正则的介绍
正则一开始是用来限制参数的,例如在逻辑回归中,目标函数:
p(y=1∣x;w)=1+e−wTx+b1越大越好参数,
p(y=0∣x;w)=1−1+e−wTx+b1越小越好,如果我们的数据线性可分时, 根据目标函数,
w就会变得无穷大,因为此时
p(y=1∣x;w)=1而
p(y=0∣x;w)=0,但是这显然不是我们想要的,这样模型就会过拟合了。所以我们要限制参数,不让它太大因此这个时候我们用到了正则:
w,b=argmin∏i=1np(yi∣xi;w)+λ∣∣w∣∣2
∣∣w∣∣2=w12+w22+w32+...+wd2
假设
w变得很大,那么
λ∣∣w∣∣2也会变得很大,这样就会使公式也会变得很大,而我们的目标函数是为了求最小,所以在计算的时候不会让
w变得特别大。也就是做到了限制参数的作用。
此时
λ表示的是超参数,当
λ=0时表示没有任何限制,
当
λ越大对
w的限制越大,相反当
λ越小对
w的限制越小。因此
λ限制
w避免线性可分时参数
w变得无穷大。
L1和L2
λ∣∣w∣∣2我们经常称为
L2,,但是正则不仅仅只有
λ∣∣w∣∣2一种,我们常见的还有正则
L1:λ∣∣w∣∣=λ∑i=1d∣wi∣当然还有其他正则在这里就不一一介绍啦,一般正则的使用都是比较灵活,针对特定的问题使用正则。
现在我们了解一下这两种正则
w,b=argmin∏i=1np(yi∣xi;w)+λ∣∣w∣∣22
w,b=argmin∏i=1np(yi∣xi;w)+λ∣∣w∣∣1
L1和
L2的作用都是使得参数
w变小,避免变得很大,但是它俩有一个不同之处:
使用
L1导致我们获得解是一个稀疏的解:
w=(0,0,0,0,0.01,0,0,0,0.2,0,0.4)
也就是遇到一些很小的值我们都把它设置为0,因此
L1可以做一些选择性的场景
而使用使用
L2导致我们获得解是不是稀疏的
w=(0.1,0.054,0.11,0.25,0.01,0.2,0.4)
为什么会是这样的
我们使用几何的角度来了解一下如下图:

我们求得解也就是
f(w)与
L1或L2的交集处,我们可以从图片中看出
f(w)与
L1的交点有很多都落在
y轴上,所以加入L1的正则得到的解往往是稀疏的
因此我们在使用正则的时候往往是根据特定 问题去选择使用L1还是L2,比如我们在思考问题的时候大脑中的的神经不是全部在发生作用,往往只是一小部分,或者只是一部分区域,如果我们在思考这类问题时,可以加入一个L1正则

目标函数为:
f(r1w1+r2w2+r3w3+r4w4+...+rnwn)
解:
w(w1,w2.w3...wn)
大部分时间思考时我们只有小部分区域可以活动,因此可以使用L1正则
L1vsL2
虽然L1和L2都能使参数变小,但是L2的准确率比L1要高,L1是稀疏的L2不是
L1还有一个缺点:从相似参数里随机选择一个,而不是最好的那个。所以现在有:
w,b=argmin∏i=1np(yi∣xi;w)+λ1∣∣w∣∣1+λ2∣∣w∣∣22
并且对于超参数
λ1,λ2进行不断地优化
对于
w1=argmin∏i=1np(yi∣xi;w)+
w2=argmin∏i=1np(yi∣xi;w)+λ∣∣w∣∣22
问:
f(w1)?f(w2)
答:
f(w1)≤f(w2)
为什么会是这样的呢?
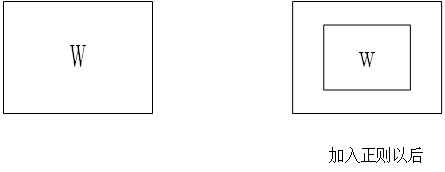
如图我们加入正则以后w可选择的范围变小了。
交叉验证
交叉验证的目的就是选择最优的那个超参数。例如我们选择这样L2正则,那么我们该怎么确定
λ的值,或者说当
λ的最优值是什么呢?
