文章目录
- 1.模型总结
- 1.1 基于序列的方法
- 1.2 dependency-based(基于依赖的)(有图)
- 1.5 自动学习特征的方法
- 1.4 联合抽取模型
- 1.6 GCN用于关系提取
- 1.7 远程监督
- 1.8句子级关系提取
- 1.9MCR(阅读理解)(QA)
- 1.10(槽填充)
- 1.11 中文关系抽取
- 1.12 事件的时间关系
- 2.应用
- 3.模型细说
- 3.1 AGGCNs,2019
- 3.2 GCNN(Sahu, S. K., et al. (2019))
- 3.3 GraphRel
- 3.4 PCNN/CNN+KATT[Zhang, N., et al. (2019)
- 3.5 a multi-turn QA
- 3.6 APCNN+D,2017
- 3.7 Chinese_NRE(MG_lattice)
- 3.8 DISTRE
- 3.9 n-gram based attention model (多词实体)
- 3.10 Duration:Vashishtha, S., et al. (2019)
- 3.11DSGAN(远程监督,句子级去噪)
- 4.关系提取
- 5.各种model的效果
- 6.nlp工具
1.模型总结
-
关系抽取模型
- 实体关系联合抽取
- pipeline
- 词性标注
- 实体抽取
- 关系抽取
-
早期的研究工作是基于统计方法。
- 研究了基于树的内核(Zelenko et al., 2002)和
- GuoDong等人(2005年)探索了通过进行文本分析而选择的一组功能(词汇和句法),然后他们将这些功能转换为符号ID,并将其输入到SVM分类器
- 基于依赖路径的内核(Bunescu and Mooney, 2005),以提取这种关系。
- McDonald等人(2005)构建最大的实体团来预测关系。
- Mintz等人(2009)在统计分类器中包含语法特征。
-
pipeline
- 灵活,但受错误传播影响大
- Zelenko et al., 2003;
- Miwa et al., 2009;
- Chan and Roth, 2011;
- Lin et al., 2016)
- 胶囊网络(Zhang等人,2018a),先前应用于监督环境(Zhang等人,2018b),也适用于远距离监督环境。
1.1 基于序列的方法
-
基于序列的模型利用不同的神经网络来提取关系,包括
- 只对单词序列进行操作(Zeng et al.,2014; Wang et al., 2016)
- 卷积神经网络(Zeng et al., 2014;Nguyen和Grishman, 2015年;(Wang et al., 2016),
- 递归神经网络(Zhou et al., 2016;Zhang et al., 2017)
- 两者的结合(Vu et al., 2016)和
- transformer (Verga et al., 2018)。
- 只对单词序列进行操作(Zeng et al.,2014; Wang et al., 2016)
1.2 dependency-based(基于依赖的)(有图)
- 基于依赖的方法还试图将结构信息合并到神经模型中。
- 基本:依赖树+剪枝
- (Bunescu和Mooney 2005; Moneyy和Bunescu 2005; Zelenko,Aone和Richardella 2003)使用内核方法(例如子序列内核和依赖树内核)完成任务,
- MIL:Verga等(2018)引入了多实例学习(multi-instance learning, MIL) (Riedel等,2010;(Surdeanu et al., 2012)处理文档中多次提到的目标实体。—关系分类
- Peng et al.(2017)首先将依赖关系图分成两个dag,
- 然后将树LSTM模型(Tai et al., 2015)扩展到这两个图上进行n元关系提取。
- Song等人(2018b)使用图递归网络(Song等人,2018a)直接对整个依赖图编码,而不破坏它。
- AGGCN:和他们的模型的对比让人联想到CNN和RNN的对比。
- 剪枝策略。
- Xu等(2015b,c)采用神经模型编码最短依赖路径。
- Miwa和Bansal(2016)将LSTM模型应用于两个实体的LCA子树。Liu等(2015)将最短依赖路径与依赖子树相结合。
- Zhang等人(2018)采用了一种以路径为中心的修剪策略。
- AGGCNs,2019:与这些在预处理中去除边缘的策略不同,我们的模型以端到端的方式学会给每个边缘分配不同的权重
- 比较:与基于顺序的模型相比,基于依赖的模型能够捕获仅从表面形式难以理解的非局部句法关系(Zhang et al., 2018)。
- 软剪枝,GCN+attention+densely connection
- 端到端自动学习的剪枝—attention(自动筛去无关信息)
- 句子级(单句/句间),n-ary
- densely connection:
- 可以更深,
- 可以得到更好的表示
- 可得到局部/非局部依赖信息
- 基本:依赖树+剪枝
- 依赖树(Sunil Kumar Sahu,2019)
-
一个句子一个依赖树
-
无法捕捉非局部依赖
-
不适用于句子间关系抽取
*
-
1.2.2 句间关系抽取
- 句间关系抽取
- 依赖于局部和非局部依赖关系
- MIL:Verga等(2018)引入了多实例学习(multi-instance learning, MIL) (Riedel等,2010;(Surdeanu et al., 2012)处理文档中多次提到的目标实体。—关系分类
- 使用远程监控来自动生成文档级语料库(Peng et al., 2017;Song et al., 2018)。
- Peng et al.(2017)和Song et al.(2018)将基于图的LSTM网络用于n元RE在多个句子中用于蛋白质-药物-疾病关联。他们将关系候选词限制在最多两句话中。
- Verga等人(2018)考虑了文档级RE的多实例学习。
- GCNN(Sahu, S. K., et al. (2019)):
- 我们的工作与Verga等人(2018)不同,我们使用GCNN模型替换Transformer,使用非局部依赖(如实体指代消解)进行全抽象编码。
- 句间关系抽取
- 基于文档级图的标记边缘GCNN
- a novel inter-sentence relation extraction model that builds a labelled edge graph convolutional neural network model on a document-level graph
- 认为依赖树无法提取句子间关系
- 构造一个文档级图
- 节点-单词
- 边-局部或非局部依赖关系
- 由什么建立
- 局部依赖的连接词(来自语法解析和序列信息)
- 非局部依赖(来自指代消解+其他语义依赖
- why用这个图:
- 认为依赖树无法得到非局部依赖赖树无法得到非局部依赖
- 用GCNN进行编码
- 用MIL进行标签分类
- 如何推断关系
- 得分函数:MIL-based bi-affine pairwise scoring function (Verga et al., 2018)
- 用在实体节点表示上
- 得分函数:MIL-based bi-affine pairwise scoring function (Verga et al., 2018)
1.5 自动学习特征的方法
- 自动学习特征的神经网络方法(非联合模型)
- CNN、LSTM或Tree-LSTM对两个实体提及之间的单词序列进行处理(Zeng et al., 2014;dos Santos等,2015)
- Zeng等人(2014)利用卷积深度神经网络(CNN)提取词法和句子层次特征。
- dos Santos,Xiang和Zhou(2015)基于CNN模型,提出了一种基于CNN排名的分类模型(CR-CNN)。这些方法已经实现了高精度和召回率。
- 两个实体提及之间的最短依赖路径(Yan et al., 2015; Li et al., 2015)
- the minimal constituency sub-tree spanning two entity mentions(Socher et al., 2012),为每对实体提及编码相关信息
- Zhang, N., et al. (2019):与这些方法不同,我们利用来自KG和GCN的隐式和显式关系知识,而不是数据驱动的学习参数空间,其中类似关系可能具有不同的参数,阻碍了长尾类的泛化。
* pcnn/cnn+KG embedding+GCN+两层att[Zhang, N., et al. (2019)
* 用于:长尾不平衡数据
* long-tail:指的是类似正态分布的尾巴那一部分,也就是可用数据少
* 方法:远程监督
- CNN、LSTM或Tree-LSTM对两个实体提及之间的单词序列进行处理(Zeng et al., 2014;dos Santos等,2015)
1.4 联合抽取模型
- 基于特征
- 依赖于特征
- 联合实体识别和关系提取模型(Yu和Lam, 2010;Li and Ji, 2014;Miwa和Sasaki, 2014;Ren等人,2017)已经建立了利用这两个任务之间的密切互动
- 基于约束的:
- 早期的联合学习方法通过各种依赖关系连接两个模型,包括
- 通过整数线性规划解决的约束(Yang和Cardie,2013; Roth和Yih,2007),
- 卡片金字塔解析(Kate和Mooney,2010),以及
- 全局概率图形模型(Yu和Lam,2010; Singh等,2013)。
- 在后来的研究中,Li和Ji(2014)使用结构感知器和有效的波束搜索提取实体提及和关系,这比基于约束的方法显着更有效,更省时。
- Miwa and Sasaki (2014); Gupta et al. (2016); Zhang et al. (2017) 提出了表格填充方法,该方法提供了将更复杂的特征和算法结合到模型中的机会,例如解码中的搜索顺序和全局特征。
- 自动提取特征的(神经网络的)
- (Wang et al. (2016a)使用多层次关注CNN提取关系。
- Miwa和Bansal(2016):
- 本文模型的BiLSTM-GCN编码器部分类似于Miwa和Bansal(2016)提出的BiLSTM-TreeLSTM模型,因为它们也是堆叠的序列上的依赖树,用于联合建模实体和关系。每个句子使用Bi-LSTM进行自动特征学习,提取的隐藏特征由连续实体标记器和最短依赖路径关系分类器共享。然而,在为联合实体识别和关系提取引入共享参数时,它们仍然必须将标记者预测的实体提及通过管道连接起来,形成关系分类器的提及对。
- Zheng,et al(2017)
- 与在以前的工作中试图把每一对提到分类的工作不同,Zheng,et al。(2017)将关系提取和实体识别问题一样作为一个序列标注问题(NovelTagging)。这使他们关系提取的LSTM解码器的Bi-LSTM编码器。然而,尽管在《纽约时报》的数据集上显示出可喜的成果,他们的力量来自于专注于孤立的关系,完全放弃在数据集中出现少的重叠关系。
- 相比之下,提出所有类型的关系而被GraphRel以端到端的方式联合建模识别。
- NovelTagging (Zheng et al., 2017)
- 一个序列标记器,它预测每个句子词的实体和关系类
- 因为NovelTagging假设一个实体属于单一关系,所以精确度高,但回忆率低。
- Zeng等(2018)提出了一种端到端序列到序列的关系提取模型。
- 编码:它们使用一个Bi-LSTM对每个句子进行编码,
- 解码:并使用最后一个编码器隐藏状态初始化一个(一个解码器)或多个(多解码器)LSTMs,
- 以便动态解码关系三元组。
- 解码时,通过选择一个关系并从句子中复制两个单词来生成三元组。
- seq2seq设置部分处理三元组之间的交互。
- 然而,关系之间的相互作用只能通过在生成新关系时考虑以前生成的带有强制线性顺序的三元组来单向捕获。
- 在Graph-rel中,我们在LSTM-GCN编码器的基础上,采用2dn-phase的GCN来实现自动学习链接的字图上的实体和关系信息的传播。
- MultiDecoder (Zeng et al., 2018). (2019以前最先进的方法?)
