先创建一个数据库myhive2019
create database if not exists myhive2019;
在myhive2019数据库下创建内部表 student:
create table student(id int,name string,gender string,age int,department string) row format delimited fields terminated by “,”;
导入数据:
load data local inpath “/home/hadoopUser/students.txt” into table student;

1.分区表
分区是在该表的目录下创建多个文件夹分别存储数据。
关键语法:partitioned by
1.1静态分区
-
创建分区表 student_ptn:
create table student_ptn(id int,name string,age int,department string)
partitioned by(gender string)
row format delimited fields terminated by “,”;注意:分区字段不能与表字段重复。
-
创建分区表后,可以通过show partitions student_ptn;查看是否有分区定义,刚创建出来一般是没有的。

-
通过alter语法添加一个或多个分区定义(该例子以性别作为分区):
alter table student_ptn add partition(gender=‘male’);
alter table student_ptn add partition(gender=‘female’);
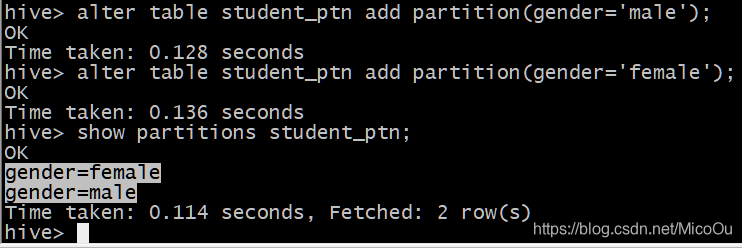
对应地,在HDFS上也能看见创建的分区文件夹,d代表文件夹。

-
往分区表中的分区文件夹下导入数据:
导入数据的方式可查看这篇文章:hive数据导入的6种方式这里主要介绍2种插入方法:
1)insert…values… (一般是用作测试)
insert into table student_ptn partition(gender=‘male’) values(1,“小明”,18,“MA”);2)//单重或多重插入
from 数据表
insert…select…//单重查询
from student
insert into table student_ptn partition(gender=“male”) select id,name,age,department where gender = “男”;//多重查询,insert之间不用逗号分隔
from student
insert into table student_ptn partition(gender=‘male’) select id,name,age,department where gender=“男”
insert into table student_ptn partition(gender=‘female’) select id,name,age,department where gender=“女”;//查询是否插入成功
select * from student_ptn where gender = “male”;
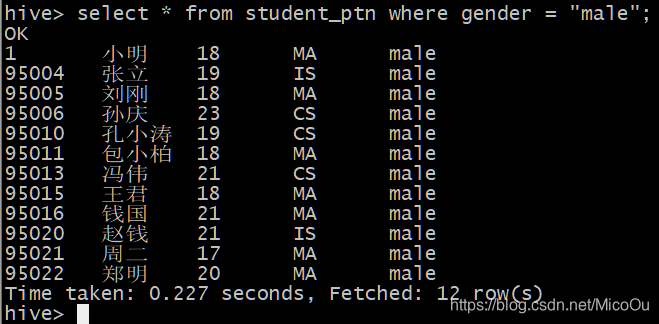

