8.知识点
8.1.内存知识点
https://blog.csdn.net/qq_14877637/article/details/103139227
1、静态内存SRAM
读写快
2、动态内存DRAM
读写慢
从老到新SDRAM、DDR1、DDR2、DDR3、DDR4...
DDR(Double Date Rate),可以在一个时钟读写两次数据
按照数据合代码的存储方式,可分为冯诺依曼结构(又称为普林斯顿体系结构)和哈佛结构。
1、冯诺依曼结构
数据和代码放在一起
2、哈佛结构
数据和代码分开放
汇编语言:没有内存管理,直接使用内存地址,但是效率最高
C/C++:有相应的API,但是得自己释放
Java/C#:不需要担心泄露问题,虚拟机会帮我们做好,但是要付出效率的代价。
32位系统可以用的内存是2^32=4G。(地址线只有32).
3种内存管理方式
栈:是一种数据结构,是一种维护内存的机制。
放:局部变量
堆:也是一种内存管理方式。
放:动态申请的数据
静态数据区:随着程序的运行而分配空间,程序结束才释放。
放: 静态局部变量
全局变量
文件映射区:进程打开文件后,将这个文件的内容从硬盘读取到进程的文件映射区,
以后就直接在内存中操作这个文件,读写完成后保存时,再将内存中的文件写到硬盘中区。
在C语言程序中,存放数据所能使用的内存空间大概分为4种:
1、栈 stack
2、堆 heap
3、数据区 (.data区、.bss区)
4、常量区 (.ro.data 、.text)
编译器在编译程序的时候,程序(可执行文件)会按照一定的结构被划分为不同的段进行组织,段有
1、代码段 .text:只读的。存放程序----各种函数的指令。有可能存放常量字符串(char *p=”linux”)
2、数据段 .data:也被称为数据区、静态数据区、静态区。存放显示初始化为非0的静态变量。
3、.bss:又叫ZI(Zero Initial)段,存放未初始化或显示初始化为0的静态变量,这个段会将未初
始化静态空间初始化为0。
.data和.bss并没有本质的区别,不需要特别明确的区分二者。


8.2.TCP/IP、Socket知识点
https://blog.csdn.net/qq_14877637/article/details/97617744
https://blog.csdn.net/qq_14877637/article/details/97310675


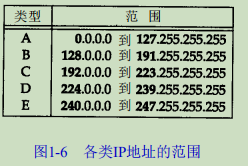


客户端通常对它所使用的端口号并不关心,只需保证该端口号在本机上是唯一的就可以了。
客户端口号又称作临时端口号(即存在时间很短暂)。这是因为它通常只是在用户运行该客户程序时才存在,
而服务器则只要主机开着的,其服务就运行。
使用T C P / I P协议的应用程序通常采用两种应用编程接口( A P I):s o c k e t和T L I
(运输层接口:Transport Layer Interface)。前者有时称作“Berkeley socket”,
表明它是从伯克利版发展而来的。后者起初是由 AT & T开发的,有时称作 X T I(X / O p e n运输层接口),
以承认X / O p e n这个自己定义标准的国际计算机生产商所做的工作。 X T I实际上是T L I的一个超集。
在T C P / I P中,网络层和运输层之间的区别是最为关键的:网络层( I P)提供点到点的服务,
而运输层(T C P和U D P)提供端到端的服务。
I P路由选择是逐跳地(h o p - b y - h o p)进行的。从这个路由表信息可以看出,
I P并不知道到达任何目的的完整路径(当然,除了那些与主机直接相连的目的)。所有的I P路由选择只为
数据报传输提供下一站路由器的 I P地址。它假定下一站路由器比发送数据报的主机更接近目的,而且下一
站路由器与该主机是直接相连的。
I P路由选择主要完成以下这些功能:
1)搜索路由表,寻找能与目的 I P地址完全匹配的表目(网络号和主机号都要匹配)。
如果找到,则把报文发送给该表目指定的下一站路由器或直接连接的网络接口(取决于标志字段的值)。
2) 搜索路由表,寻找能与目的网络号相匹配的表目。如果找到,则把报文发送给该表目指定的下一站路由器或直接
连接的网、络接口(取决于标志字段的值)。目的网络上的所有主机都可以通过这个表目来处置。例如,一个
以太网上的所有主机都是通过这种表目进行寻径的。这种搜索网络的匹配方法必须考虑可能的子网掩码。
3) 搜索路由表,寻找标为“默认( d e f a u l t)”的表目。如果找到,则把报文发送给该表目指定的下一站
路由器。如果上面这些步骤都没有成功,那么该数据报就不能被传送。如果不能传送的数据报来自本机,
那么一般会向生成数据报的应用程序返回一个“主机不可达”或“网络不可达”的错误。
8.3.编译连接知识点
https://blog.csdn.net/qq_14877637/article/details/89294102
如果不小心移动或者删除了/lib,导致好多命令都不能用,比如ls,cp,mv...,解决如下:
ld-linux.so.2是linux系统的动态连接器,我们可以用他来执行命令,我们使用它的--library-path参数
来重新指定LD_LIBRARY_PATH的位置:
/path/to/ld-linux.so.2 --library-path /path/to /path/to/ls / -F
8.4.编解码流程知识点