- 将关系提取看作一个seq-seq问题,使用动态解码器提取关系三元组
- MultiDecoder使用动态的解码器生成关系三元组。由于对RNNrolling的固有限制,它能生成的三元组数目有限。
- 序列模型
- Sun等人。 (2018)优化全局损失函数,在最小风险培训框架下共同培养这两个模型。
- Takanobu等。 (2018)使用分层强化学习以分层方式提取实体和关系。
- GraphRel:2019
- 实体关系联合抽取
- 考虑关系之间的相互作用
- 解决重叠关系的提取
- 分两个阶段
- 第一阶段:序列文本特征和区域特征(Bi-lstm+Bi-GCN)
- 第二阶段:用第一阶段的结果构建了加权关系图,在用bi-GCN解决关系之间的问题
- 联合实体和关系提取模型的另一种方法是使用强化学习或最小风险训练,其中训练信号是基于两个模型的联合决策给出的。
- 用QA解决关系实体联合抽取:multi-turn QA,2019ACL
- MRC(Bert)+RL
1.6 GCN用于关系提取
- 近年来,在自然语言处理(NLP)任务中,GCN考虑依赖结构已经得到了广泛的应用。
- (Peng et al., 2017;Zhang等,2018;Qian等。2019; Luan et al., 2019) 考虑词序列的依存结构进行关系提取。
- AGGCNs,2019:
- GCNN(Sahu, S. K., et al. (2019)):
- GraphRel:Fu, T.-J., et al. (2019)
- 实体关系联合抽取
- 考虑关系之间的相互作用
- 解决重叠关系的提取
- 在GrpahRel中,不仅将Bi-LSTM和GCN堆叠起来考虑线性和依赖结构,还采用了2nd-phase关系加权的GCN来进一步建模实体和关系之间的交互
- 分两个阶段
- 第一阶段:序列文本特征和区域特征(Bi-lstm+Bi-GCN)
- 第二阶段:用第一阶段的结果构建了加权关系图,在用bi-GCN解决关系之间的问题
- Zhang, N., et al. (2019):与这些方法不同,我们利用来自KG和GCN的隐式和显式关系知识,而不是数据驱动的学习参数空间,其中类似关系可能具有不同的参数,阻碍了长尾类的泛化。
* pcnn/cnn+KG embedding+GCN+两层att[Zhang, N., et al. (2019)
* 用于:长尾不平衡数据
* long-tail:指的是类似正态分布的尾巴那一部分,也就是可用数据少
* 方法:远程监督
一些nlp+GCN的论文,2019
1.7 远程监督
- 远程监督模型
- (Mintz等,2009)(也是多实例学习)提出了DS来自动标记数据。DS不可避免地伴随着错误的标签问题。
- 从所有句子中提取特征,然后将它们输入到分类器中,该分类器忽略了数据噪声并会学习一些无效实例。
- 为了缓解噪声问题,(Riedel等人,2010; Hoffmann等人,2011)提出了多实例学习(MIL)机制。
- Riedel,Yao和McCallum(2010),Hoffmann等人(2011)和Surdeanu等人(2012)使用图形模型选择有效的句子和预测关系。
- Nguyen和Moschitti(2011)利用关系定义和Wikipedia文档来改善他们的系统。
- Surdeanu等,2012;
- 这些方法依靠传统的NLP工具提取句子特征。
- 最近,神经模型已被广泛用于RE;
- 这些模型可以准确地捕获文本关系,而无需进行明确的语言分析(Zeng等,2015; Lin等,2016; Zhang等,2018a)。
- 对抗训练(Wu等,2017; Qin等,2018),
- 噪声模型(Luo等,2017)和
- 软标签(Liu等,2017; Wang等)等(2018)。
- 为了进一步提高性能,一些研究将外部信息(Zeng等人,2017年;Ji等人,2017年; Han等,2018)和先进的培训策略(Ye等,2017年;刘等人。 2017; Huang和Wang,2017; Feng等,2018; Zeng等,2018; Wu等,2017; Qin等,2018)结合起来。
- 词性标签(Zeng等,2014)
- Zeng等人(2015年)使用PCNN来自动学习句子级特征并考虑了实体位置的结构信息。但是其MIL模块在训练过程中只能选择一个有效的句子,而没有充分利用监督信息。
- Lin et al。,(2016)提出利用注意力来选择内容丰富的句子。
- 选择性注意(Lin等,2016; Han等,2018),
- 依存关系解析信息(Surdeanu等,2012; Zhang等,2018b)。
- 这些工作主要采用DS制作大规模数据集,降低DS引起的噪声,不论长尾关系的影响如何。
- Ji et al. (2017):attention中包含了实体信息
- 考虑long-tail的:
- (Gui等,2016; Lei等,2018; Han等,2018b)。
- Gui et al。,2016)提出了一种基于解释的方法,
- (Lei et al。,2018)则使用了外部知识(逻辑规则)。
- 这些研究孤立地处理每个关系,而不管关系之间的丰富语义相关性。
- (Han et al。,2018b)提出了RE的分层关注方案,特别是对于长尾关系。
- Zhang, N., et al. (2019):与这些方法不同,我们利用来自KG和GCN的隐式和显式关系知识,而不是数据驱动的学习参数空间,其中类似关系可能具有不同的参数,阻碍了长尾类的泛化。
- pcnn/cnn+KG embedding+GCN+两层att[Zhang, N., et al. (2019)
- 用于:长尾不平衡数据
- long-tail:指的是类似正态分布的尾巴那一部分,也就是可用数据少
- 方法:远程监督
- 本文:DISTRE
- 假设:这些知识是识别更多关系的重要特征
- 我们假设,经过预训练的语言模型可为远程监督提供更强的信号,并基于无监督的预训练中获得的知识更好地指导关系提取。用隐式特征替换显式语言和辅助信息可改善域和语言的独立性,并可能增加公认关系的多样性。
- 做法:将GPT扩展到远程监督
- 假设:这些知识是识别更多关系的重要特征
- (Gui等,2016; Lei等,2018; Han等,2018b)。
- 考虑实体本身的信息
- APCNN+D,2017
- attention:用以选择有效实体
- 提取实体描述,补充背景知识(Freebase,Wikipedia)(CNN学习
- 用途:为预测关系提供了更多的信息,而且还为注意力模块带来了更好的实体表示
- APCNN+D,2017
- 最近的方法还利用辅助信息,例如
- 释义,关系别名和实体类型(Vashishth et al。,2018)
- 胶囊网络(Zhang等人,2018a),先前应用于监督环境(Zhang等人,2018b),也适用于远距离监督环境。
- n-gram based attention model that captures multi-word entity names in a sentence.
- 提取+嵌入+消歧联合模型 ,多词
- 改进的beam search
- 三元组 classifier
- 在关系抽取之前,分辨出真假样本:
* Takamatsu et al. (2012) :噪声滤波器
* 使用NER和依赖树的语言特征
* 难以避免错误传递
* DSGAN:仅使用word embedding
* DSGAN
* 目标:区分句子是不是好样本
* 只对标注为T的样本做区分,将FP重新归于负类
* 假设:标注为真的样本,多数为TP
* 生成器:区分句子是TP还是FP,无需监督
* 策略梯度:因为涉及离散采样
* 输入:word-embedding
* 判别器:
* 将生成器生成的样本标注为F
* 原来的样本,标注为T
* 训练判别器
* 如果生成集合中,TP多,而剩余集合中FP多,则鉴别器分类能力下降的很快
* 贡献
* 我们是第一个考虑对抗性学习去噪远程监督关系提取数据集的人。
* 我们的方法是句子级和模式诊断,因此它可以用作任何关系提取器(即插即用技术)。
* 我们证明我们的方法可以在没有任何监督信息下生成一个干净的数据集,从而提高最近提出的神经关系提取器的性能。
- (Mintz等,2009)(也是多实例学习)提出了DS来自动标记数据。DS不可避免地伴随着错误的标签问题。
1.8句子级关系提取
- 句子级关系提取
- (Socher et al., 2012;
- Zeng et al., 2014, 2015; .
- dos Santos et al., 2015;
- Xiao and Liu, 2016;
- Cai et al., 2016;
- Lin et al., 2016;
- Wu et al., 2017;
- Qin et al., 2018;
- Han et al., 2018a).
1.9MCR(阅读理解)(QA)
-
可将QA用于实体关系知识提取
-
Answers are text spans, extracted using the now standard machine reading comprehension (MRC) framework: predicting answer spans given context (Seo et al., 2016; Wang and Jiang, 2016; Xiong et al., 2017; Wang et al., 2016b).
-
主流MRC模型(Seo等,2016; Wang和Jiang,2016; Xiong等,2017; Wang等,2016b)在给定查询的段落中提取文本跨度。文本跨度提取可以简化为两个多类分类任务,即预测答案的开始和结束位置。
- 通过将两个softmax层应用于上下文令牌来预测起始和结束指数
- 基于softmax的跨度提取策略仅适用于单答案提取任务
-
BiDAF(Seo等人,2016)
-
类似的策略可以扩展到多段落MRC(Joshi等,2017; Dunn等,2017),其中答案需要从多个段落中选择。
-
多通道MRC任务可以通过连接段落轻松简化为单通道MRC任务(Shen et al。,2017; Wang et al。,2017b)。
- Wang等人。 (2017a)首先对通道进行排名,然后在选定的段落上运行单通道MRC。
- Tan等人。 (2017)与阅读理解模型一起训练通道排名模型。
- 像BERT(Devlin等,2018)或Elmo(Peters等,2018)这样的预训练方法已被证明对MRC任务非常有帮助。
- QANet(Yu等人,2018)
-
用QA解决关系实体联合抽取:multi-turn QA
1.10(槽填充)
- the multi-turn slot filling dialogue system (Williams and Young, 2005; Lemon et al., 2006);
1.11 中文关系抽取
- Chinese NRE(MG lattice多粒度点阵)
- 中文关系抽取
- 神经网络
- 多粒度
- 基于字符+基于词
- 解决的问题:
- 分段错误(分词?)
- 多粒度:将词级信息融入到字符序列输入中
- 多义性
- 借助外部语言库
- open-sourced HowNet API (Qi et al., 2019)
- 分段错误(分词?)
1.12 事件的时间关系
- 事件之间的TempRel可以用边缘标记的图表示,
- 其中节点是事件,
- 边缘用TempRels标记
- (Chambers和Jurafsky,2008; Do等,2012; Ning等,2017)。
- 给定所有节点,我们将进行TempRel提取任务,该任务是将标签分配给时间图中的边缘(通常包括 “vague” or “none” 标签以说明不存在边缘)。
- 分类模型:早期工作包括
- Mani等。 (2006);钱伯斯等。 (2007); Bethard等。 (2007); Verhagen和Pustejovsky(2008),
- 将问题表述为学习用于在不参考其他边的情况下确定局部每个边的标签的分类模型(即局部方法)。
- 缺点:通过这些方法预测的时间图可能会违反时间图应具有的传递特性。
- 例如,给定三个节点e1,e2和e3,本地方法可以将(e1,e2)= before,(e2,e3)= before和(e1,e3)= after分类,这显然是错误的,因为before是传递关系,并且(e1,e2)= before和(e2,e3)= before指示(e1,e3)= before。
- 贪婪方法:
- 最近的最新方法(Chambers等人,2014; Mirza和Tonelli,2016)通过
- 方法:以多步方式增长预测的时间图来规避此问题,
- 其中每次标记新边时,都会对图执行传递图闭合
- 从概念上讲,这是在贪婪地解决结构化预测问题。
- 整数线性规划:
- 另一类使用**整数线性规划(ILP)**的方法
- 全局方法:(Roth和Yih,2004)来获得对该问题的精确推断(即全局方法),
- 其中整个图被同时求解,
- 并且传递特性通过ILP约束自然地得到了强制执行
- (Bramsen等人,2006; Chambers and Jurafsky,2008; Denis and Muller,2011; Do等人,2012)。
- 通过将结构性约束也纳入学习阶段,最新的工作将这一想法进一步推向了新的境界(Ning等人,2017)。
- 如我们前面的示例所示,TempRel提取任务强烈依赖于先验知识。但是,对于产生和利用这种资源的关注非常有限。据我们所知,这项工作中提出的TEMPROB是全新的。
- Jiang et al. (2016) 提出的时间敏感关系(文学领域)是接近的(尽管还是很不一样)。
- Jiang et al. (2016) 从事知识图完成任务。
- 基于YAGO2(Hoffart等,2013)和Freebase(Bollacker等,2008),它手动选择了少数对时间敏感的关系(分别来自YAGO2的10个关系和Freebase的87个关系)。
- wasBornIn→diedIn
- graduateFrom→workAt
- 本文与Jiang的差别
- 一,规模差异:
- 蒋等。 (2016年)只能提取少量关系(<100),但我们研究的是通用语义框架(数以万计)以及其中任何两个之间的关系,我们认为它们具有更广泛的应用。
- 第二,粒度差异:
- Jiang等人中最小的粒度。 (2016)是一年,即只有当两个事件在不同年份发生时,他们才能知道它们的时间顺序,但是我们可以处理隐式时间顺序,而不必参考事件的物理时间点(即粒度可以任意小)。
- 第三,领域的差异:
- 江等。 (2016年)从结构化知识库(事件明确地锚定到某个时间点)中提取时间敏感关系,
- 我们从非结构化自然语言文本(其中物理时间点甚至不存在于文本中)中提取关系。
- 我们的任务更加笼统,它使我们能够提取出更多的关系,正如上面的第一个差异所反映的那样。
- 一,规模差异:
- VerbOcean(Chklovski和Pantel,2004),
- 它使用人工设计的词汇-句法模式(总共有12种这样的模式)来提取动词对之间的时间关系,这与本文提出的自动提取方法相反。
- 在VerbOceans中考虑的唯一词间关系是之前的,
- 而我们还考虑了诸如之后,包含,包含,相等和模糊的关系。
- 数量少:正如预期的那样,VerbOcean中的动词总数和之前的关系分别约为3K和4K,两者都比TEMPROB小得多,TEMPROB包含51K个动词框架(即,已消除歧义的动词),920万个条目以及最多总共80M个时间关系。
- Jiang et al. (2016) 提出的时间敏感关系(文学领域)是接近的(尽管还是很不一样)。
- 模型早期的时间关系提取系统使用手动标记的特征,这些特征已通过多项逻辑回归和支持向量机建模(Mani等,2006; Bethard,2013; Lin等,2015)。
- 其他方法则结合使用基于规则和基于学习的方法(D’Souza和Ng,2013年)
- 基于筛子的架构,例如CAEVO(Chambers等人,2014)和CATENA(Mirza and Tonelli,2016)。
- 最近,宁等人。 (2017年)
- 使用结构化学习方法,
- 并在TempEval-3(UzZaman等人,2013)和TimeBank-Dense(Cassidy等人,2014)上均表现出显着改进。
- 宁等。 (2018)
- 通过使用约束条件模型联合建模因果关系和时间关系并将问题表述为Interger线性规划问题,
- 显示了对TimeBank-Dense的进一步改进。
- 神经网络
- 基于神经网络的方法
- 既使用了递归RNN(Tourille等,2017; Cheng和Miyao,2017; Leeuwenberg和Moens,2018)
- 又使用了CNN(Dligach等,2017)。
- 此类模型还被用于根据一组预测的时间关系来构建文档时间线(Leeuwenberg和Moens,2018)。
- 这种成对注释的使用可能导致时间图不一致
- 已经通过采用时间推理来努力避免这一问题
- (Chambers和Jurafsky,2008;
- Yoshikawa等,2009;
- Denis和Muller,2011;
- Do等, 2012年;
- Laokulrat等人,2016年;
- Ning等人,2017年;
- Leeuwenberg和Moens,2017年)。
- 已经通过采用时间推理来努力避免这一问题
- 这种成对注释的使用可能导致时间图不一致
- 基于神经网络的方法
- 对事件持续时间进行建模
- (Pan等人,2007;
- Gusev等人,2011;
- Williams和Katz,2012),
- 尽管这项工作并未将持续时间与时间关系联系在一起(另见Filatova和Hovy,2001)。 )。
- Duration,Vashishtha, S., et al. (2019)
- 用于:时间关系表示
- 特点:将事件持续时间放在首位或居中
- 参考:Allen(1983)关于时间间隔表示
- 改变:为绝对的时间关系标注文本—>
- 将事件映射到其可能的持续时间上,
- 并将事件对直接映射到实际值的相对时间线
- 由持续时间来预测关系ok
- 由关系来预测持续时间降低了性能
2.应用
- 关系抽取用于
- biomedical knowledge discovery (Quirk and Poon, 2017),
- knowledge base population (Zhang et al., 2017)
- question answering (Yu et al., 2017).
