HEVC标准已经公开,我想趁此机会用简单的语言来阐释HEVC编码的工作原理。
图像划分
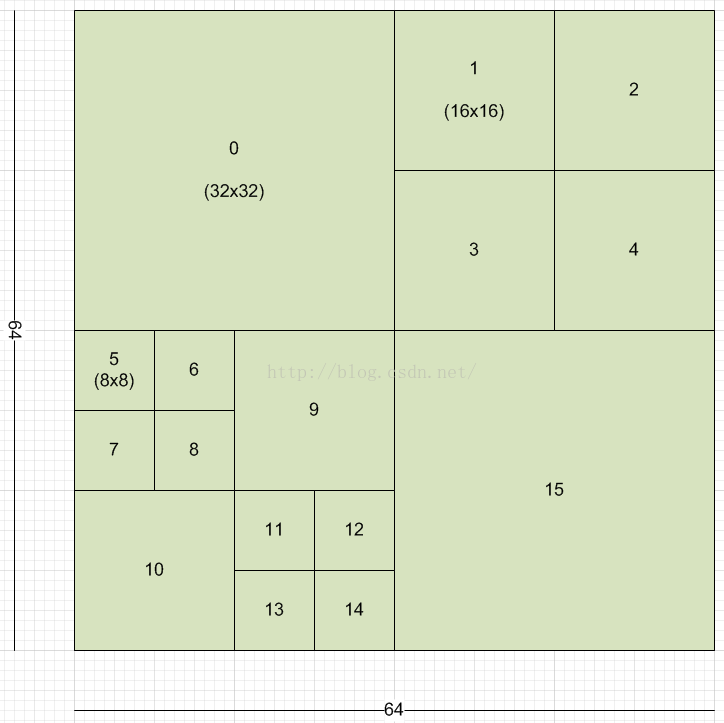
与AVC中的宏块类似,HEVC图像划分成coding tree blocks(CTBs),它们按光栅扫描的顺序排列。根据流参数,它们的大小可以是64*64、32*32或者16*16。每个CTB又可以重复划分成四叉树的结构,直至8*8大小。以32*32大小的CTB为例,它可能包含3个16*16和4个8*8大小的区域。这些区域就叫做coding units(CUs)。CUs是HEVC预测的基本单元。如果你之前有关注过,应该知道CUs大小可以是64*64、32*32、16*16、8*8。采用Z-order遍历和编码CUs。64*64大小的CTB遍历顺序如下图所示:
和在AVC中一样,一个CTBs序列叫做一个slice。一幅图片可以划分成很多个slice,也可以整个图像就是一个slice。接下来,每个slice又可以划分成一个或多个slice segment,每个slice有自己的NAL unit。只有每个slice的第一个slice segment才会包含全部的slice header,余下的其他segment都是关联性slice segments。关联性slice segment是不能自行解码的,解码器必须从这个slice的首个slice segment开始。slice的这种划分方式能够满足图像的低延迟传输需求,而且其编码效率丝毫不逊使用大量全slices的情形。举个例子,一台摄像机可以将第一个CTB行以一个slice segment的形式发出,这时位于网络另一端的播放设备就可以开始绘制图像,而不必等到摄像机完成第二行CTB的编码才开始。在低延时的视频会议应用中,这项特点是非常有用的。
HEVC不支持任何形式的交错工具。依然可以对分层视频进行编码,但是必须以场图像序列的形式。不能混淆场合帧图像。
残差编码
每个CU都有一个残差信号需要编码。HEVC支持四种变换尺寸:4*4、8*8、16*16和32*32. 与AVC一样,这种变换是基于DCT(离散余弦变换)的整型变换。但是,帧内4*4的变换是基于DST(离散正弦变换)的。不存在类似AVC中的Hadamard-变换。基础矩阵使用的各系数要求7位存储器,所以它比AVC要更精确一些。更高的精度和更大变换尺寸是HEVC表现优于AVC的主要原因之一。
一个CU的残差信号包含一个或多个变换单元(TUs),CU按照类似于CTB划分的方式重复划分,最小块是4*4,也就是最小的TU。举例来说,一个16*16的CU可能包含3个8*8和4个4*4 TUs。每个亮度TU都有一个对应的四分之一大小的色度TU,也就是说一个16*16的亮度TU伴随两个8*8色度TUs。因为没有64*64变换,一个64*64的CU必须被划分至少一次,也就是划分成4个32*32 TUs。只有对skipped CU例外,因为这种情况下根本就没有残差信号。注意,没有2*2的色度TU尺寸。因为最小的可能CU是8*8,而在这个8*8的区域内至少要有4个亮度TUs,因此这个区域包含4个4*4亮度块和2个4*4色度块(而不是8个2*2)。和一个CTB中的CUs类似,一个CU内的TUs也是按照Z-order遍历的。
对于4*4大小的TU,编码器会提供“transform skip”的标识项,这时变换只需要全部忽略即可,而这时传递的系数实际上就只有空间残差取样值。举例来说,这对编码松散的小文本是有帮助的。
反量化基本与AVC相同。
TUs系数编码的方式在这里与AVC是有很大区别的。首先,比特流标记最后一个xy位置,从而指示扫描顺序中最后一个系数的位置。然后,解码器从这个位置开始,向后扫描,直至到达(0,0)位置,也就是DC 系数。所有系数成组为4*4系数组。组及每组系数均按对角线扫描(左下)。只要组内有系数,该比特流都会做标记。这样的话,比特流为组内的16个系数中的每一个都标记一位来指示哪些非零。然后,为组内的每个非零系数都做一个层记号。最后,组内所有的非零系数都会被解码,解码器开始对下一个组进行处理。HEVC有个可选工具叫‘符号位隐藏’。如果此项开启而且组内有足够的系数,那么有个符号位是不编码的而是推理出来。丢失的符号大致等于所有系数绝对值和的最重要位。也就是说,当编码器正在编码未知的系数组而参考符号不正确的时候,编码器不得不自下而上调整其中一个系数来修正它。这个选项工具起作用的原因在于符号位在省略模式(未压缩的)下会被编码,这样带来很大消耗。取消编码某些符号位带来的益处要优于因调整一个系数而导致的失真。
举例:一个16*16 TU的扫描过程

