目录
3.1 Bagging(套袋法,bootstrap aggregating)
最近在跟着奔腾学习xgboost,这是一个很久之前就听说过的大杀器,还有lightGBM等等,一听就很厉害的样子,之前也稍微了解过集成学习,包括boost、bagging、stacking,但是一直都处于概念混乱状态,这次在开始xgboost之前,就先把集成学习的大致框架再梳理一下,如有错误,请大家指出~谢谢~ 以下主要参考袁博的《数据挖掘》课程集成学习那节,感觉袁博讲得还是很不错的,循循善诱,很适合小白入门,已经做好准备刷课啦,大家有好的课程,也欢迎推荐~
1.为什么需要集成学习?


集成学习不是一个算法,而是一个大的方向。“三个臭皮匠顶个诸葛亮”,是大多数人开篇介绍集成学习的经典语句。因为个体决策容易失误,所以需要群策群力,来尽可能的做出“有用”的判断,“Essentially, all models are wrong, but some are useful.”还有一种场景是可能会遇到model selection 的问题,在神经网络中,不同的初始值得到的结果可能是不一样的,9个10个神经网络怎么办呢?集成学习就可以带来帮助。
对于单个的机器学习算法,我们已经知道的有Decision Trees, Neural Networks, Support Vector Machines,现在需要的就是策略性的把他们结合在一起(The process by which multiple models are strategically generated and combined in order to better solve a particular Machine Learning problem.)下图分别是机器学习的整体框架,对分类器集成学习的简单图示,集成学习的效果简单图示,从下图最右可以看出,结合三种分类器,我们可以得到更好的分类效果,分类线也更平滑了。或者,复杂的分类界面也可以进行分割来求解。



2. 如何进行组合?
那么如果结合各个分类器的输出呢?首先,我们最容易想到的就是平均Averaging,然后我们可以想到让不同的分类器进行投票,投票其实又包括了少数服从多数决定,但是每个分类器所起到的效果不一定一样,所以还可以采用对不同分类器的结果进行加权的多数投票。再进一步,我们可以让一个分类器来学习如果组合(combine),而不是简单的加权。

集成学习有一个假设,是为了获得更好的效果,在集成学习使用的分类器中需要注意 “多样化(Diversity)”,这些分类器是要有所不同的,否则为什么要用辣么多,一个就可以啦。什么是不同呢?可以是不同的分类器,也可以是不同的训练过程(比如参数、训练集、特征)。并且,可以使用很多的弱分类器(例如Stumps,只有树桩的决策树),强分类器其实会更复杂,效果不一定好。那怎么样可以选择不同的训练数据,但是又服从相同的分布呢?Boostrap Samples是个好办法,即有放回的采样。


3. 分类
3.1 Bagging(套袋法,bootstrap aggregating)
Bagging 就是基于Boostrap的一种分类器,例如50次采样,然后训练50个分类器,然后进行投票。


例如以决策树为例,则有下面的结果:
3.1.1 Random Forest
长得不一样的决策树进行组合,来构成一个“森林”。每次对训练集数据进行随机选择,选中的2/3作为训练集,没有选中的作为测试集,不需要人为的选择,所以在训练的时候就可以得到树的好坏。一般来说是500-5000,不局限于CART。


传统的决策树会对所有的属性进行分裂,但是随机森林每次只对一部分属性进行分裂,这样就可以保证每棵树的属性也不一样,也不需要担心过学习,不需要进行特征选择。需要的参数很少。


3.2 Stacking
不同的分类器性能不同,所以不同分类器的权重也应该是不同的,那么如何学习这些权重呢?可以考虑Stacking。在Bagging中,得到了k个分类器,然后送入测试集,进行投票即可。但是在Stacking中,每个分类器的输出会再送到一个分类器中,所以称为Stacking(堆叠)。它会根据label来学习每个分类器应该分配的权重是多少。这样得到的权重,通常会认为是更精准的。所以Stacking是经过了两层的训练,第一层得到Base classifier,第二层则学习如何分配权重。


3.3 boosting
boosting和Bagging最大的区别在于boosting是串行的,再Bagging中所有的分类器可以同时生成,但是boosting不可以,是需要一个个生成的,根据前一个分类器的性能生成下一个。简单图示如下,第一次训练后得到C1,然后用剩下的数据测试C1,看C1对于哪些样本分错了,然后将分错的样本重点来训练C2。C1分错的东西,是C2要特别学习的,所以他们是互相弥补的。然后将C1、C2同时进行测试,看有哪些判断不一致的样本,而这些样本是C3需要特别学习的。所以总是分错的样本的权重会越来越大。这个时候对于测试X,送入3个分类器,进行判断。




Boosting对分类器要求很低,只要高于随机水平即可。
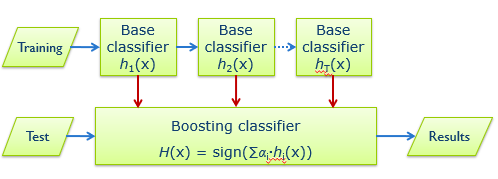
3.3.1 Adaboost
Boost中最经典的算法,机器学习的十大算法之一。

如下图所示,每次都会增大错分样本的权重。




Adaboost是可以从数学上证明训练误差越来越小的,最后趋近于零。模型误差的上限可以用数学公式表达出来。

AdaBoost采用了贪心策略,所以每次最小化当前的Z。Z是每个样本的权重,所以如果样本分配的权重小,表明大部分都分类正确,所以样本权重越来越小,可以代表训练误差越来越小。

那么如何最小化Z呢?根据y是否等于h进行拆分,然后求导。



3.3.2 Region Boost
如果问甲一个问题靠不靠谱,其实取决于这个问题是什么?同样,对于不同的测试样本,也应当具有不同的权重。根据输入X的不同,会有一个特定的权重,所以不同的样本进来,不同的分类器发言权是不一样的。因此与Adaboost的固定权重,这里是动态的权重,利用不同的区域信息来调整不同的权重。



在训练的时候,对三角形和圆形进行分类,发现上面的分错了,下面的分对了,那么如果进来的测试集位于上面的区域,则使用下面区域对应的分类器,降低上面分类器的权重,所以是在对不同分类器的可信度进行了建模。

采用K近邻,在高维空间中,欧式距离是不太合适的,所以可以采用下面的方法来找测试样本的位置,然后根据位置来反推权重。

仅从训练误差来看,Adaboost 似乎更好

但是模型更重要的是测试误差,从测试误差来看,RegionBoost的效果是更好的。

3.3.3 GBDT(Gradient Boosting Decision Tree)、XGBoost (eXtreme Gradient Boosting)、LightGBM
boosting的其他算法,下篇博客再介绍。

3.4 bagging vs boosting