3.模型细说
3.1 AGGCNs,2019
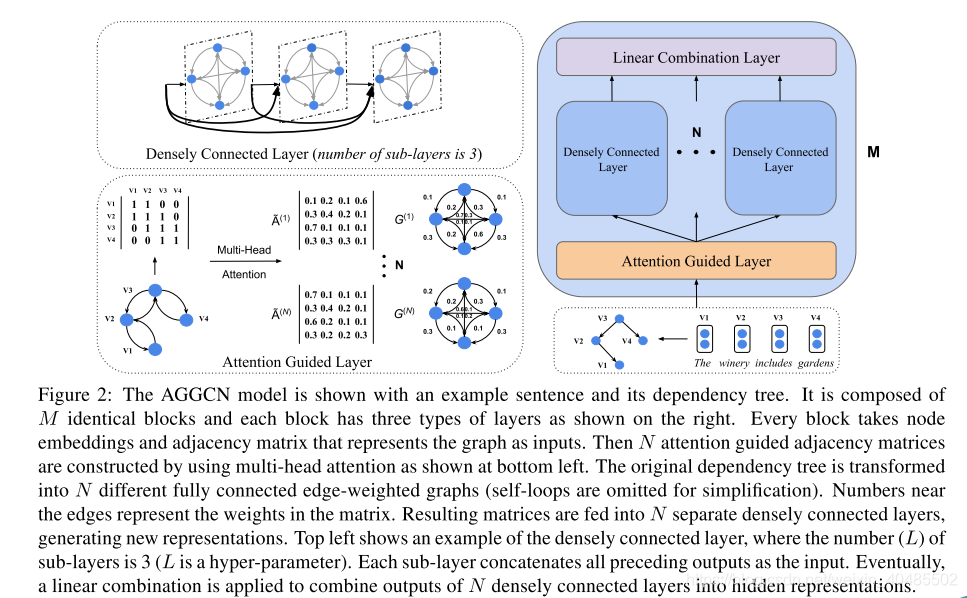
- AGGCNs(注意引导图卷积网络),2019
- 输入:全依赖树( full dependency trees
- 特点
- 端到端
-
软剪枝方法
- 基于规则的硬剪枝会消除树中的部分重要的信息。
- 给所有边分配权重,权重以端到端的形式学习得到–>自动学习剪枝
- 自动学习如何有选择地关注对re有用的相关子结构。
- 效果好
- 可并行地用于依赖树
- 对大图(长句子)友好
- 更有效地利用训练数据
- tips
- GCN+dense connection
- 目的:对一个大的全连通图进行编码
- 可得到局部和非局部依赖信息
- 2层GCN效果最好(经验)
- 可以学到更好的图形表示
- GCN+dense connection
- 可用于
- n元关系提取
- 大规模句子级别语料
- 效果更好
- 结构
- M块
- 每块三层
-
Attention Guided Layer–>N个attention-head
- 优点:
- 给所有边分配权重,权重以端到端的形式学习得到
- 实现自动学习剪枝
-
Densely connection Layer–>L个子层
- 带densely connection的GCN
- 优点:
- 在密集连接的帮助下,我们能够训练更深的模型,
- 允许捕获丰富的局部和非局部信息,从而学习更好的图表示。
- 优点:
- 带densely connection的GCN
-
线性层
-
- 每块三层
- FFNN汇总
- –前馈神经网络连接
- LR分类器
- M块
3.2 GCNN(Sahu, S. K., et al. (2019))
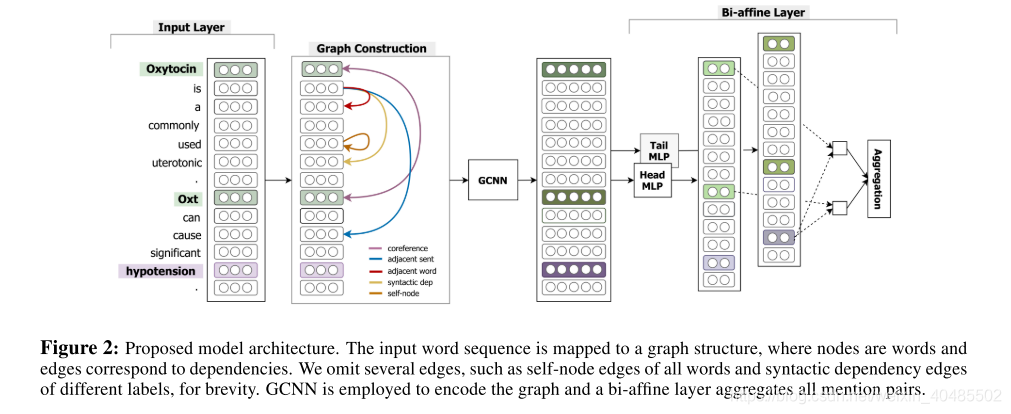
- GCNN(Sahu, S. K., et al. (2019)):
- 我们的工作与Verga等人(2018)不同,我们使用GCNN模型替换Transformer,使用非局部依赖(如实体指代消解)进行全抽象编码。
- 句间关系抽取
- 基于文档级图的标记边缘GCNN
- a novel inter-sentence relation extraction model that builds a labelled edge graph convolutional neural network model on a document-level graph
- 认为依赖树无法提取句子间关系
- 构造一个文档级图
- 节点-单词
- 边-局部或非局部依赖关系
- 由什么建立
- 局部依赖的连接词(来自语法解析和序列信息)
- 非局部依赖(来自指代消解+其他语义依赖
- why用这个图:
- 认为依赖树无法得到非局部依赖赖树无法得到非局部依赖
- 用GCNN进行编码
- 用MIL进行标签分类
- 输入:(e1,e2,t)
- t:一个文档
- 方法:多实例学习MIL来组合所有的mention -level pairwise
- 这里的mention:是实体的文字表述,可以有多种。
- 预测:目标对的最终关系范畴
- 结构
- 输入:
- 每个单词i及其与第一和第二目标实体的相对位置分别映射到实值向量wi、d1i、d2i
- 输入:
- 构造图:
- 多种边
- 句子的句法依赖边
- 共引用边
- 相邻句边
- 相邻词边
- 自节点边
- 为了学习到自身的信息
- 节点表示
- 由其邻居节点和边缘类型来学习节点表示(用GCNN)
- 多种边
- 用GCNN获得表示
- 用处:获得x的表示
- 公式
- 由第k个GCNN -block得到的表示。(共K个)
- l:边的类型
- 我们将K个GCNN块堆叠起来,以累积来自遥远邻近节点的信息,并使用边界选通控制来自邻近节点的信息。–最后一个是最终的)
- 减少参数
- 前n个类型保留单独的边的方向参数
- 其余使用相同参数。
- 避免过拟合
- 用MIL 分类
- 由于每个目标实体在一个文档中可以有多个提及,
- MIL:因此我们采用基于多实例学习(multi-instance learning, MIL)的分类方案,
- 得分函数:使用双仿射两两评分来聚合所有目标提及对的预测(Verga et al., 2018)。
- 做法:
- FFNN:首先利用两层前馈神经网络(FFNN)将每个词i投影到两个独立的潜在空间中,对应于目标对的第一个(head)或第二个(tail)参数。
- 2个2层
- 公式
- 双仿射得分:然后,通过双仿射层生成二维水平的两两mention配对置信得分,并将其聚合得到实体水平的两两配对置信得分。
- FFNN:首先利用两层前馈神经网络(FFNN)将每个词i投影到两个独立的潜在空间中,对应于目标对的第一个(head)或第二个(tail)参数。
- 输入:
3.3 GraphRel
- GraphRelFu, T.-J., et al. (2019).:
- 实体关系联合抽取
- 关系加权的GCNs
- 考虑实体关系间的相互作用
- 线性核依赖结构->文本的序列特征和区域特征
- 完整的词图:->提取文本所有词对之间的隐含特征
- 基于图的方法,有利于对重叠关系的预测
- 数据集:NYT,WebNLG
- 三个关键
- 想要自动提取特征的联合模型
- 通过堆叠Bi-LSTM语句编码器和GCN (Kipf和Welling, 2017)依赖树编码器来自动学习特征
- 用以考虑线性和依赖结构
- 类似于Miwa和Bansal(2016)(一样是堆叠的)
- 每个句子使用Bi-LSTM进行自动特征学习,
- 提取的隐藏特征由连续实体标记器和最短依赖路径关系分类器共享。
- 然而,在为联合实体识别和关系提取引入共享参数时,
- 它们仍然必须将标记者预测的实体提及通过管道连接起来,
- 形成关系分类器的提及对。
- 类似于Miwa和Bansal(2016)(一样是堆叠的)
- 考虑重叠关系
- 如何考虑关系之间的相互作用
- 2nd-phase relation-weighted GCN
- 重叠关系(常见)
- 情况
- 两个三元组的实体对重合
- 两个三元组都有某个实体mention
- 推断
- 困难(对联合模型尤其困难,因为连实体都还不知道)
- 情况
- 想要自动提取特征的联合模型
- work
- 学习特征
- 通过堆叠Bi-LSTM语句编码器–序列特征
- 输入:单词u的单词嵌入Word(u)+词性嵌入POS(u)
- 嵌入矩阵:
- 单词:glove
- 词性:随机初始化,一起训练
- 公式:
- ⊕??异或?只是个连接符号
- bi-GCN (Kipf和Welling, 2017)依赖树编码器来自动学习特征–区域特征
- 输入:句子的依赖树的邻接矩阵
- 公式:
- –concatenate
- 通过堆叠Bi-LSTM语句编码器–序列特征
- 第一阶段的预测:
- GraphRel标记实体提及词,预测连接提及词的关系三元组
- 同时,用关系权重的边建立一个新的全连接图(中间图)(一个关系一个图)
- 指导:关系损失和实体损失
- 输入:上面的特征
- 损失:分类损失函数–记做
- 预测词的实体
- 提取每一对词的关系
- 对于关系提取,我们删除了依赖边并对所有的词对进行预测。对于每个关系r,我们学习了权值矩阵 ,并计算了关系倾向score
- 正向和反向不同
- 无关系score(w1,null,w2)
- 概率
- 无三元组计数约束
- 损失函数:利用$P_r(w1,w2),记做rloss_{1p}
- 第二阶段的GCN
- 通过对这个中间图的操作
- 考虑实体之间的交互作用和可能重叠的关系
- 对每条边进行最终分类
- 在第二阶段,基于第一阶段预测的关系,我们为每个关系构建完整的关系图,并在每个图上应用GCN来整合每个关系的信息,进一步考虑实体与关系之间的相互作用。
- 对每一个关系
- 依据 (作为边权)构建图(一个关系一个图)
- 对每一个图用Bi-GCN
- 考虑出度和入度两个方向
- 第二阶段的Bi-GCN考虑关系权重的传递并且从每个词中提取出更充足的信息
- 再分类
- 对得到的新的特征,在进行一次命名实体识别和关系分类,可以得到更稳定的庴预测。
- 损失函数:
- 学习特征
- 本文贡献
- 我们的方法考虑了线性和依赖结构,以及文本中所有词对之间的隐含特征;