8.5.算法知识点

8.6.架构知识点

8.7.MySQL知识点





分组的作用 group by
分组可以把数据分为多个逻辑组,以便能对每个组进行聚集计算。
Select b,count(*) as numb from test group by b;
Group by 必须出现在where之后,order by之前。
Group by不能使用where过滤,得使用having。Where是过滤行,having是过滤分组
Distinct 同时检索多行,是什么意思
比如distinct a,b,c 只要两条记录中a或b或c有一个不同。Distinct的规则是a|b|c不是a&b&c。
如果不明确排序,则不应该假定搜索出的结果顺序有意义,不一定是按照添加顺序(受到修改后回收空间的影响)
Order by 指定多个列时的意思
比如 order by a,b; 会先按a排序,在相同的a中按照b排序,换句话说如果a没有相同的,则不对b进行排序。
|a|b|
|1|2|
|1|5|
|2|3|
|3|1|
|3|2|
排序默认是升序。如果想要在多列上进行排序,则必须每列都指定排序方式。order by a DESC,b ASC;
A和a默认是相同的,可使用binary关键字
And的优先级高于or,所以多用括号
Like和regexp的注意点
Like “haha” 匹配的是值为haha的项,而regexp匹配的是值里包含haha的项。
AS:别名,select a as aaa;
联结
等值联结:内部联结,inner join。。。On
自联结




8.8.Java知识点

8.9.显卡型号知识点
显卡的供应商有两家AMD和Nvidia,网友习惯称之为A卡和N卡。
例如:Nvidia显卡GTX1080 Ti
其中GTX代表是高级版,如果是GT就是普通版。
其中的10代表是第十代。也是目前的主流产品。他的上一代产品是GTX 980,就是第九代。而他的最新一代产品是2080,并没有1180这个产品的型号。相同等级的代数越高越强。
其中8代表的是等级。等级越高性能越强。等级之间的性能可以说是倍数级的。
1-4是低端
5是中端性价比级的
6一般定位甜点级 中端级
7是中高端
8是旗舰
9是双芯旗舰
其中0在官方暂时没啥用,但是在民间其代表着显存:例如1063就是1060的3G显存版。1066就是1060的6G显存版,他们其实都是 GTX 1060显卡的别称。
其中后缀Ti,Ti版本的显卡比没有Ti的要好,例如1070Ti比1070好,但比1080差。后缀Max-Q就是笔记本专用的缩水版。
8.10.IntelCPU知识点
IntelCPU包含奔腾系列、酷睿系列、至强系列、赛扬系列。以下用最常见的酷睿系列说明。
例:Core i7-6700K。
i7代表等级。数字越大其核数和线程数越大。性能越强。
6代表代数。有Core i7-5700K,Core i7-6700K,Core i7-7700K
700代表型号。数字越大表示频率越高,性能越强。(频率:CPU的时钟频率,简单说是CPU运算时的工作的频率(1秒内发生的同步脉冲数)的简称。单位是Hz。)
K是后缀。后缀含义如下:

8.11.Docker知识点
通常Docker经常会和镜像一起遇到。
Docker Hub Registry。这是 Docker 的官方镜像仓库。
Docker 是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的 Linux 机器上,也可以实现虚拟化。容器是完全使用沙箱机制,相互之间不会有任何接口。
Docker 是一个便携的应用容器。当你需要在容器内运行自己的应用(当然可以是任何应用),Docker 都提供了一个基础系统镜像作为运行应用时的基础系统。也就是说,只要是 Linux 系统上的应用都可以运行在 Docker 中。
Docker 并不在乎你的应用程序是什么、做什么,Docker 提供了一组应用打包、传输和部署的方法,以便你能更好地在容器内运行任何应用。
8.13.摄像头不同焦距知识点


8.14.敏捷知识点
4个价值观:
12原则:
方法:



关键词:
心情曲线、成绩墙、错题集
团队定契约
分配特性团队;大需求拆分;需求排列优先级;迭代的研发、交付、反馈
加快反馈循环
响应变化;允许试错;小步快跑;减少浪费
敏捷不是更快的开发,而是更快的纠错,最终更快的圆满交付
