文章目录
数据准备 + 理论基础
数据
-- ----------------------------
-- Table structure for employee
-- ----------------------------
DROP TABLE IF EXISTS `employee`;
CREATE TABLE `employee` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(24) DEFAULT '' COMMENT '姓名',
`age` int(11) NOT NULL DEFAULT '0' COMMENT '年龄',
`pos` varchar(20) NOT NULL DEFAULT '' COMMENT '职位',
`add_time` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '入职时间',
PRIMARY KEY (`id`), -- 主键索引
KEY `idx_name_age_pos` (`name`,`age`,`pos`) -- 联合索引
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8 COMMENT='员工记录表';
-- ----------------------------
-- Records of employee
-- ----------------------------
INSERT INTO `employee` VALUES ('1', 'Lily', '22', 'manager', '2020-03-02 18:08:11');
INSERT INTO `employee` VALUES ('2', 'Lucy', '23', 'dev', '2020-03-02 18:08:11');
INSERT INTO `employee` VALUES ('3', '2000', '23', 'dev', '2020-03-02 18:08:11');
INSERT INTO `employee` VALUES ('4', null, '23', 'dev', '2020-03-02 18:08:12');
理论基础
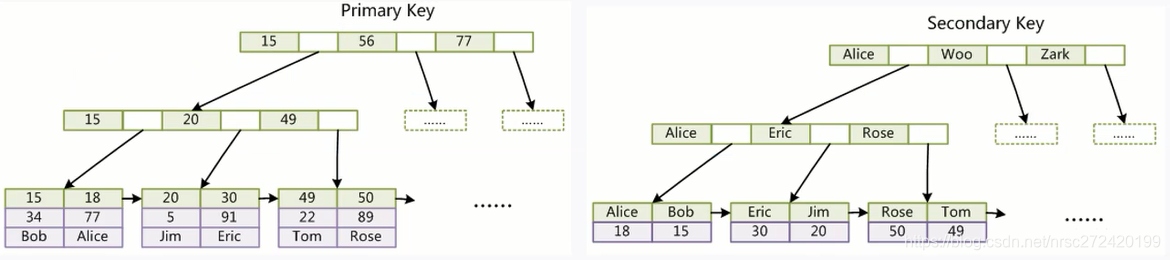
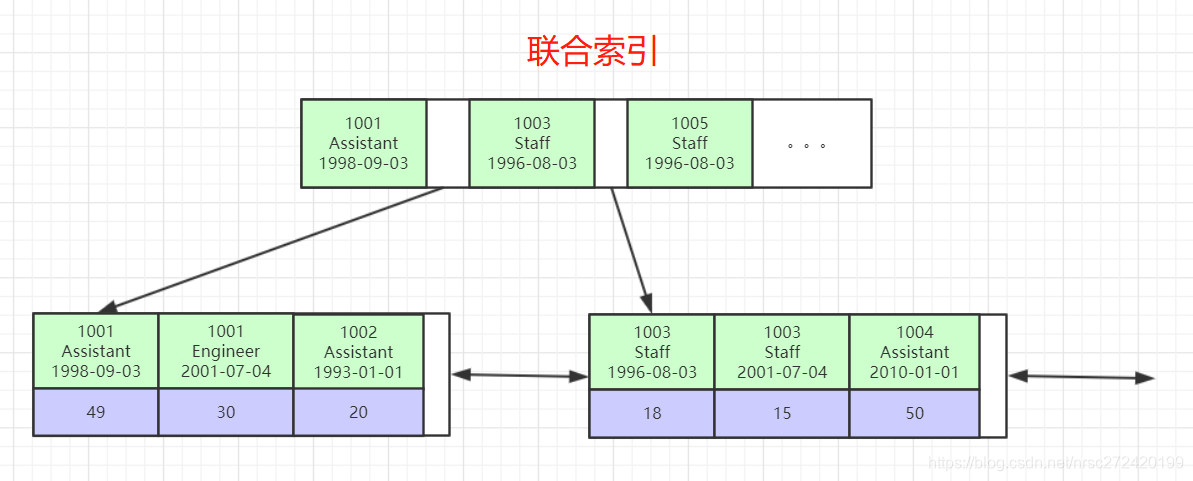
策略1 — 尽量全职匹配
这里一定要结合联合索引的数据结构去理解
explain select * from employee where name = 'Lily';
explain select * from employee where name = 'Lily' and age =10;
explain select * from employee where name = 'Lily' and age =10 and pos = 'dev';
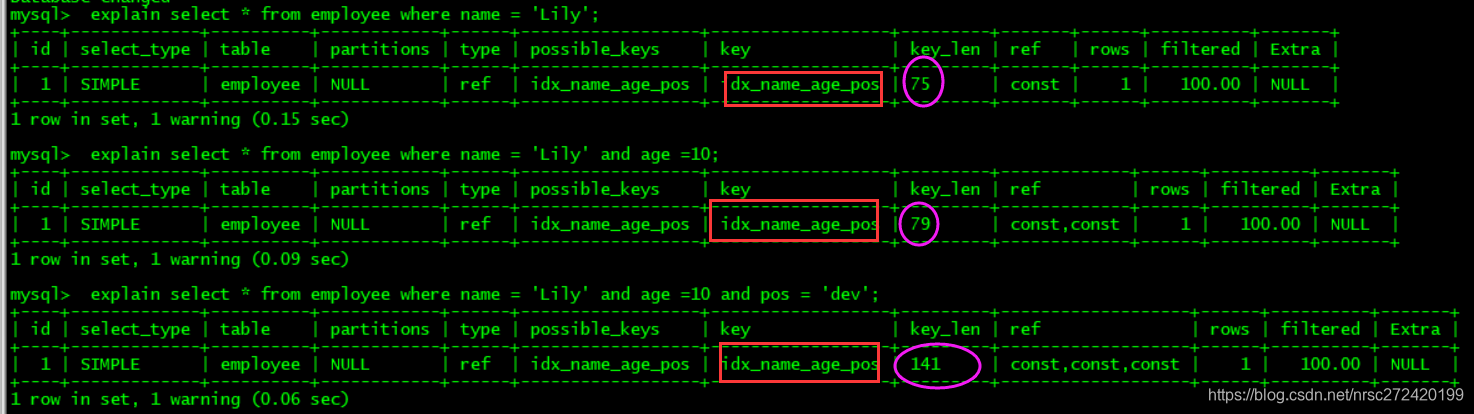
三条语句都用了索引,但是索引使用率最高的为全值索引。
策略2 — 最佳左前缀法则
如果索引为联合索引,要遵守最佳左前缀法则 —>查询从索引的最左列开始并且不跳过索引中的列。
EXPLAIN SELECT * FROM employee WHERE age = 25 AND pos = 'dev'; -- 跳过了最左边的列name不会走索引
EXPLAIN SELECT * FROM employee WHERE pos = 'dev'; -- 跳过了最左边的列name和age更不会走索引
EXPLAIN SELECT * FROM employee WHERE NAME = 'July'; -- 有最左边的列可以走索引
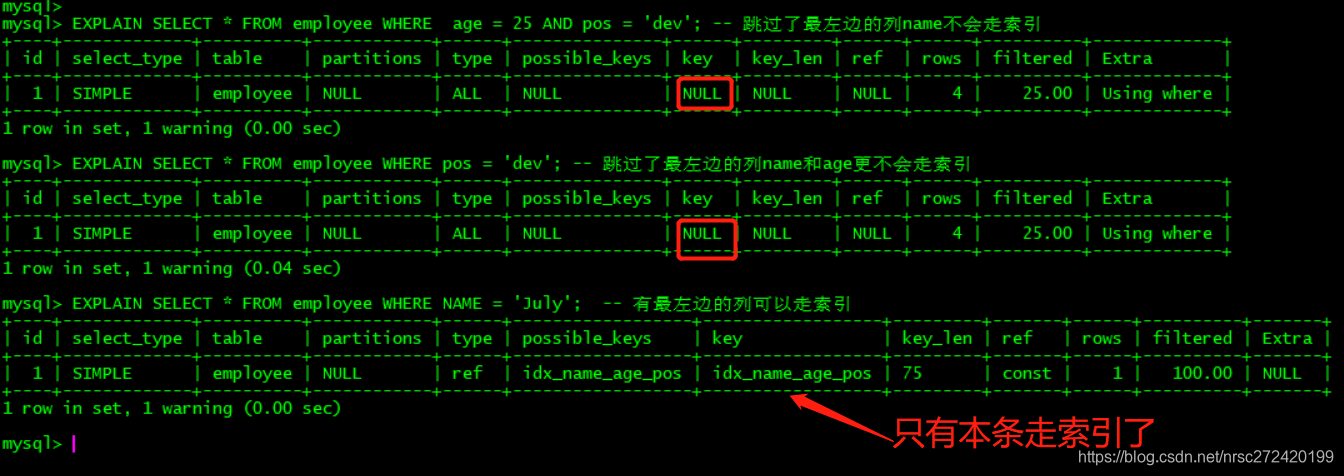