- 我们对实体和关系进行端到端的联合建模,同时考虑所有的词对进行预测;
- 仔细考虑实体和关系之间的交互。
- 训练
- 实体识别:
- 标签:(Begin, Inside, End, Single, Out)
- 损失:交叉熵(分类损失
- 对eloss1p和eloss2p来说,ground-truth的实体(标准答案)是相同的
- 关系抽取
- 使用one-hot关系向量对每一个单词对
- 既然我们是基于词组来预测关系,那么ground truth(标准答案)也应该基于词组。
- 也就是说,word United与word Barack和word Obama都有“总统”的关系,word States也是如此。
- 我们认为,这种基于单词对的关系表示为GraphRel提供了它需要学习提取关系的信息。对rloss1p和rloss2p来说,groundtruth(标准答案)关系向量是相同的。
- 作为实体损失,我们也使用交叉熵作为训练中的分类损失函数。
- 对于eloss和rloss,我们为类内的实体或关系项添加了额外的double-weighted。
- 总的损失:
- 以end-to-end的方式最小化loss
- 实体识别:
- inference
- head prediction:
- 关系被提取的前提:
- 两个实体均被识别
- 且Pr(e1,e2)最大
- 关系被提取的前提:
- 平均预测
- 一对实体提及对的所有词对的概率平均最大的关系
- threshold阈值预测
- 独立地思考实体提及对的所有词对
- 实体提及对中的所有词对中有θ以上占比认为此关系最有可能,则提取此关系
- head prediction:
3.4 PCNN/CNN+KATT[Zhang, N., et al. (2019)
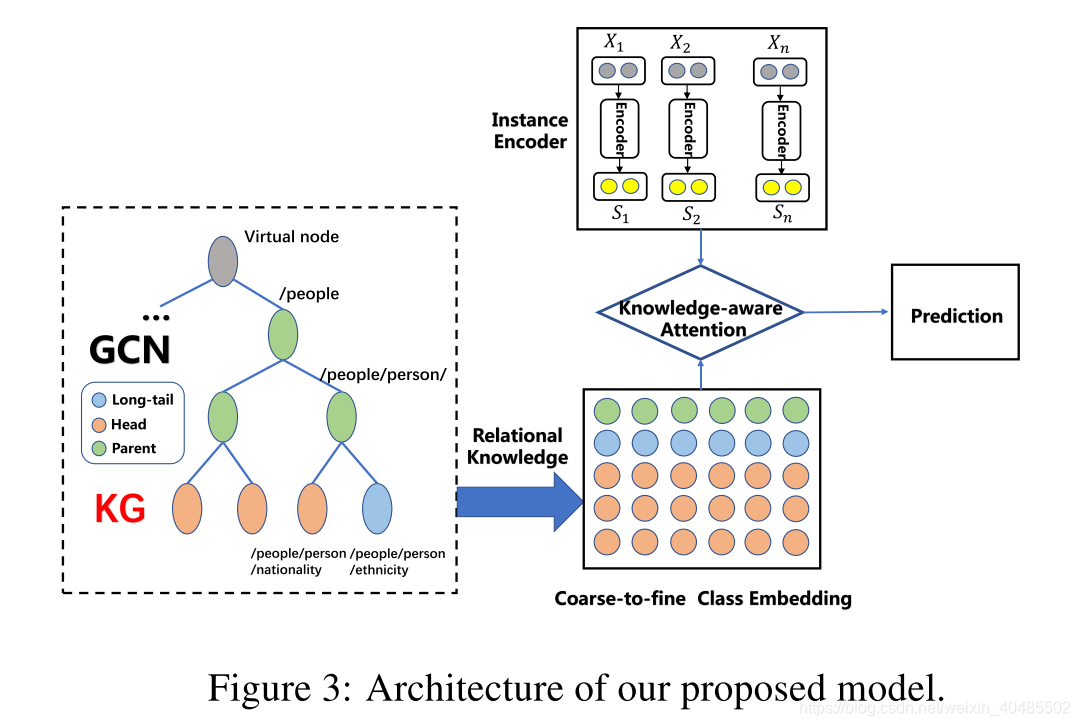
-
pcnn/cnn+KG embedding+GCN+两层att[Zhang, N., et al. (2019)
- 用于:长尾不平衡数据
- long-tail:指的是类似正态分布的尾巴那一部分,也就是可用数据少
- 方法:远程监督
- 挑战:
- long-tail的可用数据少
- 目前的远程监督方法都忽略了这个,所以难以从文本中提取全面的信息
- long-tail不容忽略:NYT中70%都是(Riedel et al., 2010; Lei et al., 2018)
- 如何在训练实例有限的情况下来学习?
- long-tail的可用数据少
- 启发:long-tail数据和分布顶部的数据之间有丰富的语义关联
- 解决:可以用顶部数据来提高尾部数据的performance
- 如果语义上相似,就可以转换
- 这样可以增强RE,缩小潜在的搜索空间,减少关系之间的不确定性(Ye et al., 2017)
- eg:如果一对实体包含/人/死者/死亡地点(多),很有可能包含/人/死者/埋葬地点(少)。
- 存在两个问题
- 关系知识的学习:也可能导致负迁移
- 利用关系知识:
- 将关系知识集成到现有的RE模型也是一个挑战
- 做法
- 编码器(Instance Encoder):
- 首先使用CNN(Zeng et al。,2014,2015)编码
- 输入:一个实例及其实体提及对
- 语义编码为一个向量
- 关系知识学习(Relation Knowledge Learning):
- 预训练的嵌入:以知识图谱的嵌入来学习隐式关系知识
- (Yang et al。,2015):语义相近,嵌入相近
- 使用 TransE (Bordes et al., 2013)
- 将通用的消息传递推理算法与神经网络的对应算法进行同化–>得到更好的嵌入
- 利用图卷积网络学习显式关系知识
- KGs:有多对一关系,数据稀疏–无足够的关系信号
- 用GCN来学习
- 输出:concate(GCN输出,KG embedding)
- 预训练的嵌入:以知识图谱的嵌入来学习隐式关系知识
- knowledge-aware attention
- 以从粗到细的注意力机制将关系知识和编码句子注入到model中
- 目标:选择与信息圈圈匹配的最informative instance
- 编码器(Instance Encoder):
- 好处
- 关系知识:
- 为关系预测提供了更多信息
- 为attention提供参考–提高long-tail的性能
- 关系知识:
- 用于:长尾不平衡数据
-
详细
- Instance Encoder
- 输入:实例s={w1,w2,…}和他的两个提及hi,ti
- 输出:连续的低纬向量x
- 嵌入层
- 给定实例s
- word embedding:
- 每个单词,映射到skip-gram的嵌入上(Mikolov et al., 2013)
- position embedding
- (Zeng et al。,2014)
- 每个单词:它与两个实体的相对距离嵌入到两个dp维的想两种
- 两个嵌入连接起来–>每个单词的最终输入
- 编码层
- 输入:上面得到的嵌入
- 方法(两个):
- CNN(Zeng et al。,2014)
- PCNN(Zeng et al。,2015)
- 其他也可,但卷积效果最好
- 输出:嵌入的组合–实例嵌入
- relation knowledge learning
- 给定:
- 预先训练的KG嵌入
- 预定义的类(关系)层次结构,
- 我们首先
- 利用KGs得到隐式关系知识
- 初始化层次结构标签图;
- KG的基本关系(叶子)
- 其向量表示,可由TransE的KG嵌入来初始化
- 也可用其他
- 其向量表示,可由TransE的KG嵌入来初始化
- 泛化得到更高级的关系集合(通常包含多个子关系(在基本几何中的))
- 非叶子的向量:可用所有子节点的向量平均得到
- 树结构的
- 生成过程:递归
- 父节点:虚拟的
- 方法:k-means,层次聚类
- KG的基本关系(叶子)
- GCN:
- 由于KG中的一对多关系和不完整性,KG嵌入每个标签所获得的隐含相关信息是不够的。
- 然后我们应用两层GCN来学习标签空间中明确的细粒度关系知识。
- 输入:KGs的预训练关系嵌入
- 第i个标签:组合其父母和子女的标签得到
- 第二层同上,得到
- 输出: –concate–>每一层的,每个节点都有一个q
- 给定:
- knowledge-aware attention
- 问题:
- CNN,loss=交叉熵–ok
- 但long-tail,所以泛化不良
- 解决
- 将句子向量与对应的类嵌入匹配
- 成为检索问题
- 根据他们的类型来组合这些class embedding(依据层次图)
- 得到关系表示公式:
- 然后,我们需要在不同层上组合关系表示–还是注意力机制
- 概率:
- 问题:
- Instance Encoder
3.5 a multi-turn QA
- a multi-turn QA
- 多次QA
- 实体和关系的类型:以question answering template为特征
- 提取关系和实体:通过回答问题
- 用MRC提取实体、关系:
- Answers are text spans, extracted using the now standard machine reading comprehension (MRC) framework: predicting answer spans given context (Seo et al., 2016; Wang and Jiang, 2016; Xiong et al., 2017; Wang et al., 2016b).
- eg:为了得到上表,有以下问答
- • Q: who is mentioned in the text? A: Musk;
- • Q: which Company / companies did Musk work for? A: SpaceX, Tesla, SolarCity, Neuralink and The Boring Company;
- • Q: when did Musk join SpaceX? A: 2002;
- • Q: what was Musk’s Position in SpaceX? A: CEO.