w,b=argmin∏i=1np(yi∣xi;w)++λ∣∣w∣∣22
这个时候我们一般使用的是交叉验证,也就是将训练数据切出来一小部分为验证数据

假设
λ∈{0.1,0.2,0.3,0.4}
p表示使用验证集计算出的准确率
计算当
λ=0.1时:
p=4p1+p2+p3+p4
计算当
λ=0.2时:
p=4p1+p2+p3+p4
计算当
λ=0.3时:
p=4p1+p2+p3+p4
计算当
λ=0.4时:
p=4p1+p2+p3+p4
找到最优的
λ代入目标函数进行下一步计算
参数的搜索策略
对于:
w,b=argmin∏i=1np(yi∣xi;w)+λ1∣∣w∣∣1+λ2∣∣w∣∣22
我们如何去选择
λ1和
λ2
现在有4种常见的解决方式:
① grid search
假设
λ1∈{0.1,0.2,0.3,0.4}
假设
λ2∈{0.32,0.32,0.23,0.14}
考虑所有的组合
利用交叉验证求平均准确率,找到最合适的那个组合
优点:可以平行化计算。
缺点:计算复杂,浪费资源
② 随机 search :给定
λ1和
λ2从该区间随机取出数据
③遗传算法:好的个体更倾向产生更好的个体,不断地去选择更好的
λ
④贝叶斯优化:类似与遗传算法,去不断选择更好的区间, 其核心思想是好的参数周围也会产生更好的参数,差点的参数周围也不太好,不断的选择更好的参数。
参数的搜索策略也是比较重要的:
比如神经网络的每一层都包含超参数,怎样去选择更好的参数也是一个比较重要的地方(调参)
正则的灵活使用
比如刚才提到的大脑的思考问题:我们在思考问题的时候大脑中的的神经不是全部在发生作用,往往只是一小部分,或者只是一部分区域

现在这里有两个条件:
①某个区域只有少部分被激活
②在空间上相邻的作用也类似。
old:
minmizef(w)
new:
minmizef(w)+∑i=1nλi∣∣wi∣∣+∑i=1n∑j=1r∣∣wij−wij−1∣∣2
推荐系统:
将用户-商品矩阵分解成用户矩阵和商品矩阵
我们的目标函数是:
min∑(ij)∈Ω(rij−uivj)2+∑i=1nλi∣∣ui∣∣+∑i=1mλi∣∣vi∣∣
ui表示用户,
vi表示商品
rij表示用户实际喜欢的商品,后面加入对于
u和
v的正则
现在我们又考虑到时间这个维度也就是说,随着时间的推移,用户对于产品的喜爱程度可能会发生变化,但是不会发生太大的变化,因此我们加入新的正则:
min∑t=1T∑(ij)∈Ω(rijt−uitvjt)2+∑t=1T∑i=1nλit∣∣uit∣∣+∑t=1T∑i=1mλit∣∣vit∣∣+∑t=1T∑i=1mλit∣∣vit−vit−1∣∣
+∑t=1T∑i=1nλit∣∣uit−uit−1∣∣
所以添加正则的作用目的就是防止过拟合的一种手段
选择超参数时使用的是交叉验证
参数搜索比较消耗资源。
MLE和MAP
为什么在这里提到MLE和MAP,因为今天我们学习了正则,在很多情况下MAP相当于MLE的+正则,为什么会是这样呢?我们来推导一下
MLE:
argmax:p(D∣θ)
MLE:
argmax:p(θ∣D)=argmaxp(D∣θ)⋅p(θ)(对于
p(x)数据的概率我们一般不用考虑)
其实
p(θ)就是一个先验的概率,随着样本的增加,先验的作用越来越小。
假设我们的
p(θ)服从高斯分布也就是:
p(θ)=2π
σ1⋅e−2σ2θ2
logp(θ)=−log2πσ−2σ2θ2
现在我们计算:
argmax:logp(θ∣D)=logp(D∣θ)+logp(θ)=logp(D∣θ)−log2πσ−2σ2θ2
将与
θ无关的项去掉:
MAP:argmax:logp(θ∣D)=logp(D∣θ)−2σ21∣∣θ∣∣2
MLE:argmax:logp(D∣θ)
所以这里的
λ=−2σ21
如果
p(θ)服从高斯分布,MAP相对于MLE来说就是增加了一个L2正则
假设我们的
p(θ)服从拉普拉斯分布也就是:
p(θ)=2b1⋅e−bθ
现在我们计算:
argmax:logp(θ∣D)=logp(D∣θ)+logp(θ)=logp(D∣θ)−log2b1−b1∣∣θ∣∣
将与
θ无关的项去掉:
MAP:argmax:logp(θ∣D)=logp(D∣θ)−b1∣∣θ∣∣
MLE:argmax:logp(D∣θ)
如果
p(θ)服从拉普拉斯分布,MAP相对于MLE来说就是增加了一个L1正则
总结:
高斯:L2正则
拉普拉斯:L1正则
Lasso介绍
Lasso模型其实就是在线性回归的基础上+L1正则主要是用来进行特征的提取,为什么会使用Lasso呢:
主要有一下几方面的原因:
1、数据量太少容易产生过拟合
2、维度太高计算量太高
3、可解释性
我们知道加了L1正则我们计算出的解是稀疏的,也就可以确定哪项权重对于数据是比较重要的。对于特征提取是比较有帮助的。
预测房价:
假设现在有5个特征:
f=(f1,f2,f3,f4,f5)
我们现在计算那些特征的组合对于房价是比较重要的
第一种方法穷举法:
计算
{f1}=acc1,
{f2}=acc2,
{f3}=acc3.
