets网络是持续的结合一些并行的层序列以扩展网络的宽度,同时在网络上设置一些short path。虽然上述几种网络做法各异,但是他们之间有一些共通点就是在网络的前面层和后面层之间创建short path。
本文中,作者更是沿着这种思路做到了极致,就是在网络中所有的层之间两两连接以实现最大的信息流动。如下图所示,每一个层前面所有层的输出都是该层的输入。
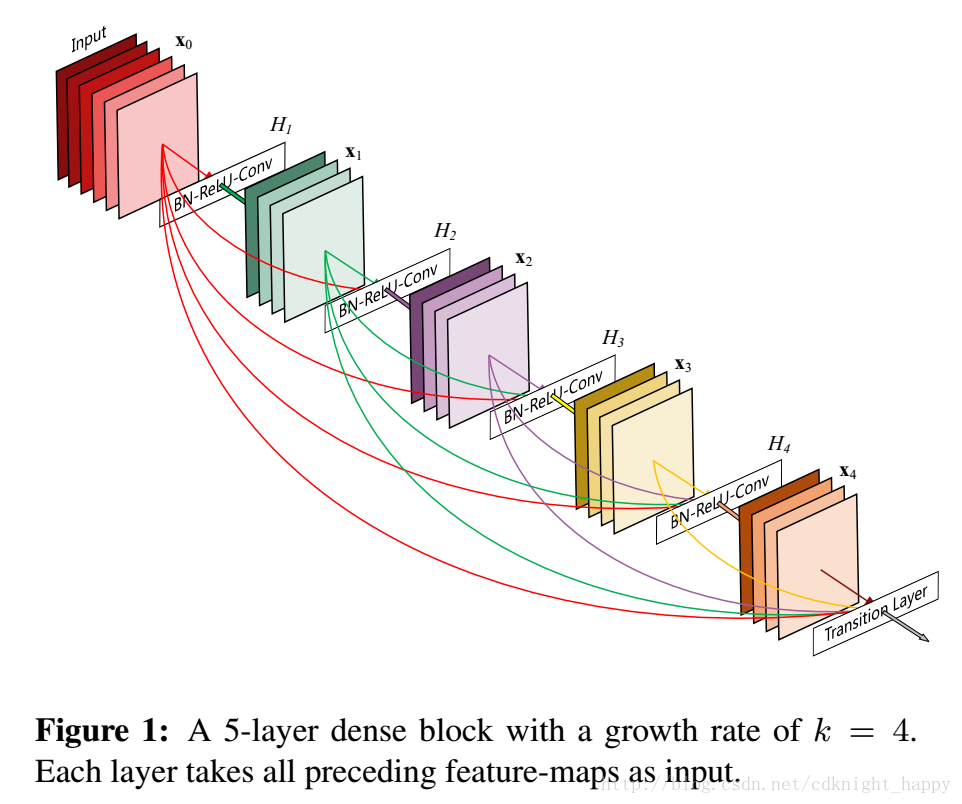
所以在网络中一共有L(L+1)/2个连接,这也是DenseNet名字的由来。
DenseNet网络的优点:
- 一种反直觉的现实是DenseNet网络需要的参数数量更少,这是因为这种连接方式下,每一层就不需要那么多的feature map了。
- 另外一个好处是,DenseNet网络改善了信息和梯度在网络中的传输,这是因为每一个层都有和输入层及输出层直连的通道,leading to an implicit deep supervision。这样发生梯度弥散的风险会减小,有助于训练更深的网络。
- 另外,作者还发现DenseNet网络有一定的正则化的作用,减小了训练样本不足时过拟合的风险。
DenseNets
DenseNet和ResNet的对比:
- ResNet