- 优点:
- 可得到层次依赖
- 问题查询为我们编码重要的先验信息。
- 类对QA来说有助于回答问题—这个可以解决很多问题
- 传统的方法中类仅仅是索引,并且不编码类的任何信息
- QA框架提供了一种同时提取实体和关系的自然方式
- 回答问题
- 有答案,则关系成立,且结果为我们希望的实体抽取
- 回答问题
- 两个阶段
- 1)头部实体提取阶段
- 2)关系和尾部实体提取阶段:
- work:
- 生成问题
- 通过MRC确定答案范围
- 强化学习
- 处理多回合问题的连接
3.6 APCNN+D,2017
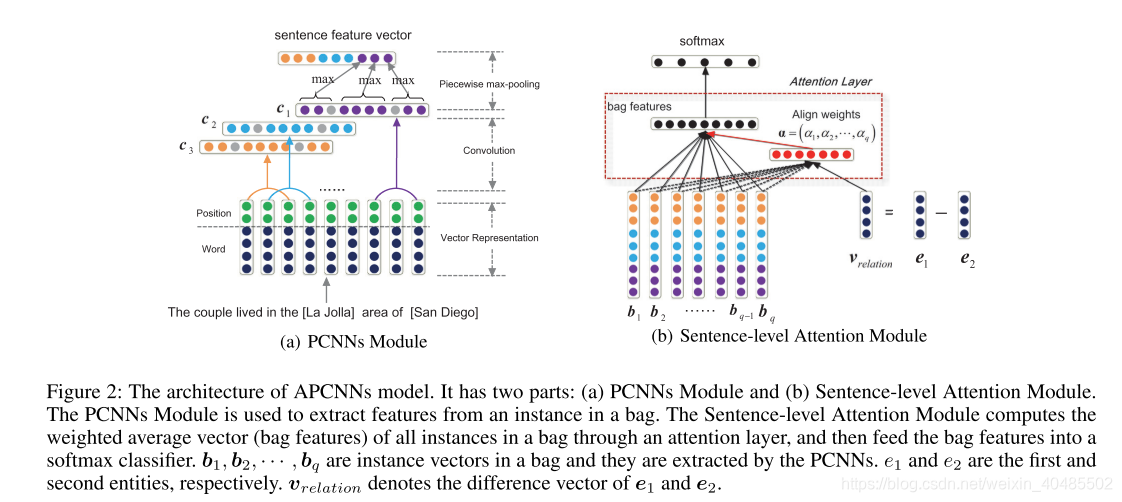

- APCNN
- 任务定义
- 所有句子被分到N组bags中,
- 每个bag中的的句子都描述了同一组实体的关系r(e1,e2)。
- 每个bag中有qi句句子, (i=1,2,…,N)
- 这个任务的目标是,预测每个bag对应的label。
- 预测看不见的袋子的标签。
- instance–句子
- 以上的不足:
- (1)一个袋子可能包含多个有效句子。
- (2)实体描述可以提供有用的背景知识,是完成任务的有用资源。
- 基于此提出本文的创新点:
- 结合zeng和概率图:使用神经网络提取特征+从一个包提取多个有效句子
- PCNN(得到句子特征)–>结果加权和(权重是隐层计算)–>(包的特征)
- attention:用以选择有效的实体
- 权重:句子向量v;e1-e2
- 添加实体描述信息
- 使用传统CNN从Freebase或Wikipedia中抽取实体特征
- 用途:为预测关系提供了更多的信息,而且还为注意力模块带来了更好的实体表示
- 结合zeng和概率图:使用神经网络提取特征+从一个包提取多个有效句子
- 本文贡献:
- (1)我们引入了一个句子级别的注意力模型来选择一个袋子中的多个有效句子。该策略充分利用了监督信息。
- (2)我们使用实体描述为预测关系和改善实体表示提供背景知识;
- (3)我们对广泛使用的数据集3进行实验,并达到了最新水平。
- 结构
- PCNNs Module
- 组成
- Vector Representation,
- Convolution and
- Piecewise Max-pooling.
- 目的:提取包中一个句子的特征向量
- 输入:
- word_embedding:word2vec
- position embedding
- 相对e1的
- 相对e2的
- ???有负的怎么求?
- -70-70–>140
- 卷积:
- w:窗口大小,卷积核的尺寸?
- 当前词,及其前后词组成一个小窗口。
- w=3
- i:1~n,n为卷积核W的数目
- j:1~|S|-w+1,|S|–句子长度
- 结果得到
- w:窗口大小,卷积核的尺寸?
- Piecewise Max-pooling(分段最大池化)
- 分段依据:两个实体将句子分成三段
- 结果:
- 输出:
- 组成
- Sentence-level Attention Module.
- Attention Layer
- 输入:
- 一个句子的表示
- 句中关系的表示
- 想法:如果句中关系为r,则 ,没有则低
- 权重:
- 输出:
- 输入:
- Softmax Classifier
- Attention Layer
- 实体描述
- 输入:
- 实体和描述中的词的嵌入可以有word_embedding得到
- 实体描述:由远程监督得到
- 来源:Freebase和wikipeidia
- 去除模棱两可的(含may refer to)
- CNN:d_i由CNN计算得到,Wd
- 目标:让实体的表示和他的描述尽可能接近
- 得到了实体描述对
- 损失函数:
- 输入:
- PCNNs Module
- 任务定义
3.7 Chinese_NRE(MG_lattice)
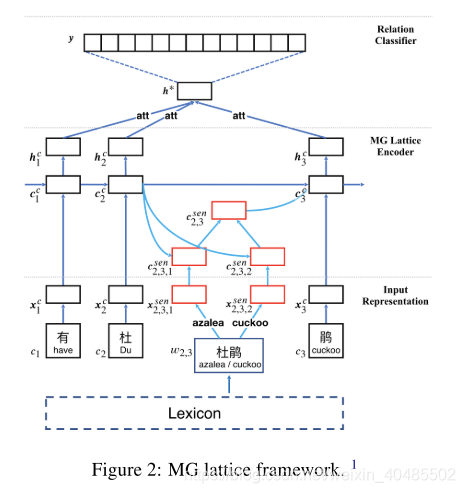
- Chinese NRE(MG lattice多粒度点阵)
- 中文关系抽取
- 神经网络
- 多粒度
- 基于字符+基于词
- 解决的问题:
- 分段错误(分词?)
- 多粒度:将词级信息融入到字符序列输入中
- 多义性
- 借助外部语言库
- open-sourced HowNet API (Qi et al., 2019)
- 得到一个含义一个嵌入
- 分段错误(分词?)
- 输入
-
character
- 每个字的嵌入->一个句子
- Skip-gram model (Mikolov et al., 2013).
- 位置嵌入position feature–
- 最终输入
-
word
- 文本中所有出现在词典上的单词–>word2vec–>向量表示
- word2vec:不考虑多义词
- 用HowNet作为外部知识库纳入model–>一个含义对应一个向量
- 操作
- 给定单词
- 通过HowNet检索,得到他的K个含义
- 每个含义映射到一个向量
(SAT模型,基于skip-gram)
- SAT (Sememe Attention over Target)
- 得到他的含义向量集合:
- 这就是 的表示
-
- encoder
- 基于字符的LSTM
- base lattice LSTM encoder(在上面基本LSTM的基础上)
- 为了控制每个词的贡献,需要额外的门:
- 最后得到隐层表示
- MG lattice LSTM encoder
- basic一个单词一个向量,不考虑多义词,MG考虑
- 最后得到隐层表示
- 基于字符的LSTM
- 关系分类器
- 上面得到了字符级的h
- attention连接:
- 概率
- 损失函数
3.8 DISTRE
- DISTRE
- 假设:这些知识是识别更多关系的重要特征
- 我们假设,经过预训练的语言模型可为远程监督提供更强的信号,并基于无监督的预训练中获得的知识更好地指导关系提取。用隐式特征替换显式语言和辅助信息可改善域和语言的独立性,并可能增加公认关系的多样性。
- 做法:将GPT扩展到远程监督
- 选择性注意机制+GPT
- 选择性注意机制:用以处理多实例
- 这样可以最大程度地减少显式特征提取,并减少错误累积的风险。
- 选择性注意机制:用以处理多实例
- self-attention的体系结构允许模型有效地捕获远程依赖关系,
- 而语言模型则可以利用有关在无监督的预训练过程中获得的实体与概念之间的关系的知识。
- 选择性注意机制+GPT
- 数据集:NYT10
- 本文贡献
- 通过汇总句子级别的信息并有选择地关注以产生袋子级别的预测(第3节),我们将GPT扩展为处理远程监管数据集的袋子级别,多实例训练和预测。
- 我们在NYT10数据集上评估了精细调整的语言模型,并证明了它与RESIDE(Vashishth等人,2018)和PCNN + ATT(Lin等人,2016)相比,在持续评估中(§4,§5.1)获得了最新的AUC。
- 我们通过对排名预测进行手动评估来跟踪这些结果,这表明我们的模型预测了一组更多样化的关系,并且在较高的召回水平下表现尤其出色(第5.2节)。
- 假设:这些知识是识别更多关系的重要特征
- model
- 标签r不可靠,所以用bag_level
- bag:
- 包的表达式:
- 包的表达式:
- 输入表达:
- 字节对编码(BPE)对输入文本进行标记化(Sennrich et al。,2016)。
- BPE算法创建以单个字符开头的子单词标记的词汇表。
- 然后,该算法将最频繁出现的令牌迭代合并到新令牌中,直到达到预定的词汇量为止。
- 对于每个令牌,我们通过将相应的令牌嵌入和位置嵌入相加来获得其输入表示。
3.9 n-gram based attention model (多词实体)
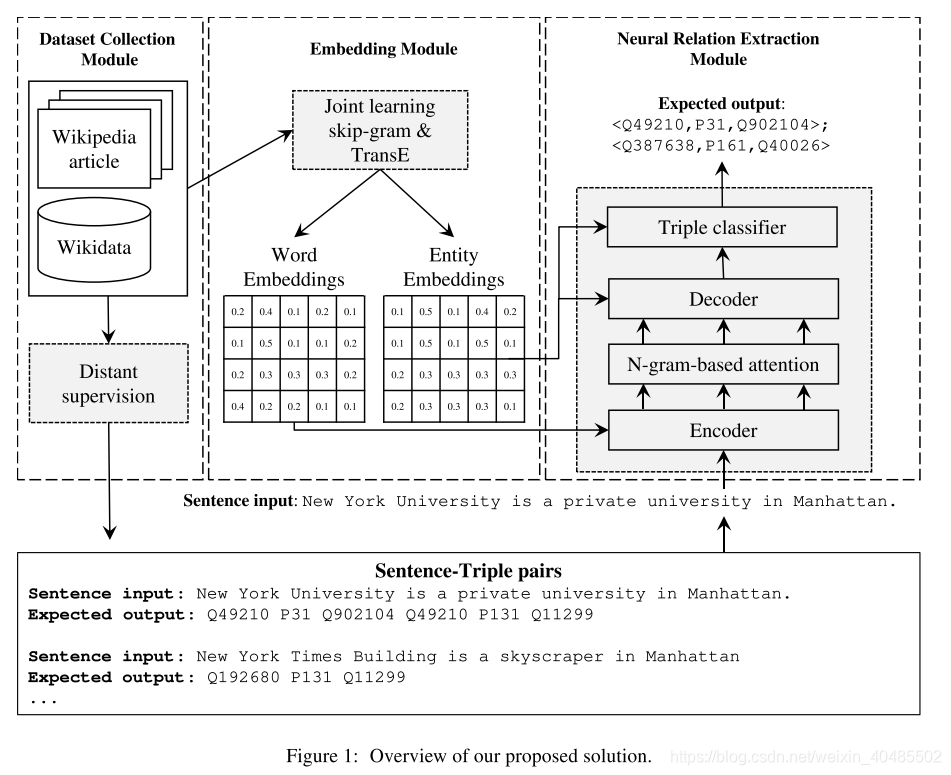
- n-gram based attention model that captures multi-word entity names in a sentence.
