这篇文章主要记录一下搭建hadoop集群+hive的过程,方便以后的复现工作。
搭建过程主要参考这三篇文章基本就可以了,不过由于软件版本差异也遇到了文章中没有提及的问题,我会给出解决方案供读者参考:
[1]https://www.cnblogs.com/90zeng/p/hadoop_setup.html
[2]https://sq.163yun.com/blog/article/215531730633461760
[3]https://blog.csdn.net/sinat_42888557/article/details/90753343
实验环境:
腾讯云主机三台:1台作为主节点(master),另外2台作为从节点(slave01,slave02),debian系统, 保证在同一局域网内即可
本次实验主机,内网ip,对应的节点功能设置为:
node1 172.16.16.14 master/namenode/secondary namenode/hive
node2 172.16.16.4 slave01/datanode
node3 172.16.16.15 slave02/datanode
需要准备的工具:
jdk-7u67-linux-x64.tar
hadoop-2.6.5.tar.gz
mysql-connector-java-5.1.32-bin.jar
apache-hive-1.2.2-bin.tar.gz
辅助工具:xshell xftp
要说明的是因为有搭建过伪分布式环境,上述的版本是兼容的,所以我这次依然沿用了以前的版本配置,如果读者打算自己搭建比较新的环境,关于jdk,hadoop和hive的版本对应关系可以去官网查看,如果版本对应不上很容易出现兼容问题。
主要流程
先介绍一下主要流程,可以分为如下几步:
*事先需要注意的2点:1.如果出现局域网节点之间无法通信,可以检测网络链路通信状况以及防火墙设置,本次实验采用的debian系统没有安装防火墙,就不考虑这一步 2.在实际工作中出于安全考虑,不会给到root权限,所以先需要添加用户分配好相应权限后进行操作,本次实验没有这方面安全需求,直接采用root用户。
下列终端均是采用xshell进行远程访问,向主机上传递文件时采用xftp
1.配置host相关文件
更改每个节点的hosts, hostname文件,添加主机名和ip的映射关系(下面是主节点修改后的文件,对应其余两台从节点也要依次修改,修改成功的标志是任意节点之间都能互相利用主机名ping通即可),修改完成后重启节点使配置生效
关键命令:
vi /etc/hostname

vi /etc/hosts

2.配置jdk环境
将jdk-7u67-linux-x64.tar利用xftp传到主节点上,进行解压,并且配置java环境变量(也可以去官网下载对应版本jdk-bin文件解压使用,或者自行编译源码文件均可),出于方便管理需要,我们把jdk,hadoop,hive均放在/usr/local目录下,下图的/etc/profile文件是实验环境搭建完成时的显示,在当前只需要添加JAVA_HOME并且将JAVA_HOME添加到PATH即可。
关键命令:
tar xvf jdk-7u67-linux-x64.tar
mv jdk1.7.0_67 jdk
mv jdk /usr/local
vi /etc/profile,编辑完成后记得 source /etc/profile令其即时生效

java -version,出现以下信息证明java环境变量配置成功

在其余两台主机上也要配置jdk环境变量
3.配置ssh免密钥登录
因为Hadoop集群之间的节点会不断进行通信,需要执行这一步使得各个节点之间都能进行免密钥登录。以主节点免密钥登录从节点为例,原理简单来说就是主节点把自己的公钥在从节点中加入授权,使得主节点之后都可以无密码ssh到从节点。
下面命令行的作用依次是生成ssh文件夹,生成rsa密钥,将rsa密钥添加到授权文件(authorized_keys),修改授权文件权限
ssh localhost
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ./authorized_keys
我们在3台主机上执行上述步骤,依次生成公钥并且把公钥添加到授权文件,然后我们将这三台主机上的授权文件内容合并起来并且替换掉所有主机上的原authorized_keys文件,这一步操作完成后就可以在各主机之间进行无密码登录了,关于在主机之间互相传递文件可以使用scp命令,用法如下, 用户名和主机名需要根据自己的情况进行设置
scp filename user@hostname:/dir
4.配置Hadoop
以hadoop-2.6.5.tar.gz为例
1.按照jdk的步骤依次解压,修改名称,将其移动到/usr/local目录,添加HADOOP_HOME环境变量到profile,source使其立即生效
2.进入到hadoop配置文件目录,依次修改好 slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml。具体的配置项及作用可以参考官网的说明,这里对正常启动分布式集群所必须的配置项进行配置。(hadoop不同版本的目录会有区别,文章里配置文件所在目录是hadoop/conf,我的版本下是hadoop/etc/hadoop/)
cd /usr/local/hadoop/etc/hadoop/
vi hadoop-env.sh

vi core-site.xml

这里要注意要在/home/hadoop/ 目录下手动建立tmp目录,如没有配置hadoop.tmp.dir参数,根据系统默认的临时目录为:/tmp/hadoop-dfs。该目录在每次重启后都会被删掉,必须重新执行format才行,否则会出错,hdfs后面的ip号就是namenode的ip,端口号默认9000。
vi hdfs-site.xml