但上面的法则也会不是绝对的,比如下面这两种情况:
EXPLAIN SELECT * FROM employee WHERE NAME = 'July' and pos = 'dev' and age =25 ;
EXPLAIN SELECT pos,age,name,id FROM employee WHERE pos = 'dev' and age =25;
- 第一条语句之所以走了索引,是因为mysql优化器对sql进行了优化;
- 第二条语句之所以走索引,则是因为查询的内容完全隐藏在了联合索引的数据结构中 — 即用了覆盖索引。 —
强调一遍,懂了联合索引的底层数据结构,这里就很容易理解了。

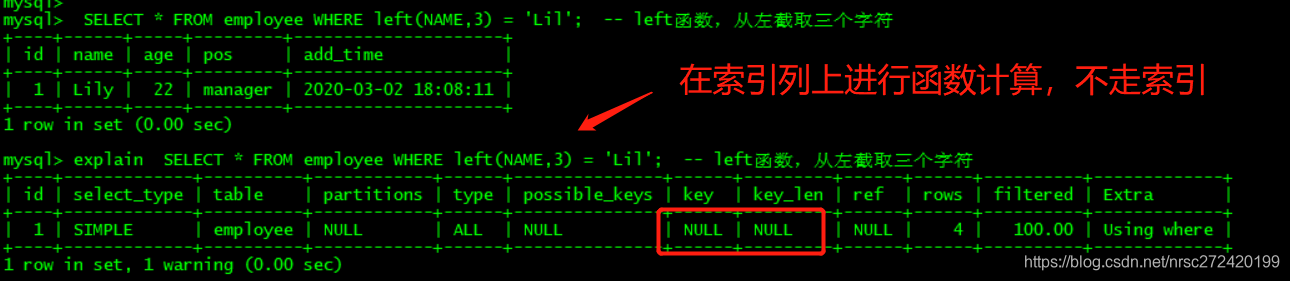
策略3 — 不要在索引列上做任何操作
不要在索引列上做任何操作(计算、函数、(自动or手动)类型转换)—> 会导致索引失效而转向全表扫描。
EXPLAIN SELECT * FROM staffs WHERE left(NAME,3) = 'Lily'; -- left 函数,从左截取三个字符
策略4 — 范围条件放最后
存储引擎不能使用索引中范围条件右边的列 — 可以从联合索引底层数据结构的角度想一想为什么。。。
EXPLAIN SELECT * FROM employee WHERE NAME = 'July';
EXPLAIN SELECT * FROM employee WHERE NAME = 'July' and age =22;
EXPLAIN SELECT * FROM employee WHERE NAME = 'July' and age =22 and pos='manager';
EXPLAIN SELECT * FROM employee WHERE NAME = 'July' and age > 18 and pos='manager';

策略5 — 覆盖索引尽量用