- 继序列到序列架构(Bahdanau et al。,2015)成功用于从结构化数据生成句子(Marcheggiani和Perez-Beltrachini,2018; Trisedya et al。,2018)之后,我们采用这种架构进行相反的工作,也就是从句子中提取三元组。
- 输入:句子
- 输出:三元组
- 应用情景:h,t为KB中已有实体,r为关系列表中的关系,<h,r,t>不存在于KB中
- 目的:发现h,t中更多的关系
- 要求:三元组中的关系,实体要规范,可以映射到KB中对应的ID上
- 提取+嵌入+消歧(规范化)–从句子到KB的端到端
- 架构:encoder-decoder的translation model
- 标准的encoder-decoder无法处理多词实体/谓词
- n-gram attention–得到单词级的信息
- 基于n-gram的注意力形式,该形式可以计算注意力权重的ngram组合来捕获语音或名词短语上下文,从而补充标准注意力模型的单词级注意力。
- 因此,我们的模型可以更好地捕获实体和关系的多词上下文。
- pre-train
- 单词:skip gram
- 嵌入:TransE
- 优点:
- 首先,嵌入捕获可单词和实体之间的关系,这对于命名实体消除歧义至关重要。
- 其次,实体嵌入保留了实体之间的关系,这有助于建立一个高度准确的分类器来过滤无效的提取的三元组。
- 数据不足:远程监督
- 为了解决缺少完全标记的训练数据的问题,我们采用了远程监督来生成对齐的句子对和三对作为训练数据。
- 增强
- 我们通过co-reference resolution (Clark和Manning,2016)
- co-reference resolution有助于提取带有隐式实体名称的句子,从而扩大候选句子的集合以与KB中现有的三元组对齐。
- dictionary-based paraphrase detection(Ganitkevitch等,2013; Grycner和Weikum,2016
- 有助于过滤不表达实体之间任何关系的句子。
- 我们通过co-reference resolution (Clark和Manning,2016)
- 贡献
- 联合关系抽取+消歧的model:该模型减少了关系提取和NED之间的错误传播,而现有方法则容易发生这种错误传播。
- 基于n-gram的注意力模型:
- 以有效地将实体及其关系的多词提及映射到唯一标识的实体和谓词中。
- 我们建议联合学习单词和实体嵌入,以捕获单词和实体之间的关系,以消除命名实体的歧义。
- 我们进一步提出一种改进的波束搜索和三元组分类器,以生成高质量的三元组。
- 我们在两个真实世界的数据集上评估提出的模型。
- 我们将远程监控与co-reference resolution和dictionary-based paraphrase detection相结合,以获取高质量的训练数据。
- 实验结果表明,我们的模型始终优于神经关系提取(Lin等人,2016)和最新的NED模型(Hoffart等人,2011; Kolitsas等人,2018)的强大基线。
3.10 Duration:Vashishtha, S., et al. (2019)
- Duration,Vashishtha, S., et al. (2019)
- 用于:时间关系表示
- 特点:将事件持续时间放在首位或居中
- 参考:Allen(1983)关于时间间隔表示
- 改变:为绝对的时间关系标注文本—>
- 将事件映射到其可能的持续时间上,
- 并将事件对直接映射到实际值的相对时间线
- 由持续时间来预测关系ok
- 由关系来预测持续时间降低了性能
- 目的:
- 对于句子中提到的每对事件,我们旨在一起预测这些事件的相对时间表及其持续时间。
- 然后,我们使用一个单独的模型从相对时间线中导出文档时间线
- Relative timelines
- The relative timeline model:
- 事件模型:
- 持续时间模型:
- 关系模型:
- 用于:
- 上下文嵌入:来自ELMO(Peters et al., 2018)的tune–>D维度
- embedding:三个M维上下文嵌入的concate
- 多层点积注意力:用于句子的embedding-H
- Event model
- 谓词k所指的事件表示为 –由点积注意力的变体建立
- 公式:
- eg:举例来说,
- my dog has been sick for about 3 days now
- 图2中目前sick的谓词以sick为根,因此我们将生病的隐藏表示形式表示为 。
- 类似地, 等同于been sick for now的隐藏状态表示堆叠在一起。
- 然后,如果模型得知时态信息很重要,则been可能会引起注意。
- Duration model
- 谓词k所代表的事件的历时 –与事件模型类似
- H:不是堆叠整个谓词的表达,而是堆叠整个句子的表达
- 绝对持续时间的两个model
- softmax model
- 无二项式模型的那个约束
- MLP:
- 产生11个持续时间的概率:
- 二项式model
- 二项式模型要求:11个持续时间值的概率 在持续时间rank中是凹的
- RELu-MLP: –这是个值而不是向量
- 概率:
- loss:
- 11个持续时间rank
- stant (0), seconds (1), minutes (2), …, centuries (9), forever (10)
- – and n is the maximum class rank (10)
- softmax model
- Relation model
- 谓词i和谓词j所指事件的关系
- similar attention mechanism
- 我们的时间模型背后的主要思想是将事件和状态直接映射到时间轴,我们通过参考间隔[0,1]表示该时间轴
- 对situation k,开始点b_k<=e_k
- MLP:
- 损失函数:
- 对situation k,开始点b_k<=e_k
- final loss:
- The relative timeline model:
- Duration-relation connections
- 我们还尝试了四种架构,其中持续时间模型和关系模型在Dur->Rel或Rel->Dur两个方向中相互连接
- Dur->Rel架构
- 2种方法
- (i)另外将谓词i和谓词j的二项式持续时间概率连接起来
- (ii)完全不使用关系表示模型。
- (i)另外将谓词i和谓词j的二项式持续时间概率连接起来
- 2种方法
- Rel->Dur架构
- (i)通过连接关系模型中的
和
来修改
- (ii)我们完全不使用持续时间表示模型,而是使用预测的相对从关系模型获得的持续时间
,并通过二项分布模型。
- (i)通过连接关系模型中的
和
来修改
- Document timelines
- UDST开发集中的文档引入了隐藏的文档时间线,两个方法:
- (i)实际的成对滑块注释actual pairwise slider annotations
- (ii)由UDS-T开发集上性能最佳的模型预测的滑块值。
- 假设一个隐层时间线
- 通过锚定所有谓词的起点,使这些潜在时间线与相对时间线相连,以使文档中始终存在以0为起点的谓词,并为每个事件i和j定义辅助变量
- 根据关系损失为每一个文档学习T
- 进一步约束T:
- 二项式分布来预测持续时间
- UDST开发集中的文档引入了隐藏的文档时间线,两个方法:
3.11DSGAN(远程监督,句子级去噪)
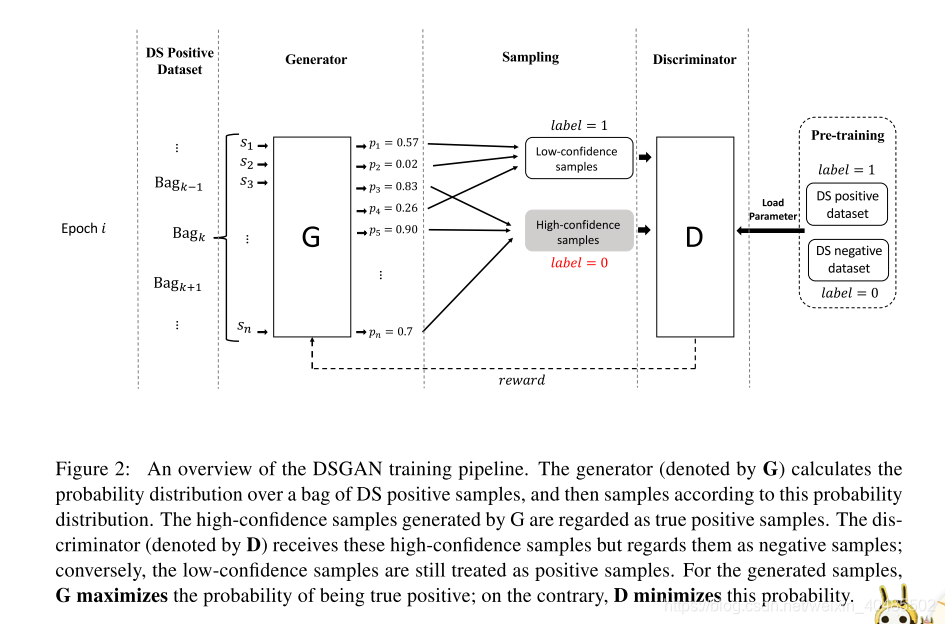
- DSGAN
- 目标:区分句子是不是好样本
- 只对标注为T的样本做区分,将FP重新归于负类
- 假设:标注为真的样本,多数为TP
- 生成器:区分句子是TP还是FP,无需监督
- 策略梯度:因为涉及离散采样
- 输入:word-embedding
- 判别器:
- 将生成器生成的样本标注为F
- 原来的样本,标注为T
- 训练判别器
- 如果生成集合中,TP多,而剩余集合中FP多,则鉴别器分类能力下降的很快
- 贡献
- 我们是第一个考虑对抗性学习去噪远程监督关系提取数据集的人。
- 我们的方法是句子级和模式诊断,因此它可以用作任何关系提取器(即插即用技术)。
- 我们证明我们的方法可以在没有任何监督信息下生成一个干净的数据集,从而提高最近提出的神经关系提取器的性能。
- 目标:区分句子是不是好样本
- 预训练:生成器和判别器
* 必须
* 目标:得到更好的初始化参数,容易收敛
* 判别器:远程监督数据集的positive set P和negtive set
* 生成器:
* 预训练到精度达到90%
* 使用P和另一个negtive set
* 让生成器对P过拟合
* 目标:让生成器在训练过程开始时错误地给出所有有噪声的DS的阳性样本高概率
* 之后会通过对抗学习降低FP的这个概率 - 网络
- CNN:
- 参数比RNN少
- 语言理解能力强
- 输入:句子+实体对
- 使用:word embedding + position embedding
- CNN:
- 生成器
- 与计算机视觉的区别
- 不用生成全新的句子(图),只需要从集合中判别出TP即可
- 是“从概率分布中抽样 ”的离散的GANs
- 与计算机视觉的区别
- 句子
是TP的概率
- 生成器:
- 判别器:
- 1个epoch扫描一次P
- 更有效的训练+更多反馈
- P–>划分成N个batch
- 处理完一个batch,更新一次参数
- 目标函数
- 生成器
- 对一个batch ,生成器得到他的概率分布
- 依据这个概率分布采样,得到集合T
- –对G而言是正样本
- 大的,是生成器视为正例的句子,但对判别器而言是负例
- 为了挑战判别器,损失函数(最大化):
- –感觉应该是G,原文是D
- 判别器:
- 样本:
- T:对D而言是负样本
- :正样本
- 损失:
- 与二分类相同
- (最小化)
- 可以用任何梯度的方法优化
- epoch:
- 与先前工作中的鉴别器的常见设置不同,
- 我们的鉴别器在每个epoch开始时加载相同的预训练参数集
- 原因1:想要的是强大的生成器而不是判别器
- 原因2:生成器只采样,不生成全新的数据
- 所以,判别器相对容易崩溃
- 假设:一个判别器在一个epoch内具有最大的性能下降时,就会产生最稳定的生成器
- 样本:
- 为保证前提条件相同,每个epoch的B相同(batch划分相同)
- 生成器
- 优化
- 生成器:
- 目标:从参数化概率分布中最大化样本的给定函数的期望。(类似一步强化学习)
- 训练:策略梯度策略
- 类比到强化学习中
- :状态
- :策略
- 奖励:(两个角度来定义)
- 从对抗训练角度,希望判别器判别生成器生成的为1(但对判别器来说,标注为0)
- ,b1:可以减小方差
- 来自
的预测概率的平均值
-
:参与判别器的预训练过程,但不参与对抗训练过程
- 当判别器的分类能力降低, 判别为0的准确率逐渐下降–> 增加了–>生成器更好
- 从对抗训练角度,希望判别器判别生成器生成的为1(但对判别器来说,标注为0)
- 梯度:
- 类比到强化学习中
- 生成器:

4.关系提取
数据集
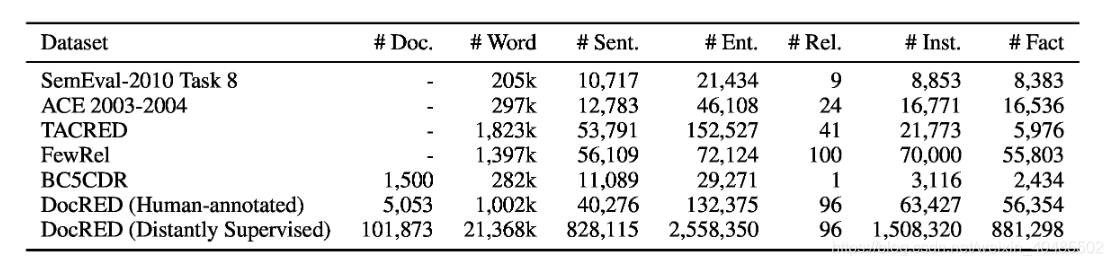
4.1 句子级
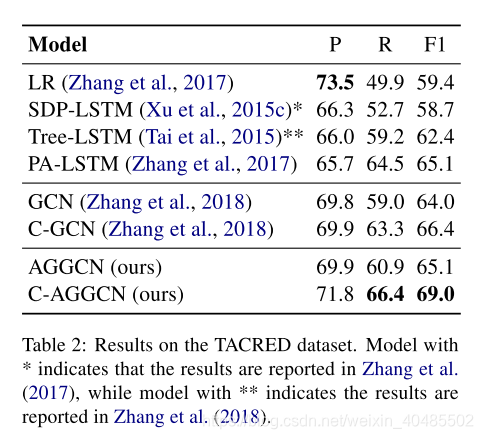
- TACRED数据集:(收费的-可能的购买链接?)
- 介绍
- TACRED数据集有超过106K个实例,它引入了41种关系类型和一种特殊的“无关系”类型来描述实例中提及对之间的关系。主题提及分为“个人”和“组织”两类,而对象提及分为16种细粒度类型,包括“日期”、“位置”等。
- 大型句子级提取任务
- 使用过它的model:
- AGGCNs
- (Zhang et al., 2018)
- 介绍
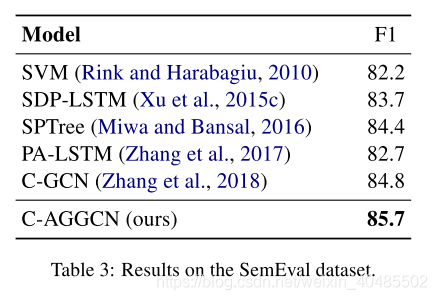
- Semeval-10 Task 8
- 句子级提取任务
- 介绍
- 它包含10717个实例,包含9个关系和一个特殊的“other”类。
- 比TACRED小,仅为1/10
- 使用过它的model:
- AGGCNs
- (Hendrickx et al., 2010)
4.2 文档级-句间关系提取
-
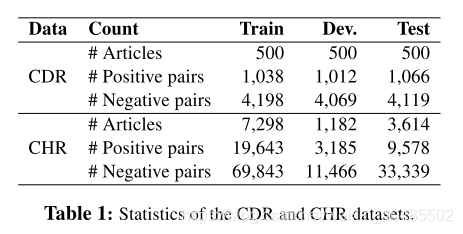
- CDR数据集是为BioCreative V challenge开发的文档级、句间关系提取数据集(Wei et al., 2015)。
- 应用于此的:
- Sahu, S. K., et al. (2019)
- 得分函数:bi-affine pairwise scoring to detect relations.
