1.简介
并发编程中,常用到线程安全队列。实现安全队列有两种方式,一种是阻塞算法,另一种是非阻塞算法。阻塞算法一般会使用阻塞锁来实现,非阻塞算法会使用自旋锁(CAS循环)来实现。
ConcurrentLinkedQueue是非阻塞线程安全队列,这是一个基于单向链表的无界队列,遵守先进先出的排序规则。队列的头节点是最先入队的元素,队列的尾节点是最后入队的元素。新元素插入到队列的尾部,在队列的头部弹出元素。与大多数其他并发集合实现一样,此类不允许使用null元素。 迭代器是弱一致性的,返回的元素只反映队列的某个时刻或创建迭代器后的状态。自创建迭代器以来,队列中包含的元素将仅返回一次。 注意,与大多数集合不同,执行size方法的时间开销不固定。由于这些队列的异步性质,确定当前元素数需要对元素进行遍历,因此,如果在遍历期间修改此集合,可能会得出不准确的结果。 内存一致性影响:与其他并发集合一样,在将添加元素的操作发生在访问或删除该元素之前。
2.组成
1)静态内部类Node
Node类定义链表的节点类型,一个Node对象代表一个链表节点。Node只有item 、next两个成员变量,它们均用volatile关键字修饰,保证了CAS操作时的可见性 。item表示当前节点储存的元素,next表示当前节点的后继节点(通过next属性将各节点链接在一起,形成单向链表)。
private static class Node<E> { volatile E item; volatile Node<E> next; Node(E item) { UNSAFE.putObject(this, itemOffset, item); } boolean casItem(E cmp, E val) { //cas更新节点中的元素 return UNSAFE.compareAndSwapObject(this, itemOffset, cmp, val); } void lazySetNext(Node<E> val) { //延迟化更新节点的后继节点(非阻塞写入,不保证立即可见,但性能较高) UNSAFE.putOrderedObject(this, nextOffset, val); } boolean casNext(Node<E> cmp, Node<E> val) { //更新节点的后继节点 return UNSAFE.compareAndSwapObject(this, nextOffset, cmp, val); } //...... }
2)成员变量
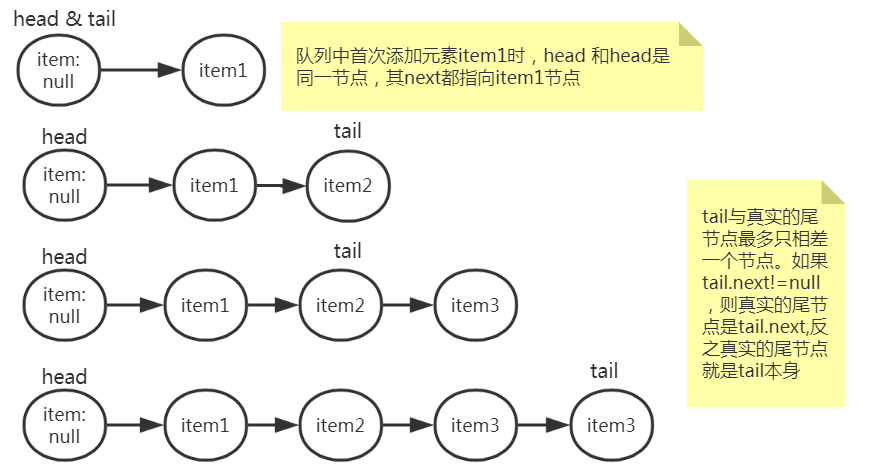
head表示链表的头节点,在某些情况下tail表示链表的头尾节点。因为HOPS的原因,尾节点的更新可能会延迟,tail就不一定是链表真实的尾节点,但通过tail可以快速的找到真实的尾节点。
head: 头节点,它是队列的第一个(未被删除)节点。head节点有这些特征:①所有活动的节点都能使用head.succ()方法获取到,②head节点总是非空的,③head.item可能是null也可能非null,④允许tail更新滞后于head,⑤head.next一定不会指向head.
tail:尾节点,当tail.next==null时,它是队列的最后一个节点(真实的尾节点)。head节点有这些特征:①真实的尾节点总是可以根据tail.succ()获取到,②tail始终是非空的,③tail.item可能是null也可能非null, ④允许tail更新滞后于head,⑤tail.next可能指向tail,也可能不指向tail.
3)构造方法
CLQ的两个构造方法都涉及成员变量 head 、tail的实例化,并且都将head和tail指向同一节点。也就是说CQL初始化后,其head和tail都指向同一非空节点。