{f4}=acc4,
{f5}=acc5,
{f1,f2}=acc6....以此类推把所有特征组合都考虑,选择最高的acc
很明显这样做计算量比较大,但求出来的解是全局最优解。
第二种方法:贪心算法
先选择最好的:
{f1}=acc1,
{f2}=acc2,
{f3}=acc3.
{f4}=acc4,
{f5}=acc5j
假设,
acc2最大,
下面我们计算
{f2,f1}=acc1,
{f2,f3}=acc2,
{f2,f4}=acc3,
{f2,f5}=acc4
再次找到最好的并与上一个相比,如果比上一个好继续,比上一个差终止。
或者计算
(f1,f2,f3,f4,f5)=acc
然后删掉一个进行计算,找到最好的与原来进行相比,好就替代然后重复删除一个,不好就会终止。
这样我们计算的可能不是全局最优解,只是局部最优解。
使用Lasso的方法
我们可以知道Lasso是线性回归+L1正则,那么现在有一个问题。我们在计算梯度的时候需要计算:
∂wi∂∣w∣我们知道对
∣w∣求导是比较麻烦的,并且
w还是是多维的
因此我们使用到了coordinate descent
coordinate descent
也就是说对于
g(w)=g(w1,w2,w3,....,wn)我们在对于
w1进行求导时将其他维度的值看作常量,因此不断的对其中的
wi进行求导,也就是每个维度都单独的去考虑,寻找针对这个维度的最优解。
这个算法不一定对所有模型可以求得很好的结果,但是在Lasso中它很快会收敛。而且我们不用设置步长
Lasso
我们使用线性回归+L1正则,公式:
φ=∑i=1n(∑j=1dwjxij+b−yi)2+λ∑j=1d∣wj∣
xij表示第i个样本中的第j个特征
∂wφ∂φ=2∑i=1n(∑j=1dwjxij+b−yi)⋅xiφ+λ∂wφ∂∣w∣
=2∑i=1n(∑j=φwjxij+b−yi+wφxiφ)⋅xiφ+λ∂wφ∂∣w∣
=2∑i=1n(∑j=φwjxij+b−yi)⋅xiφ+2wφ∑i=1nxiφ2+λ∂wφ∂∣w∣
令
2∑i=1n(∑j=φwjxij+b−yi)⋅xiφ=Cφ
2wφ∑i=1nxiφ2=wφAφ
∂wφ∂φ=Cφ+wφAφ+λ∂wφ∂∣w∣
对于
∂wφ∂∣w∣我们分为3种情况,也就是
wφ>0,
wφ<0,和
wφ=0令导数等于零
⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧cφ+wφAφ+λw>0→wφ=Aφ−cφ−λ>0→Cφ<−λ[cφ−λ,cφ+λ]w=0→−λ≤Cφ≤λcφ+wφAφ−λw<0→wφ=Aφ−cφ+λ>0→Cφ>λ
因此:对于每个维度参数
wφ的更新
wφ=⎩⎪⎪⎪⎪⎨⎪⎪⎪⎪⎧Aφ−cφ−λCφ<−λ0−λ≤Cφ≤λAφ−cφ+λCφ>λ