ResNet的好处是梯度可以通过恒等映射从下一层传递到当前层,防止了梯度弥散;但不好的地方是Hl 和恒等映射相加的过程可能会阻碍网络中信息的传递。 - DenseNet DenseNet通过dense connectivity方式改善了层与层之间的信息传播。如figure1所示,
第l 层的输入是它前面所有的l−1 层的concatenation。 上图中的H(.) 表示BN层+ReLU+3*3的conv。
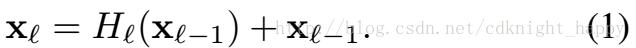
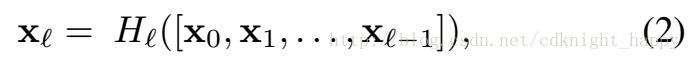
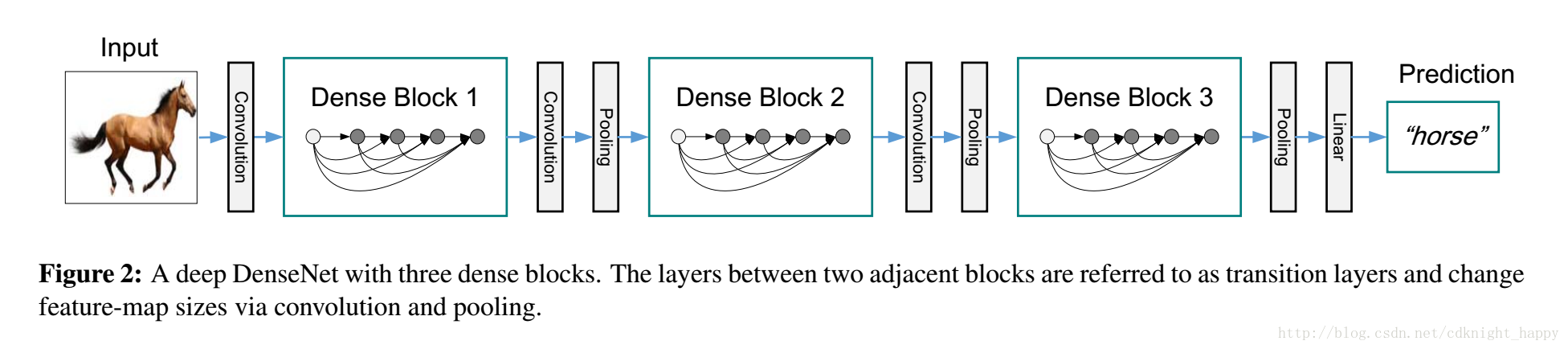
Pool层:上式中如果有feature map尺寸的改变,那么直接的相加操作是无法进行的,因此作者就在两个相邻的dense block之间加入了通过BN层、1*1卷积层和2*2平均池化层实现的transition layer,如下图所示。
Growth rate:假如每一个函数
Bottleneck layers:虽然每个层只产生k个新的feature map,但是层数多了之后,累积的feature map数量还是很多的。正如其他文献所说,可以在3*3的卷积前使用1*1的卷积用作bottleneck层以减少输入feature map的数量,以增强计算效率。