注意:不能直接往分区表中导入数据。

-
修改分区
alter table 分区表 partiton(分区字段) set location “HDFS路径”; -
删除分区
包括分区的元数据信息和分区的数据及目录。
alter table 分区表 drop partition(分区字段) ; -
清空分区
清空分区内所有数据文件,但是该分区文件夹还在。
truncate table 分区表 partition(分区字段);若只想删除该分区下的部分数据文件,使用hadoop命令删除。
hadoop fs -rm -f hive数据存储的路径/数据文件名
小结
- 分区字段不能和表字段重复。
- 通过show partitions 分区表 可以查看该分区表是否有分区定义。
- 分区定义可以一个字段或者多个字段。
- 通过alter table 分区表 add partition(分区字段1 = XXX,分区字段2 = XXX…);来添加分区定义。(分区字段的个数和顺序需要在创建分区表时指定好)
- 分区表不能直接插入数据,分区表中的任何数据一定要属于某个分区(比如任何一个中国人,都必须属于某个省)。
最大的作用:
- 在select的时候,可以通过where来过滤条件,提升效率。
举例:
select * from student_ptn where gender = “male”;
解释:
如果student_ptn 是普通表,sql会进行全表扫描。
如果student_ptn 是分区表,并且刚好gender是分区字段,只需要扫描这个分区表中的 gender=“male” 这个文件中的数据即可,避免了全表扫描。
应用场景:
- 当某份数据中的某个字段经常被用来进行where过滤,那么该表最好被创建成分区表,并把过滤条件的字段定义为分区字段。