这里因为我们是设置了2个datanode节点,所以节点副本数量设置为2
vi mapred-site.xml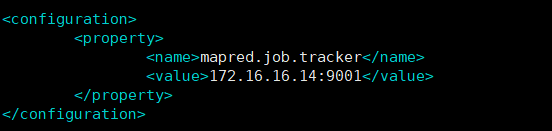
不同版本的hadoop文件名可能也会不同,比如文章[1]提到的修改mapreduce-site.xml文件,我这里文件名为mapred-site.xml.template,这里要首先copy一下mapred-site.xml.template,把文件名修改成mapred-site.xml,内容如下(写MASTER和主节点IP地址是等效的)
vi slaves

最后文章[1]还提到要修改master文件指定namenode所在节点,但是我的这个版本不用, 修改slaves文件即可,因为之前有配置hosts文件,所以直接写从节点名称就好。
4.把集群跑起来
进入hadoo环节的最后一步,将hadoop文件夹利用scp命令复制到其余两个从节点,然后在主节点进行文件系统格式化,日志信息中出现 storage directory xxxxxx has been successfully formatted即表示格式化成功,然后启动hadoop,并且利用jps命令检测主节点和从节点上的 namenode, datanode是否正常运行。
scp -r hadoop user@hostname:/dir
bin/hdfs namenode -format
sbin/start-dfs.sh
jps
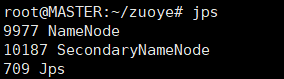

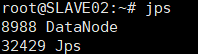
至此hadoop集群环境已经搭建成功,可以在集群上进行简单的测试工作,比如建立文件,写入文件等。
5.搭建hive
hive的搭建也分为几种,包括单节点搭建,客户端元数据分离等搭建方式,单节点搭建对于本次实验来说已经足够了。
hive的元数据是保存在Mysql里面的,首先我们需要先下载一个Mysql服务端并启动该服务,并且进行用户权限配置(因为hive在生成表的时候,一方面会往hdfs文件系统写入数据,另外也会在Mysql生成表用来保存元数据,所以必须要让hive有足够的权限对Mysql进行读写)
apt-get install mysql-server
service mysqld start
mysql -uroot -p(密码默认为root)
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
设置好数据库之后,接下来对apache-hive-1.2.2-bin.tar.gz依次解压,修改文件名,移动到/usr/local,添加HIVE_HOME环境变量到profile,source使其立即生效
vi conf/hive-env.sh

vi hive-site.xml

这里要注意的是hive-env.sh和hive-site.xml在文件中的原始名称是hive-env.xml.tempate和hive-default.xml.template, 需要自己修改文件名和文件内容,不然会导致文件无法识别(这一点在hive官网上也有说明)
接下来将mysql-connector-java-5.1.32-bin.jar复制到hive的lib目录下面,然后启动hive
在启动Hive的过程中我遇到了两个问题,1.文章[3]里面提到的jline包的问题,可以在报错日志信息中看到由于jline版本信息不一致导致的接口不兼容问题,解决方法就是拷贝hive的lib目录中jline.2.x.jar的jar包替换掉hadoop中的/home/hadoop-2.6.x/share/hadoop/yarn/lib/jline-0.x.x,替换后该错误消失。2.启动出错,错误日志显示Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient,查找得知hive 2.0以上版本,安装配置完成之后需要先初始化元数据库,解决方法: 执行 schematool -dbType mysql -initSchema 之后就可以正常启动hive。
接下来可以在hive中建立表,通过浏览器访问hadoop文件系统在hdfs中能看到新建表信息,mysql中元数据有相应的更新即可认为hive已经搭建成功。
至此关于Hadoop集群和Hive的环境搭建已经完成。后续会再尝试分布式集群的其他实践并做相应的记录,有问题的朋友欢迎交流~