作者发现这种方式对DenseNet特别有效,也就是作者在DenseNet-B网络中使用BN-ReLU-Conv(1*1)-BN-ReLU-Conv(3*3)作为
网络压缩:为了进一步简化网络,可以在transition层中进一步减少feature map的数量。如果一个dense block有m个feature map,紧接的tranision层产生
实现细节:
对CIFAR-10,CIFAR-100,SVNH数据集:
- 三个同样层数的dense block;
- 输入图像送入网络之前先经过一个输出channel为16(对DenseNet-BC网络,该卷积层的输出channel为2*growth rate)的卷积层;
- 3*3的卷积层使用size为1的zero-padding以保证输出大小不变;
- 两个相连的dense block之间使用1*1卷积和2*2平均池化作为transition layer;
- 在最后一个dense block后,使用平均池化层+softmax分类器;
- 三个dense block输出的feature map的size分别为32*32,16*16,8*8;
-实验了多种超参数组合的网络,分别是{L=40,k=12},{L=100,k=12},{L=100,k=24};对于DenseNet-BC,有{L=100,k=12},{L=250,k=24},{L=190,k=40}。
对ImageNet数据集,使用DenseNet-BC网络,四个dense block,输入图像224*224,初始卷积层7*7,stride = 2,2000个卷积核。具体网络结构如下表:
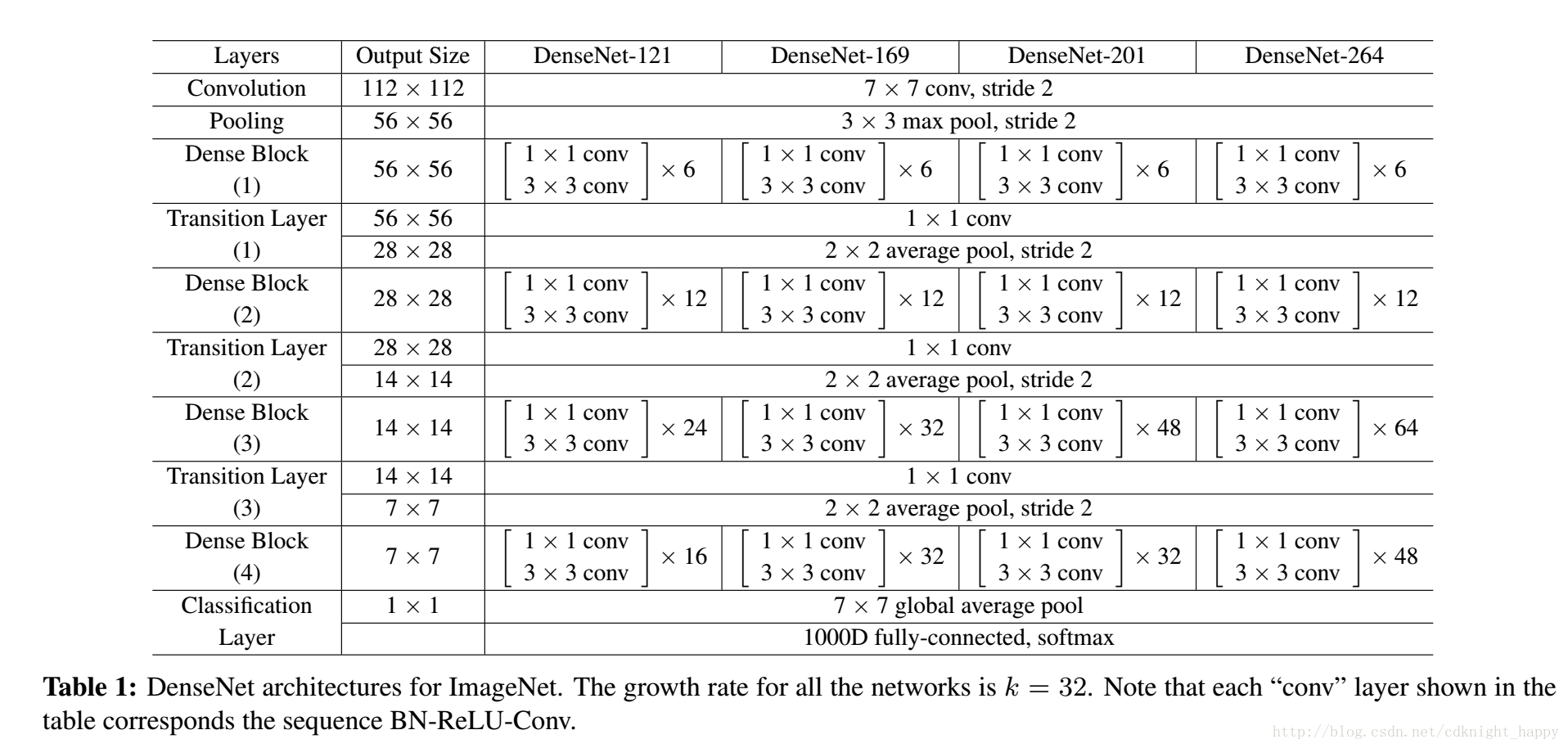
实验
《Memory-efficient implementation of densenets》给出了高效率的实现方法。
cifar & SVNH:
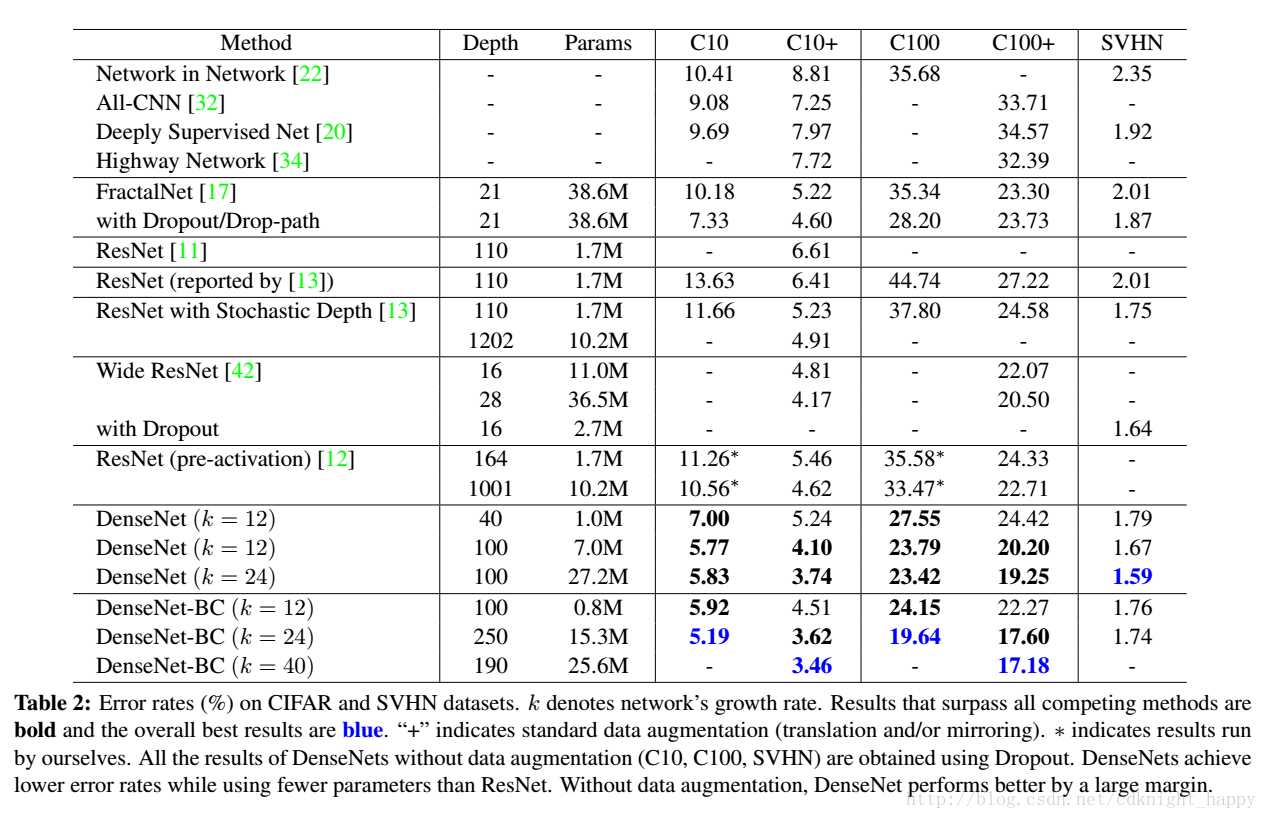
未做模型压缩时,L和k越大,效果越好,说明DenseNet已经不存在拟合和难以最优化的问题;
取得相当效果时,网络的参数更少;
ImageNet:

和ResNet相比,同等效果下,参数数量和计算量明显更小。
讨论
DenseNet相比ResNet就是将相加变成了concatenation,但却取得了更好的效果。

左边的图表示不同类型DenseNet的参数和error对比。中间的图表示DenseNet-BC和ResNet在参数和error的对比,相同error下,DenseNet-BC的参数复杂度要小很多。右边的图也是表达DenseNet-BC-100只需要很少的参数就能达到和ResNet-1001相同的结果。