1.2动态分区
如果student表的age字段需要做分区字段,创建静态分区需要手动创建很多个,非常重复性劳动。所以hive提供了动态分区功能,能够根据你的分区字段有多少个值,自动创建多少个分区。
-
创建分区表 student_age(和静态分区一样)
create table student_age(id int,name string,gender string)
partitioned by(age int)
row format delimited fields terminated by “,”; -
动态分区参数设置,最好手动开启
1)查看开关
语法:set 开关
set hive.exec.dynamic.partition;
set hive.exec.dynamic.partition.mode;

2)打开开关
语法:set 开关 = 值;
set hive.exec.dynamic.partition = true;
set hive.exec.dynamic.partition.mode = nonstrict;

-
编写动态分区的插入语法
insert into table student_age partition(age) select id,name,gender,age from student;
条件:
①分区字段必须放在select查询字段的最后
②select查询字段的名称要与student_age表字段名称对应。可以看到创建出来的动态分区有7个,每个分区下都有数据。
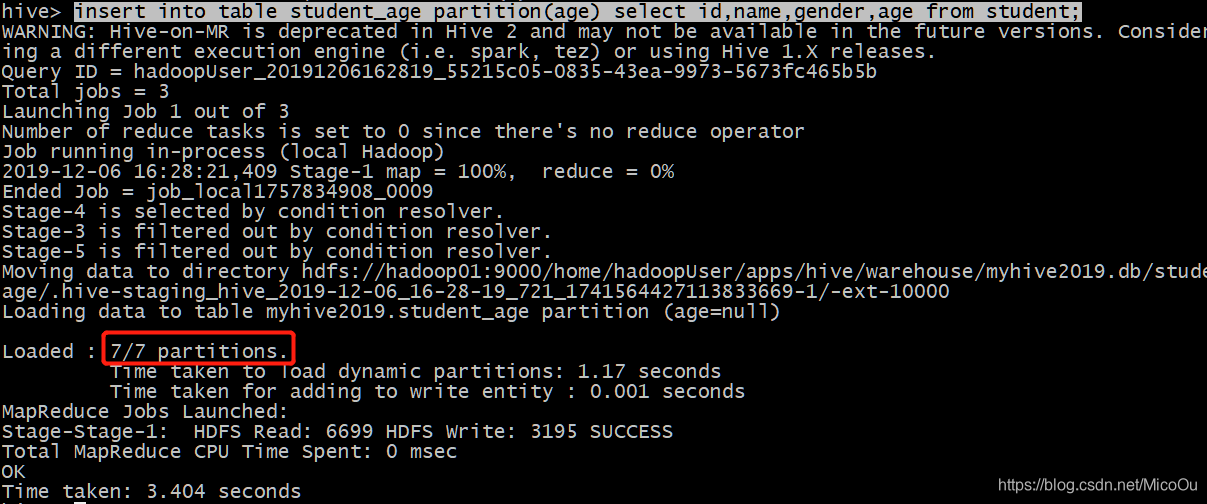
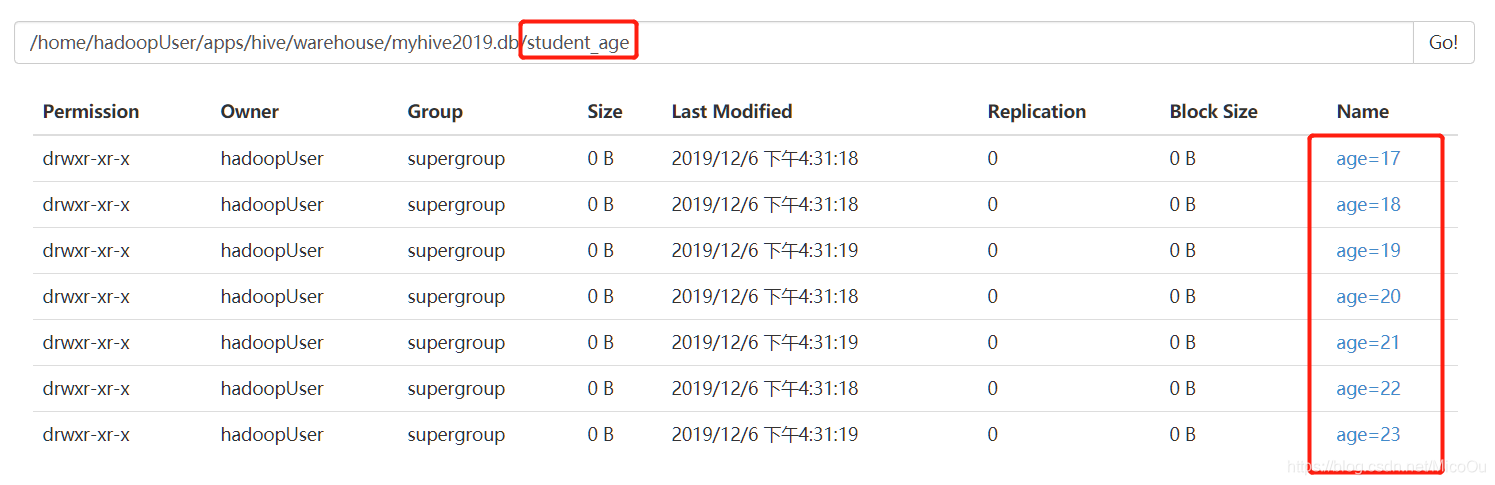

