表的范式,是首先符合1NF,才能满足2NF,进一步满足3NF
1NF: 即表的列具有原子性,不可再分解,即列的信息,不能分解,只要数据库是关系型数据库,就自动满足1NF。
2NF: 表中的记录是唯一的,就满足2NF,通常 我们设计主键来实现,主键一般不含业务逻辑,自增长。
3NF: 即表中不要有冗余数据,比如下面就不符合3NF
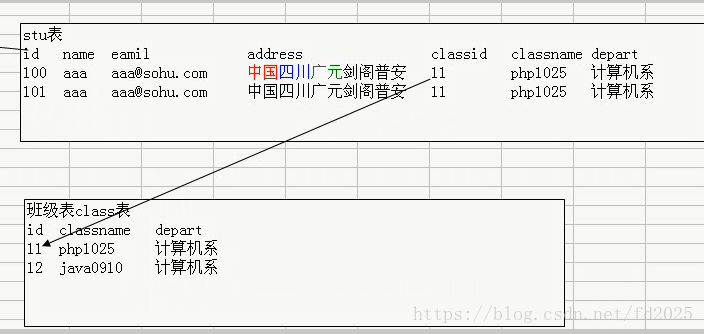
应该这样去设计:

反3NF:没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,允许冗余。
适合冗余的案例:
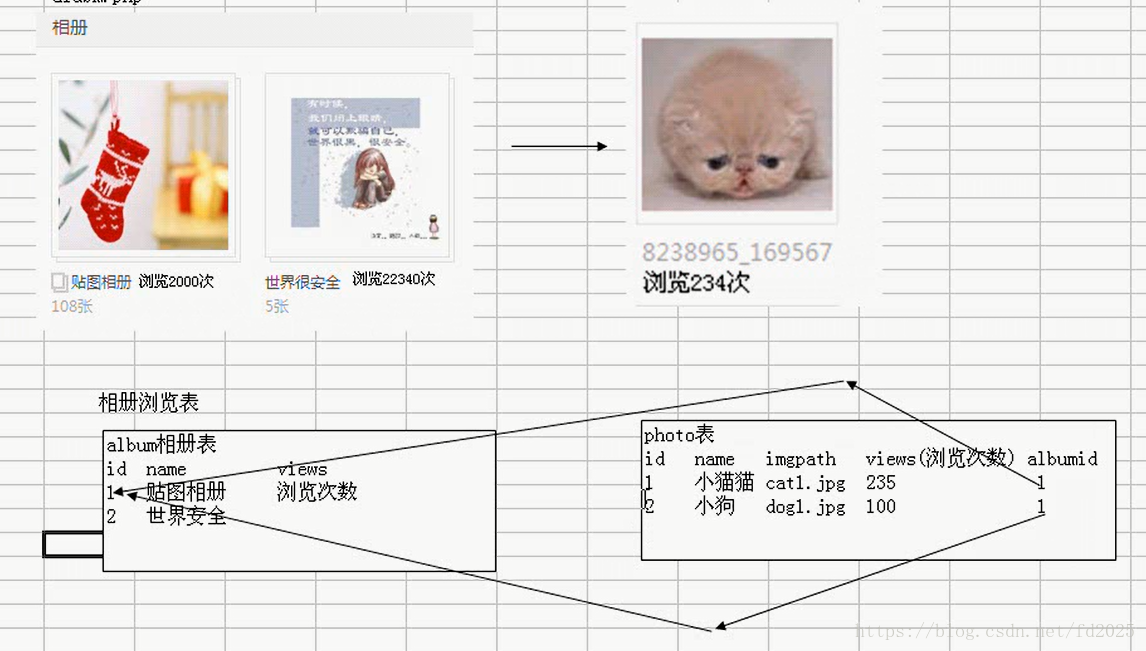
不适合冗余的案例:
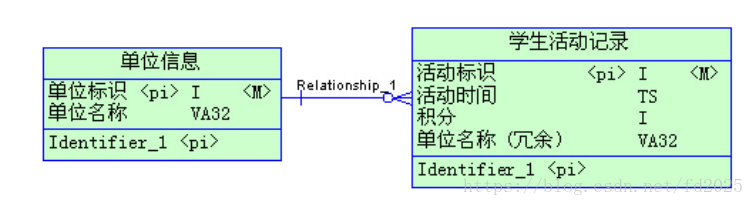
*上面这个就是不合适的冗余,原因是:
在这里,为了提高学生活动记录的检索效率,把单位名称冗余到学生活动记录表里。单位信息有500条记录,而学生活动记录在一年内大概有200万数据量。 如果学生活动记录表不冗余这个单位名称字段,只包含三个int字段和一个timestamp字段,只占用了16字节,是一个很小的表。而冗余了一个 varchar(32)的字段后则是原来的3倍,检索起来相应也多了这么多的I/O。而且记录数相差悬殊,500 VS 2000000 ,导致更新一个单位名称还要更新4000条冗余记录。由此可见,这个冗余根本就是适得其反 的。
建表:
1. 表结构的拆分,如核心字段都用int,char,enum等定长字段,
非核心字段或用到text超长的varchar拆出来单放一张表
2.定长和变长分离
如 id int ,占4个字节,char(4)占4个字节的长度,也是定长,time即每一单元值占的字节是固定的。核心 且常用字段,宜建成定长放在一张表。
而varchar,text,blob,这种变长字段,适合单放一张表,用主键和核心表关联起来。
3.常用字段和不常用字段要分离
需要结合网站具体的业务来分析,分析字段的查询场景,查询频度低的字段,单拆出来
4.合理添加冗余字段
列选择原则:
1. 字段类型优先级 整型 > date,time > enum, char > varchar > blob
列的特点分析:
整型: 定长,没有国家之分,没有字符集的差异
time: 定长,运算快,节省空间,考虑时区
enum: 能起来约束值得目的,内部用整型来存储
char:定长,考虑字符集
varchar: 不定长,要考虑字符集的转换与排序时的校对集,速度慢
text/blob: 无法使用内部临时表
2.够用就行,不要慷慨(如smallint,varcahr(N))
原因:大的字段 浪费内存,影响速度
以年龄为例tinyint unsigned not null, 可以存储255岁,足够,用int 浪费了3个字节
以varchar(10),varchar(300)存储的内容相同,但在表联查询时,varchar(300)要花费更多内存。
3.尽量避免null
原因: null 不利于索引,要用特殊的字节来标注
在磁盘上占据的空间其实更大