深度监督:分类器和每一个隐藏层都存来连接,因此逼迫中间层去学习更加有判别力的特征。
随机 vs. 确定性连接:在stochastic depth中,residual中的layers在训练过程中会被随机drop掉,其实这就会使得相邻层之间直接连接,这和DenseNet是很像的。
特征复用:
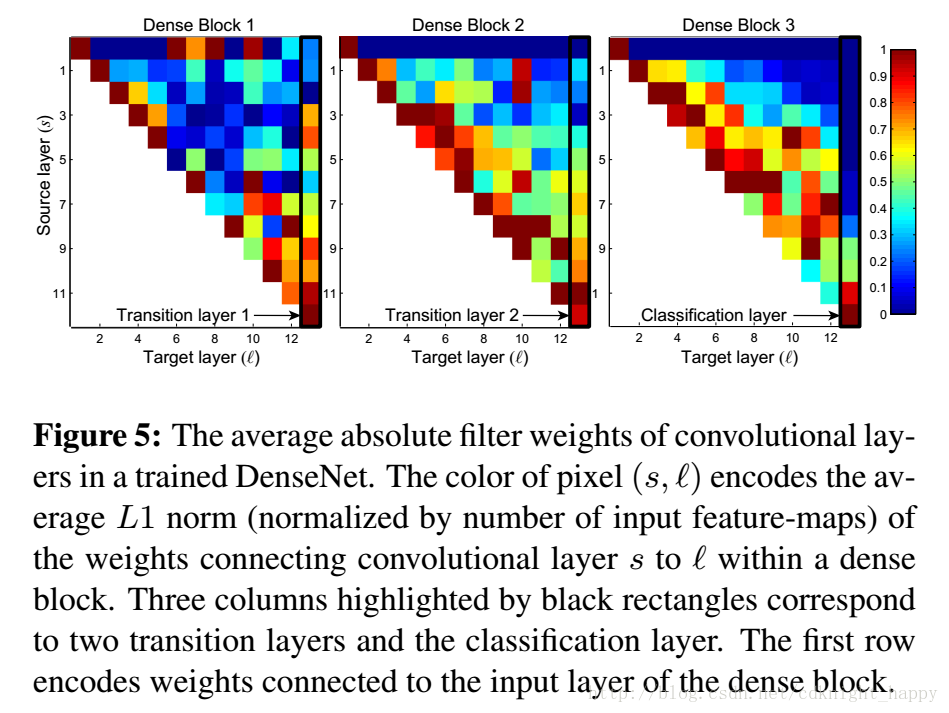
同一个dense block内的后面的层的确使用了前面层的特征;
同样也存在一些非直接的信息流动的影响;
transition layer可以压缩特征;
网络的后面产生了很多high-level的特征。
疑问:DenseNet在小的数据集上效果超过了ResNet,但为什么在ImageNet上不如ResNet,虽然说差距很小。
总结
简单的思路变换之后,特征复用了,梯度弥散不是问题了,很小的growth rate也可以取得很好的效果,参数数量和RestNet相比很小的时候也可以取得相当的效果,过拟合的风险小了。并且使用transition layer可以进一步的对模型参数进行压缩。作者下一步想实验把DenseNet作为计算机视觉领域通用的特征提取器,期待基于DenseNet能够对计算机视觉领域有更好的进展。