这个在策略2中就提到了,主要还是得明白联合索引的底层数据结构。
这里就不举例子了。
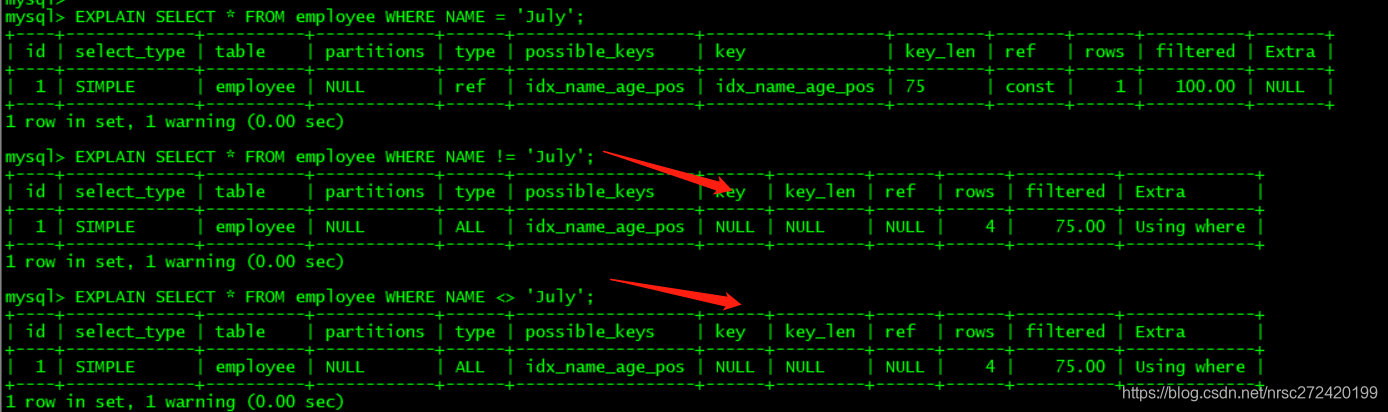
策略6 — 不等于要甚用
mysql 在使用不等于(!= 或者<>)的时候无法使用索引会导致全表扫描
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME != 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME <> 'July';
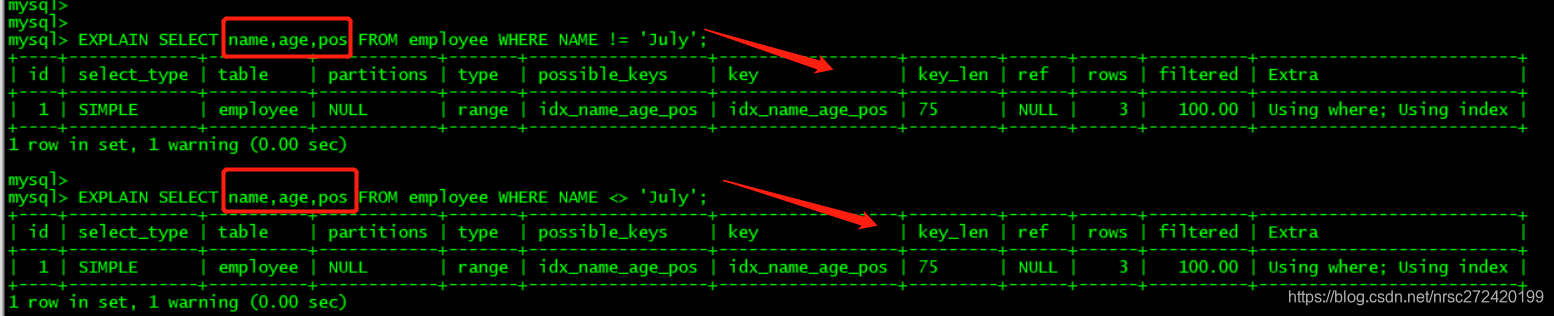
当然,如果你非要用—> 请用
覆盖索引
EXPLAIN SELECT name,age,pos FROM employee WHERE NAME != 'July';
EXPLAIN SELECT name,age,pos FROM employee WHERE NAME <> 'July';
策略7 — is null(使用)、is not null(不使用)有影响
一般情况下is not null无法使用索引,但是is null是可以使用索引的
因为null 会参与引索引的B+树结构构建,所以通过is null是可以遍历索引树的
is not null —> 可以与不等于归为一类。
EXPLAIN select * from employee where name is null;
EXPLAIN select * from employee where name is not null;

二般情况下 --> 覆盖索引
EXPLAIN select name,age,pos from employee where name is not null;

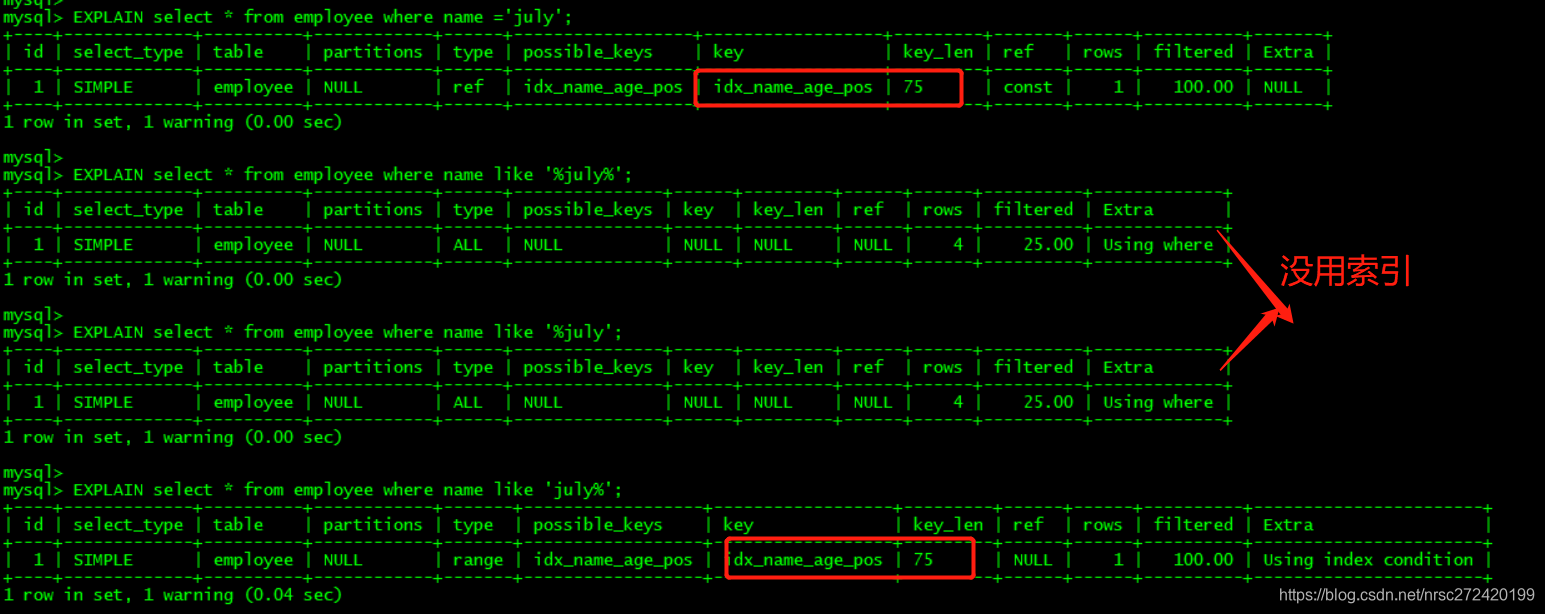
策略8 — Like查询要当心