-
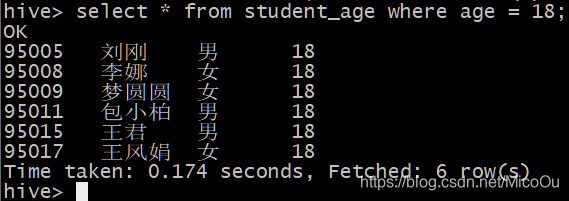
查看结果
select * from student_age where age = 18;
小结
- 动态分区是按照分区字段的值进行划分,一个值就是一个分区,每个分区存一个分区字段值的数据。
- 如果是多字段动态分区,则前n-1个字段必须手动指定分区定义,只有最后一个字段可以进行动态分区。(因为分区字段必须在select查询字段的最后,如果你有多个分区字段,只会把最后一个字段当作是分区字段)
2.分桶表
分桶就是按照某种策略拆分成多个文件分别存储数据。
默认的分桶规则:hash散列
分桶字段的值经过分桶逻辑计算之后得到的余数相同的都在同一个分桶文件中
一个分桶文件可能存在分桶字段的多个值
一个分桶文件也可能存在没有任何数据
例子:
分桶的个数:3
AA=0
BB=1
CC=0
DD=1
EE=0
上面的AA和CC和EE都会出现在第一个分桶文件当中
上面的BB和DD都会出现在第二个分桶文件中
第三个分桶文件当中就不会出现任何值。
-
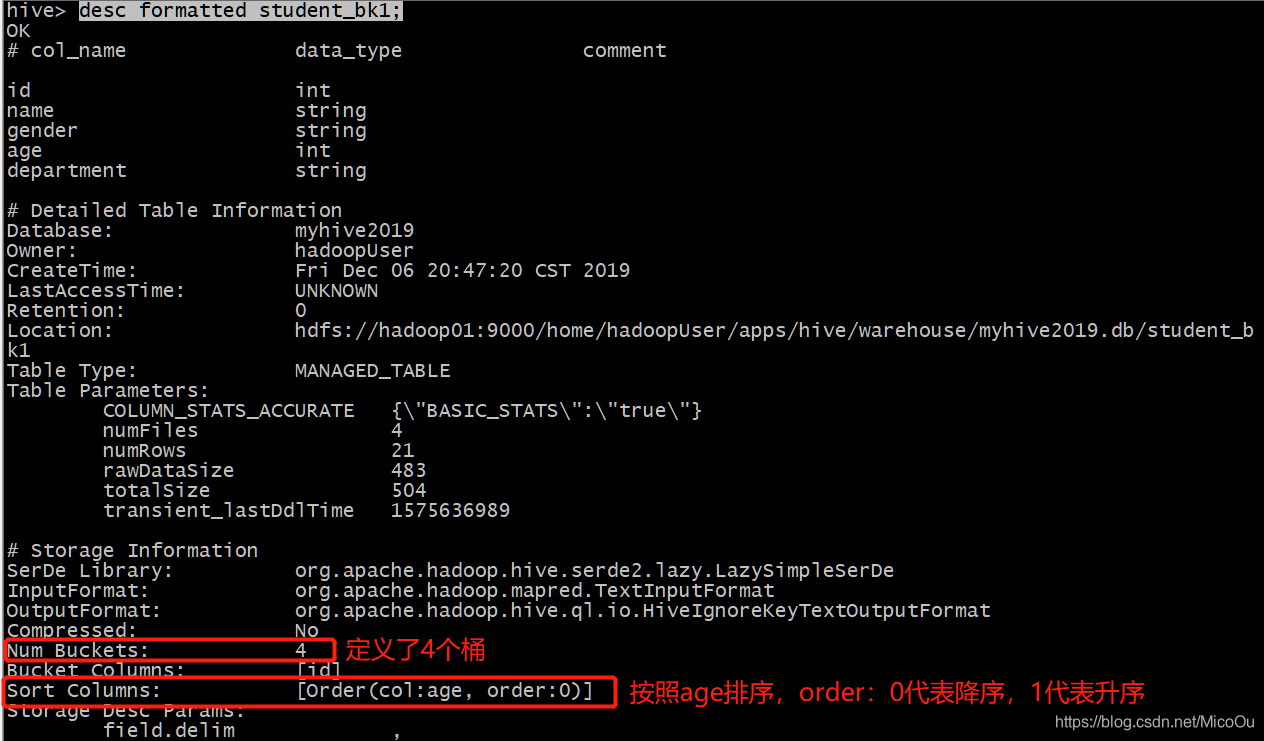
创建分桶表
create table student_bk1(id int,name string,gender string,age int,department string)
clustered by (id)
sorted by (age desc)
into 4 buckets
row format delimited fields terminated by “,”;解释:
clustered by (id) :设置分桶字段
sorted by (age desc) :按照年龄降序,非必须项
into 4 buckets :设置桶数查看student_bk1的元数据信息
-
打开开关,设置桶数
set hive.enforce.bucketing = true;
set mapreduce.job.reduces = 4; # 要跟分桶设置的个数一致set mapreduce.job.reduces默认是-1,就是没有指定
-
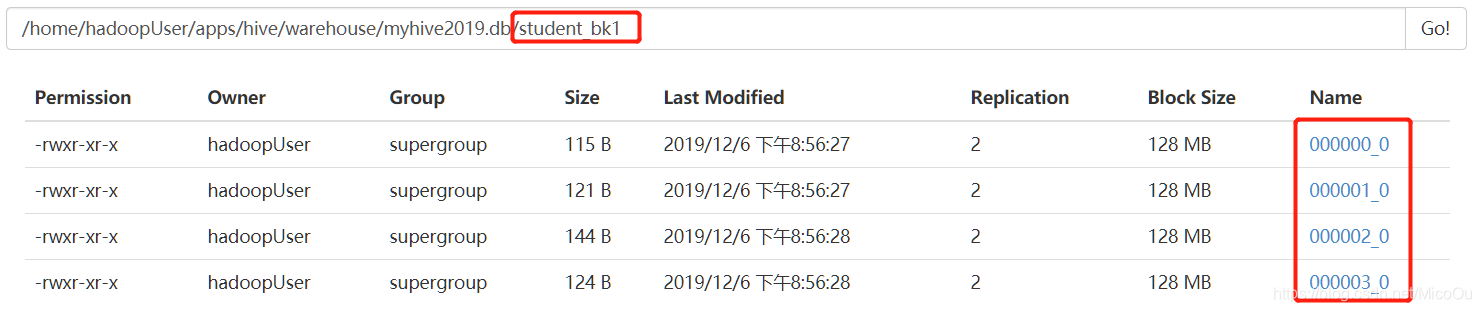
导入数据
和分区表一样,不能直接往分桶表中load数据。
提示说导入数据需要先导入到一张中间表,再用insert…select导入到分桶表。