- model(对比)
- SVM (Xu et al., 2016b),
- ensemble of feature-based and neural-based models (Zhou et al., 2016a),
- CNN and Maximum Entropy (Gu et al., 2017),
- Piece-wise CNN (Li et al., 2018)
- Transformer (Verga et al., 2018)
- CNN-RE, a re-implementation from Kim (2014) and Zhou et al. (2016a)
- RNN-RE, a reimplementation from Sahu and Anand (2018).
- Sahu, S. K., et al. (2019)
-
CHR数据集(Sahu, S. K., et al. (2019).)
- 来自PubMed摘要和题目名
- 数据集由来自PubMed的12094篇摘要及其标题组成。化学品的注释是使用语义分面搜索引擎Thalia的后端执行的。化合物是从注释实体中选择的,并与图形数据库Biochem4j保持一致,Biochem4j是一个免费可用的数据库,集成了UniProt、KEGG和NCBI分类法等多种资源。如果在Biochem4j中识别出两个相关的化学实体,则它们将被视为数据集中的阳性实例,否则将被视为阴性实例。总的来说,语料库包含超过100,000个注释的化学物质和30,000个反应。
-
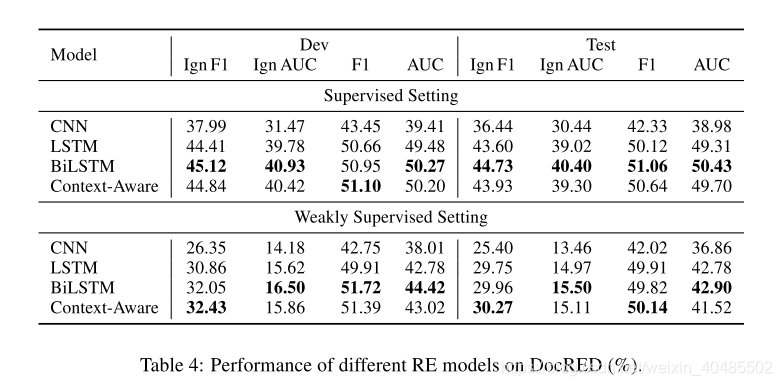
DocRED
- 基线+docRED数据集
- 介绍
- 用于:大规模文档集句间关系提取
- 来源:wikipedia和wikidata
- 特征:
- 标记实体和关系,文档集最大的人类标注纯文本数据集
- 要求从多个句子中提取实体并推断关系
- 提供大规模远程监督数据,使之可用于监督和弱监督情景
4.3 n-ary关系
- PubMed (Peng et al., 2017)
- n元关系
- 包含从PubMed中提取的6,987个三元关系实例和6,087个二元关系实例。
- 介绍
- 大多数实例包含多个句子,每个实例都被分配了以下五种标签中的一种,包括抵抗或不响应、灵敏度、响应、抵抗和无。我们考虑两个具体的评价任务,即:二类n元关系提取和多类n元关系提取。对于二元n元关系提取,(Peng et al., 2017)将四个关系类分组为yes,将none处理为no来对多类标签进行二值化。
- model
- AGGCNs
- (Peng et al., 2017)
4.4 层次关系
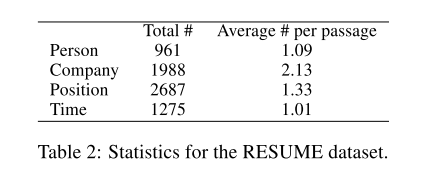
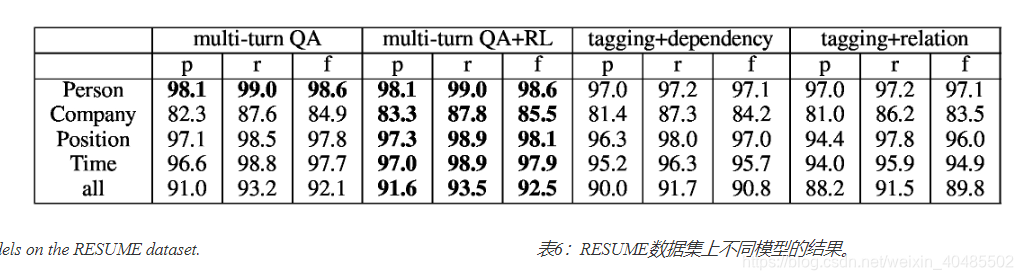
- RESUME的新数据集。
- 我们从IPO招股说明书中描述管理团队的章节中提取了841段。
- 每个段落都描述了一位高管的一些工作经历。
- 我们希望从简历中提取结构数据。
- 四种类型的实体:
- 人(行政人员的姓名),
- 公司(行政人员工作/工作的公司),
- 职位(他/她持有/持有的职位)和
- 时间(执行的时间段)占据/占据那个位置)。
- 值得注意的是,一个人可以在不同的时间段内为不同的公司工作,并且一个人可以在不同的时间段内为同一公司担任不同的职位。
4.5 其他
- 数据集
- Reidel dataset(Riedel et al。,2010)
- Freebase的三元组+NYT的句子
- Reidel dataset(Riedel et al。,2010)
- NYT
- NYT2
- 用于
- 传统信息抽取
- 开放信息抽取
- 远程监督
- 介绍https://pan.baidu.com/s/1Mu46NOtrrJhqN68s9WfLKg
- NYT数据集是关于远程监督关系抽取任务的广泛使用的数据集。该数据集是通过将freebase中的关系与纽约时报(NYT)语料库对齐而生成的。纽约时报New York Times数据集包含150篇来自纽约时报的商业文章。抓取了从2009年11月到2010年1月纽约时报网站上的所有文章。在句子拆分和标记化之后,使用斯坦福NER标记器(URL:http://nlp.stanford.edu/ner/index.shtml)来标识PER和ORG从每个句子中的命名实体。对于包含多个标记的命名实体,我们将它们连接成单个标记。然后,我们将同一句子中出现的每一对(PER,ORG)实体作为单个候选关系实例,PER实体被视为ARG-1,ORG实体被视为ARG-2。
- 数据集有53个关系,包括N A关系,表示实例关系不可用。
- 训练集有522611个句子,281270个实体对和18252个关系事实。在测试集中,有172448个句子,96678个实体对和1950个关系事实。
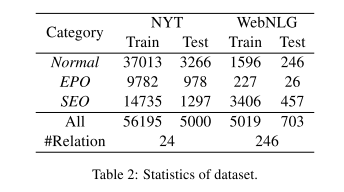
- GraphRel用
- (Lin等人,2016; Liu等人,2017; Wu等人,2017; Feng) et al。,2018)。
- Zhang, N., et al. (2019)
- DISTRE
- WebNLG
- python
-
- GraphRel用
- GraphRel用
- ACE04定义了7种实体类型,包括人员(PER),组织(ORG),地理实体(GPE),位置(loc),设施(FAC),武器(WEA)和车辆(VEH)。
- 对于每对实体,它定义了7个关系类别,包括物理(PHYS),人 - 社会(PERSOC),就业 - 组织(EMP-ORG),代理 - 工件(ART),PER / ORG Affliation(OTHER-AFF) ,GPE- Affliation(GPE-AFF)和话语(DISC)。
- ACE05建立在ACE04之上。
- 它保留了ACE04的PER-SOC,ART和GPE-AFF类别,但将PHYS分为PHYS和新的关系类别PART-WHOLE。
- 它还删除了DISC,并将EMP-ORG和OTHER-AFF合并为一个新的EMP-ORG类别。
- 至于CoNLL04,
- 它定义了四种实体类型(LOC,ORG,PER和OTHERS)和
- 五种关系类别(LOCATED IN,WORK FOR,ORGBASED IN,LIVE IN)和KILL)。
- 对于ACE04和ACE05,我们遵循Li和Ji(2014)以及Miwa和Bansal(2016)4中的培训/开发/测试分组。
- ecml数据集–Freebase与NYT对齐
- 远程监督
- Distant Supervision for Relation Extraction with Sentence-Level Attention and Entity Descriptions
4.6中文
- 中文的数据集
- Chinese SanWen (Xu et al., 2017), code的data
- 包含837篇中国文献文章中的9种关系类型,其中695篇文章用于培训,84篇用于测试,其余58篇用于验证。ACE 2005数据集是从新闻专线,广播和网络日志中收集的,包含8023个关系事实和18个关系子类型。我们随机选择75%来训练模型,剩下的用于评估。
- ACE 2005 Chinese corpus (LDC2006T06)
- FinRE.
- 为了在测试域中实现更多样化,我们在新浪财经2中手动注释来自2647个财务新闻的FinRE数据集,分别用13486,3727和1489个关系实例进行培训,测试和验证。FinRE包含44个不同的关系,包括特殊关系NA,表示标记的实体对之间没有关系。
- Chinese SanWen (Xu et al., 2017), code的data
4.7 时间关系(事件的)
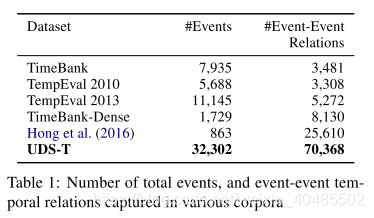
- TEMPROB
- 引入动词之间的前后关系(时间顺序
- 引入这类常识的先验知识
- EventCausality
- 可以转化为时间关系的(因果->时间
- 时间关系数据集
- 大多基于TimeML标准的
- TimeBank
- 是使用此标准构建的最早的大型语料库之一,
- 旨在捕获事件之间的“显着”时间关系(Pustejovsky等,2003)
- 稀疏
- TemEval比赛(有数据集
- covering relations between all the events and times in a sentence.
- 基于TimeBank
- TimeBank-Dense
- 这种稀疏性已通过语料库解决
- 其中注释器标记了所有本地边缘,而无歧义(Cassidy等,2014)。
- TimeBank-Dense不会捕获事件和时间关系上的完整图形,
- 而是试图通过捕获一个句子内以及相邻句子之间的所有关系来实现完整性。
- <—本文的灵感
- Hong et al. (2016) build a cross-document event corpus
- 涵盖了细粒度的事件-事件关系和具有更多事件类型和子类型的角色
- (另见Fokkens等人,2013)。
- TimeBank
- UDS-T数据集(本文)
- 结果数据集-通用分解语义时间(UDS-T)-是迄今为止最大的时间关系数据集,
- 比基于TimeML标准的好
- 涵盖了所有的通用依赖性(Silveira等人,2014; De Marneffe等人,2014; Nivre等人,2015 )English Web Treebank(Bies等,2012)。
- UD-EWT的优点:
- (i)涵盖了各种流派的文本;
- (ii)它包含黄金标准的通用依赖性解析;
- (iii)它与使用相同谓词提取标准的各种其他语义注释兼容
- (White等人,2016; Zhang等人,2017; Rudinger等人,2018; Govindarajan等人,2019)。
- UD-EWT的优点:
- 大多基于TimeML标准的
5.各种model的效果
- 基于特征的model
- 对于不平衡的数据集:倾向于得到更高的precision,但recall低
- 神经model:
- 可以得到一个均衡的precision和recall
5.1 n-ary
5.1.1 PubMed (Peng et al., 2017)
- cross是句间
- single是句内
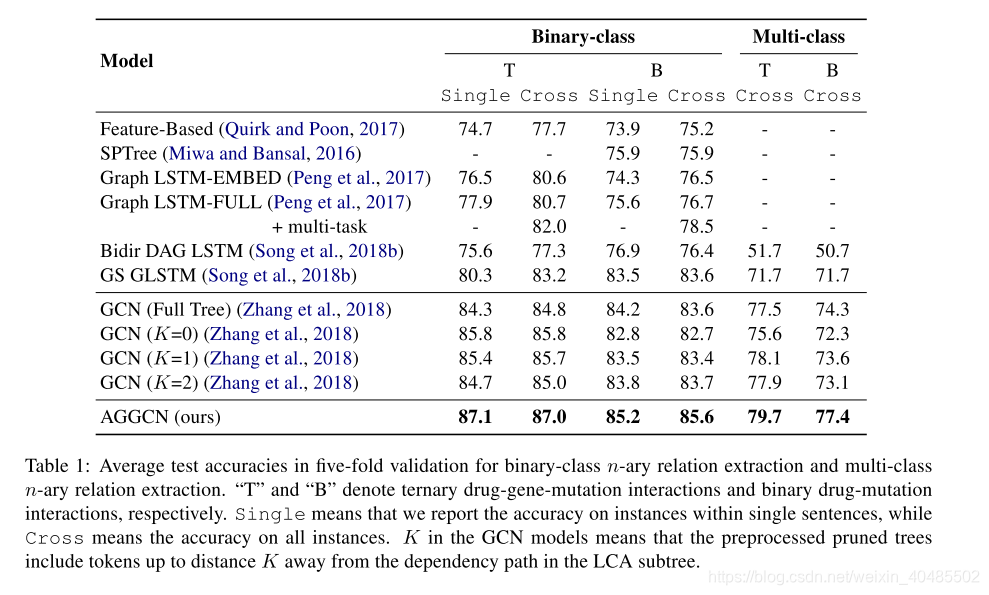
5.2 句子级别
5.2.1 TACRED
5.2.2 SemEval
5.3 文档级别(句子间)
5.3.1CDR
- CDR
- 得分函数:bi-affine pairwise scoring to detect relations.