like以通配符开头如:’%abc…’ , 索引会失效—>变成全表扫描
但以确定的字符开头,会走索引
EXPLAIN select * from employee where name ='july';
EXPLAIN select * from employee where name like '%july%';
EXPLAIN select * from employee where name like '%july';
EXPLAIN select * from employee where name like 'july%';
如何让以通配符开头的like走索引呢,其实很简单,还是得靠
覆盖索引
EXPLAIN select name,age,pos from employee where name like '%july%'

策略9 — 字符类型加引号(切记)
如果本来为字符类型,但是如果忘记加引号,会导致索引失效:
EXPLAIN select id,name,age,pos from employee where name = 917;

策略10 — OR改UNION效率高
少用or,用它来连接时会索引失效 —>可以用union代替
EXPLAIN select * from employee where name='July' or name = 'z3';
EXPLAIN
select * from employee where name='July'
union
select * from employee where name = 'lisi';
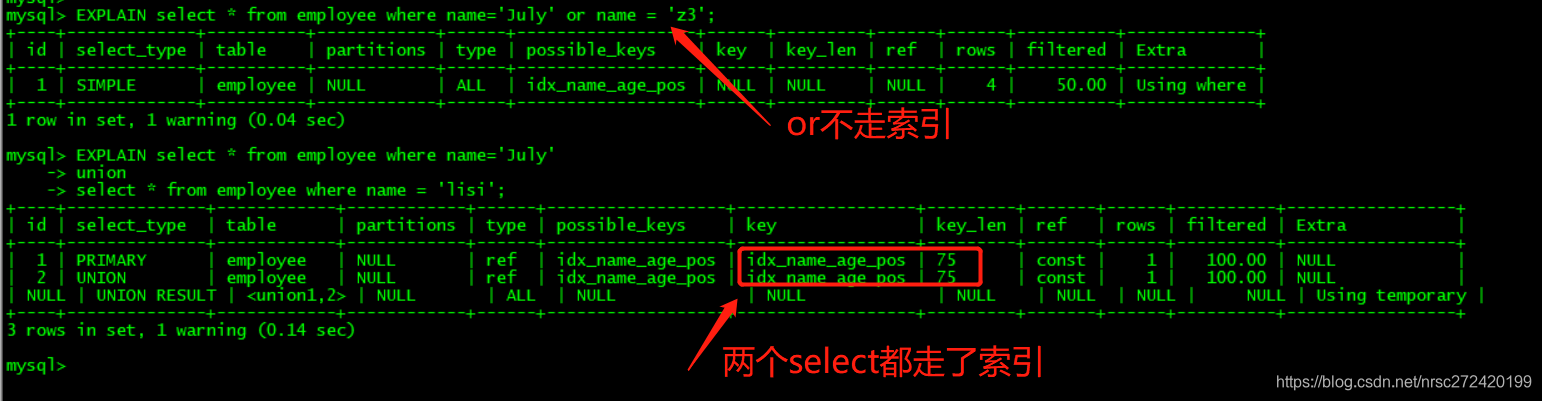
但是通过其底层数据结构,我们可以想到,这种优化应该是几乎起不了什么作用的 — 有兴趣的可以展开想一下。
想要真正优化上诉问题,还是得走覆盖索引。
这些所谓策略其实我觉得根本都不用记 —> 只要知道聚簇索引、回表查询和联合索引的数据结构,一分析就都可以明白了。。。