使用insert…select…
把student这种中间表通过select查出来,然后放入到sudent_bk1这张分桶表
insert into table student_bk1 select id,name,gender,age,department from student;可以看到导入的数据都是以文件的形式存储在分桶表的目录下。
-
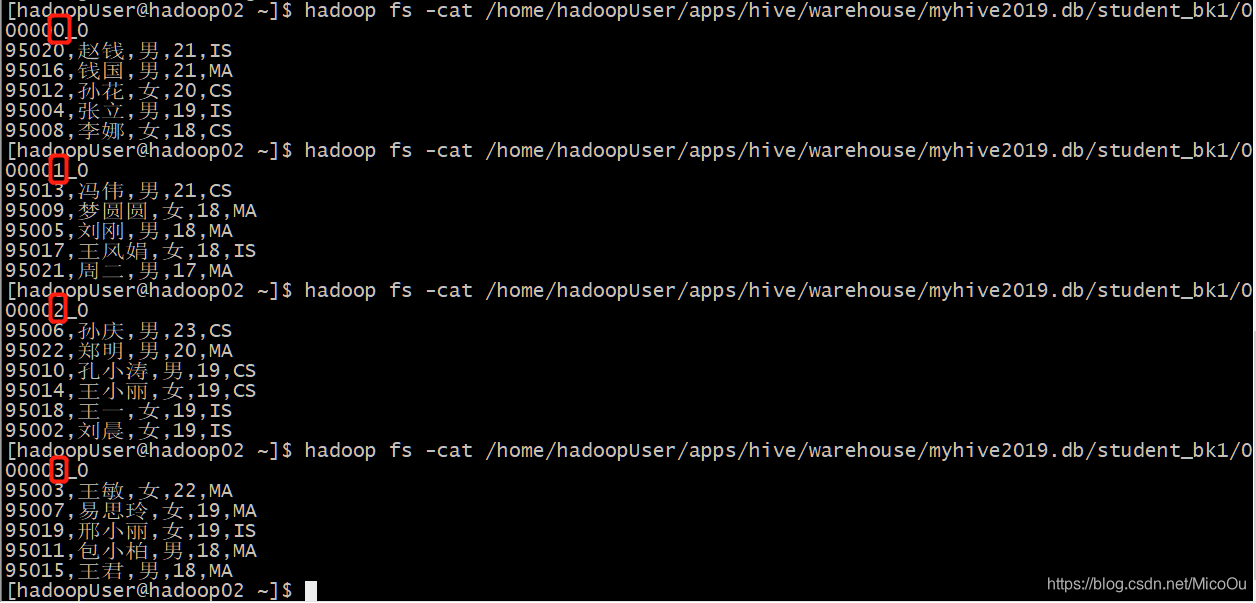
查看结果
hadoop fs -cat hive目录/分桶文件名我们设置了id为分桶字段,设置了4个桶,这里的数据划分是按照id字段值的hash值 % 分桶个数 ,取模来划分的。不管分桶字段是什么类型,都返回int整数划分。
比如:
95020%4=0,所以放在0号文件里
95013%4=1.所以放在1号文件里
…
因为我们创建student_bk1的时候,指定了age降序排序,所以数据的插入也是按照age降序排序。
小结
- hash散列是把分桶字段的hash值%分桶个数,余数相同的划分同一个桶里。但是一个桶里,可能会出现多个不同的字段值。
比如:
某个分桶文件存储了深圳,深圳的hash值%分桶个数,假设其余数=0,则所有余数=0(即值为深圳)会放在一个桶,但是可能广州的余数=0,也会放在同一个桶,就会出现深圳、广州这两个不同的值在同一个桶。 - 如果只想把同一个字段值放在同一个文件下,就必须使用动态分区来做。
动态分区能保证每个值在一个分区,而且该值的所有记录,一定都在这个分区。