- model
- SVM (Xu et al., 2016b),
- ensemble of feature-based and neural-based models (Zhou et al., 2016a),
- CNN and Maximum Entropy (Gu et al., 2017),
- Piece-wise CNN (Li et al., 2018)
- Transformer (Verga et al., 2018)
- CNN-RE, a re-implementation from Kim (2014) and Zhou et al. (2016a)
- RNN-RE, a reimplementation from Sahu and Anand (2018).
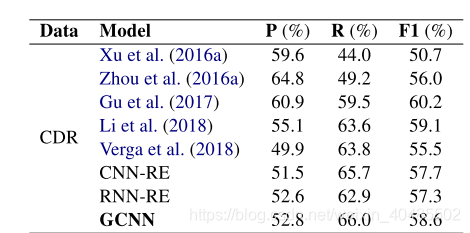
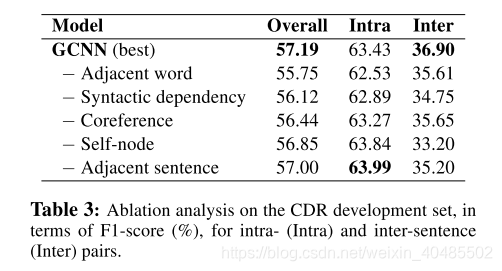
5.3.2 CHR
- CDR
- 得分函数:bi-affine pairwise scoring to detect relations.
- model
- SVM (Xu et al., 2016b),
- ensemble of feature-based and neural-based models (Zhou et al., 2016a),
- CNN and Maximum Entropy (Gu et al., 2017),
- Piece-wise CNN (Li et al., 2018)
- Transformer (Verga et al., 2018)
- CNN-RE, a re-implementation from Kim (2014) and Zhou et al. (2016a)
- RNN-RE, a reimplementation from Sahu and Anand (2018).
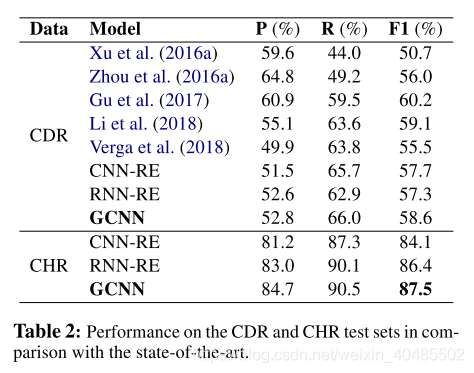
5.3.3 DocRED
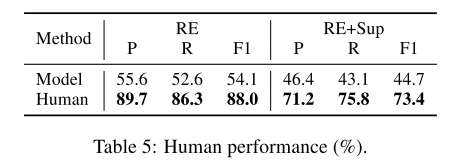
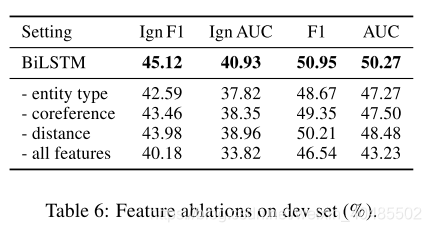
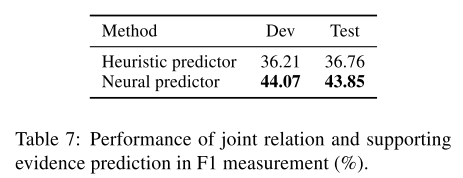
5.4层次关系
- RESUME
5.5其他
5.5.1 NYT
- APCNN+D(2017,远程监督)
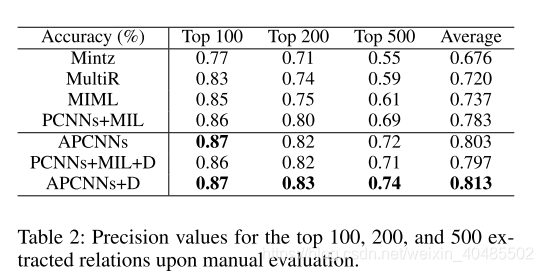
- GraphRel–用于重叠关系
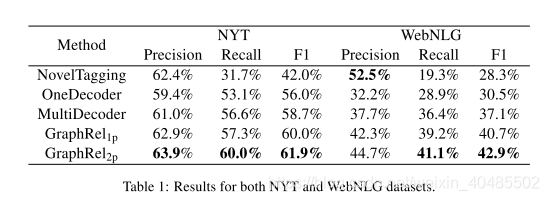
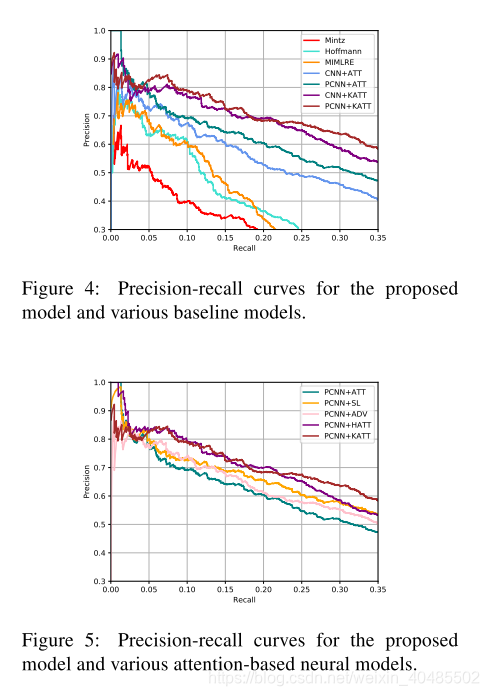
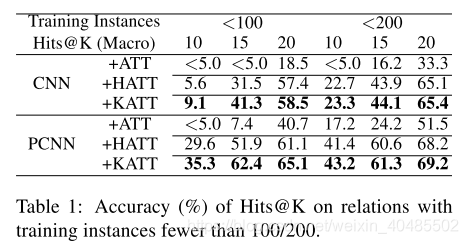
- PCNN/CNN+KATT–用于长尾关系
5.5.2 WebNLG
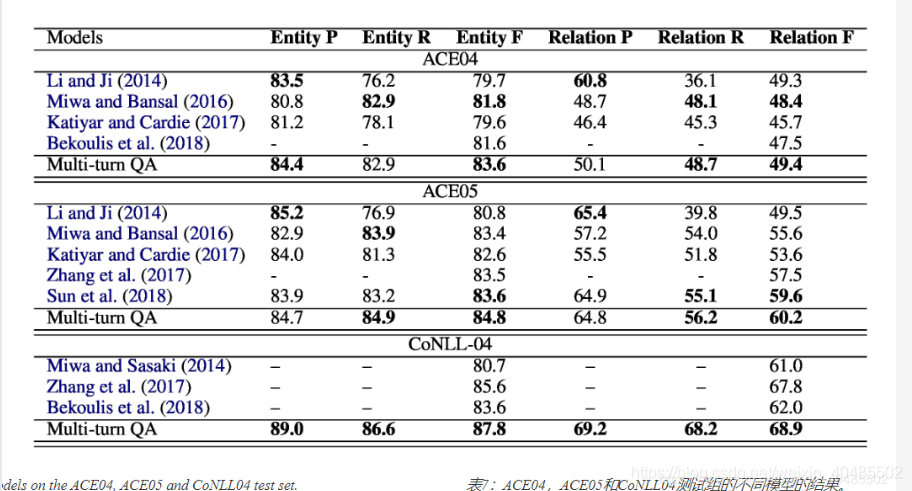
5.5.3 ACE
5.5.4 CoNLL-04

5.6中文
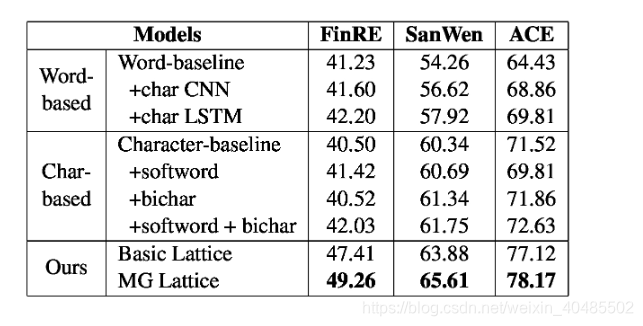
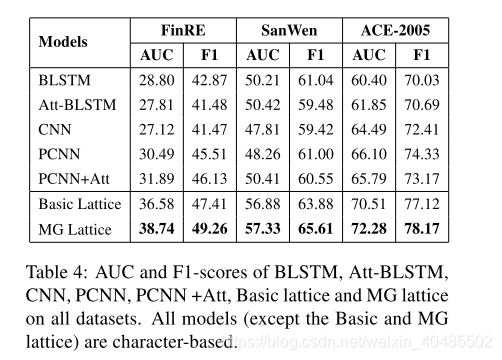
5.7时间关系
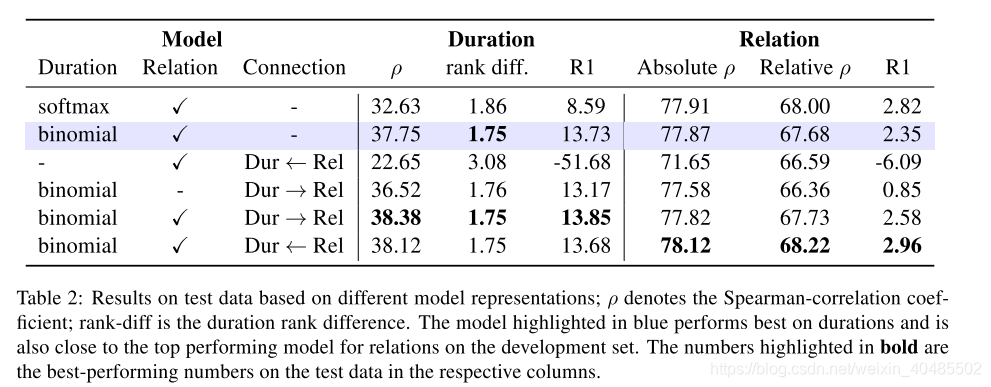
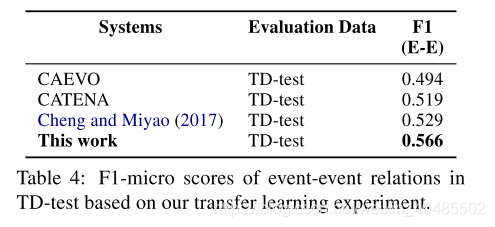
6.nlp工具
- 句子拆分:GENIA Splitter
- 句子标记:GENIA tagger (Tsuruoka et al., 2005)
- 词性标注+依赖树
- spaCy(Honnibal and Johnson, 2015)
- stanford词性标注
- 句法依赖:使用带有谓词-参数结构的Enju语法分析器(Miyao和Tsujii, 2008)获得了句法依赖关系。
- 指代消解:使用Stanford CoreNLP软件构建Coreference类型边缘(Manning et al., 2014)。