PUs
CU按照八种划分模式中的一种进行划分。为方便记忆,八种模式如下:2N*2N, 2N*N, N*2N, N*N,2N*nU,2N*nD,nL*2N,nR*2N。大写的N代表CU边长的一半,小写的n代表四分之一、一个32*32的CU,N=16, n=8。

如此,一个CU包含一个、两个或四个PU。需要注意的是,这种划分是不可重复的。一个CU要么是帧间要么是帧内编码,所以如果CU划分成两个PU,那么这两个PU要么都是帧间编码要么都是帧内编码。帧内编码的CUs可能只使用2N*2N或者N*N的划分模式,所以帧内PUs总是方形的。对于skipped的CU,它是帧间编码且采用2N*2N的划分模式。只有当CU是最小尺寸(即8*8)的情况下才允许使用N*N的划分模式。也就是说,如果你想在一个CU内有四个独立的预测,那么你也只能划分并(如果可以的话)创建四个独立的CU。同时。如果CU大小为8*8,帧间CUs是不允许N*N的,也就意味着根本不存在4*4运动补偿。最小的PB尺寸是8*4和4*8,而且这些不会是双向的、这样可以最小化最坏内存带宽(见下面运动补偿章节)。
帧内预测
CU内的帧内预测与TU tree完全一致、如果一个帧内CU采用N*N划分模式,那么对应地,TU tree也必须强制地至少分割一次以确保帧内和TU tree匹配。也就是说,帧内操作总是32*32, 16*16, 8*8, 4*4.
HEVC提供了35种不同的帧内模式,而AVC仅提供了9种。其中,33种是directional,另外还有一种DC和一种Planar模式。和AVC中一样,帧内预测要求两个一维数组分别存储上方和左侧相邻采样值、左上方采样值。这个数组是帧内block尺寸的两倍长,扩展到该block的下方和右侧。8*8 block的示例如下:
视帧内预测块位置的不同,有些相邻采样值是无法使用的。例如,它们可能位于图片外,或者位于另一个slice中,或者位于一个即将解码的CU中(因果不符)。不可得的采样值将按照既定的程序进行填充,之后这些相邻数组就填满了有效采样值。相邻数组将根据block的大小和帧内模式进行滤波(平滑)。
角度预测过程与AVC中类似,使用模式以及一种归一算法就可以处理所有的block size。除了33中角度预测模式外,还有一种DC模式,它仅使用一个单精度值来进行预测,而Planar模式则会对相邻的采样值做平滑梯度处理。
帧内模式编码通过构建一个由模式组成的3-条目列表来完成。左侧和上方模式,加上一些由它们产生的特殊的派生项,构成了3个独特的模式,进而生成了所需列表。如果列表中有理想模式,那么它的索引值被传送出去,否则这个模式会直接送出。
并行工具
HEVC提供了两个特别的工具以满足多线程解码器的设计需求,它可以使用多个线程解码单帧图像,这就是Tiles 和 WPP。
Tiles: 图像被划分成由CTBs组成的一系列矩形网格,最多20列、22行。每个tile包含整数个独立解码的CTBs。也就意味着运动矢量预测和帧内预测是不能够跨越边界执行的,就好像每个tile就是一幅单独的图像。针对这种独立性,唯一例外的是,两个环内滤波器仍可以跨边界进行。slice header包含每个tile的偏移字节,所以多个解码线程依然可以迅速寻觅到它们指定tile的起始位置。而单线程的解码器只需要按光栅扫描顺序逐一处理每个tile。那么,在slices和slice segments的配合下这个过程是如何实现的呢?为了避免过于复制的情形,HEVC规定:如果一个tile包含多个slice,那么这些slice中不能够有位于该tile外的CTBs。相反地,如果一个slice包含多个tile,那么,该slice必须从首个tile的首个CTB开始,以末尾tile的最后一个CTB结束。这些规则对关联性slice segments同样适用。每幅图像的tiles结构(大小和数目)都可以不同,这样能够保证多线程编码器更加灵活地实现负载均衡。
WPP: 每个CTB行可以使用自己的线程进行解码、当一个线程完成改行第二个CTB的解码时,该熵解码器的状态被保存下来并传给下一行。这时,下一行的线程就可以开始工作了。这种方式下不存在交错线程预测的依赖性问题。但是这种方式也要求细致的设计以确保底层的线程不至于前进太快。而且,存在线程内通信。
档次/级别
存在3种档次:Main, Main10和 Still Picture. 几乎所有的内容,只有Main档次会有用。它有些需要注意的限制条件:位深度为8;tiles大小至少是256*64,;tiles 和 WPP不能同时使用。
这里指定了许多级别,从1到6.2。 一个6.2级别的视频流可能是8192*4320@120fps。