public ConcurrentLinkedQueue() { head = tail = new Node<E>(null);//头尾节点指向同一节点 } public ConcurrentLinkedQueue(Collection<? extends E> c) { Node<E> h = null, t = null; for (E e : c) { checkNotNull(e); Node<E> newNode = new Node<E>(e); if (h == null) h = t = newNode;//初始化头尾节点,并将它们指向同一节点 else { t.lazySetNext(newNode); t = newNode; } } if (h == null) h = t = new Node<E>(null); head = h; tail = t; }
3.主要API
1)入队
入队新元素总是在队列的尾部添加元素,但tail节点并不总是尾节点,所以每次入队都必须先通过tail节点来找到尾节点。尾节点可能是tail节点,也可能是tail节点的next节点。只有当tail.next为空时,tail才表示真正的尾节点,否则tail.next表示真正的尾节点。
offer(E)方法的主要逻辑:
从tail节点开始向后遍历链表,先获尾节点tail的后继节点q,①若q为空,表明tail是真正的尾节点,CAS尝试将tail.next引用更新为入队节点newNode,要是CAS更新成功,方法即可返回。若此时若尾节点的更新滞后了两个节点,就尝试CAS更新tail的引用,tail更新允许失败。②p.next=p表明是p是队列中被删除的节点,重设p为head,重新自旋。③其他情况,重设p为其后继节点,即向后移动一个节点,准备进入下一次循环
public boolean offer(E e) { checkNotNull(e);//不能为null,否则抛出异常 final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t; ; ) { //t表示tail节点 Node<E> q = p.next; //p表示真实的尾节点,其初始值是tail(tail不一定是队列的尾节点) if (q == null) { //q为null,则p没有后继节点,p为队列的尾节点 if (p.casNext(null, newNode)) {//将入队列的结点newNode设为p的后继节点,若CAS入队成功,新尾节点就是newNode(此时成员变量tail还未更新) /** * 每次加入元素都要更新tail.next或tail引用,只会更新一方面,且tail引用更新允许失败。 * p等于t,表示p和t指向同一个节点,而t又是tail在当前线程的引用,即p等于tail * ”p.casNext(null, newNode)“方法相当于"tail.casNext(null, newNode)",这里已经隐式的更新了tail的next属性 * 当p==t为true时,上面if的条件判断语句就已经更新了tail的next属性,也就不需要调用casTail()去更新tail引用了 * 只有p!=t时才去更新tail的引用 */ if (p != t)//尾节点的引用更新滞后了两个节点,需要更新尾节点的引用(保证最多只滞后一个节点) /** * 将tail属性更新为入队的节点newNode,若CAS成功此时tail是真正的尾结点 * 允许cas失败,因为我们并不将tail当作队列的真正尾结点,也就是所谓的tail更新延迟. * 当前CAS失败,表示其他线程更新成功 * */ casTail(t, newNode); return true; } } else if (p == q) //p有后继节点(p不是队列的尾节点),且其next属性引用自指(p.next=p),这表明p是被删除的节点(主要是方法updateHead设置) //重新获取头节点 // 在这种情况下继续向后遍历队列后继节点永不为null,将造成在节点p上死循环遍历,必需要更新p的引用 /** * * "(t != (t = tail))“布尔表达式的结果,在单线程中始终为false,在多线程中若其他线程修改了tail的引用,此时为true. * 若tail引用已经其他线程被修改,就将p引用更新为t引用(t现在引用tail,即p引用tail,此时tail的next不会自指了), * 反之将p引用更新为head引用(跳到队列的头节点head,从头节点开始总能遍历到队列中的所有节点)。 * */ p = (t != (t = tail)) ? t : head; else//p有后继节点,p是正常节点,向后移动一个节点 //若其他线程修改了tail引用,就将p指向最新的tail,反之,将p指向其后继节点q(q是真实的尾节点) p = (p != t && t != (t = tail)) ? t : q; } }
2)出队
并不是每次出队时都更新head节点,当head节点里有元素时,直接弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点。这种做法的主要目的是减少使用CAS更新head节点的消耗,从而提高出队效率。

若某线程检测到node.next=node,则表明node是被移除的节点,需要重新获取头节点(得到当前真实的头节点)

poll()方法的主要逻辑:
首先获取头节点的元素,然后判断头节点元素是否为空,①如果为空,表示另外一个线程已经进行了一次出队操作将该节点的元素取走,如果不为空,则使用CAS的方式将头节点的引用设置成null,如果CAS成功,则直接返回头节点的元素 .如果不成功,表示另外 一个线程已经进行了一次出队操作更新了head节点,导致元素发生了变化,需要重新获取头节点。②第1步失败,获取p(p即是head节点)的后继节点q ,若后继节点q为空,表明队列为空,要更新头节点。③若p.next自指,p是被删除节点,重设p为head,重新自旋。④其他情况则重设p,向后移动一个节点,准备进入下一次循环
public E poll() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { E item = p.item; //p的元素值非空且cas更新成功,返回这个元素值。 if (item != null && p.casItem(item, null)) { //CAS更新成功 // Successful CAS is the linearization point // for item to be removed from this queue. if (p != h) // hop two nodes at a time 头节点的更新滞后了两个节点 updateHead(h, ((q = p.next) != null) ? q : p);//更新头节点 return item; } //头节点元素为空或头节点发生变化了,表明头节点被其他线程修改了。获取p的下个节点 else if ((q = p.next) == null) { //下个节点也为空,表明队列中没有元素了,队列空了 updateHead(h, p);//更新头节点,返回null return null; } else if (p == q) //p的next自指(p.next=p,p是被删除节点),重新获取头节点。 continue restartFromHead; else // p = q;//重设p,向后移动一个节点 } } }
出队方法体中有调用updateHead这个更新头节点的方法,我们可以看看它是如何做的。
其逻辑比较简单,就是先CAS更新头节点,将p设为新的头节点,然后将原头节点h的next属性自指(h.next=h)。这里的h节点是应该被删除的节点,当其他方法检测到节点的next属性自指,就能知道这是个被删除节点,遍历链表操作就会跳到head头节点。
final void updateHead(Node<E> h, Node<E> p) { if (h != p && casHead(h, p)) h.lazySetNext(h); }
3)移除特定的元素
remove()方法和其他的集合中移除元素的方法类似。从有效头节点开始遍历链表,查找指定元素值对应的节点,①若在当次循环中找到这节点,就先用CAS将节点的item设为null,再将找到的节点从链表中移除,若CAS更新节点的item成功就返回true. 若在当次循环中没找到这个节点或找到节点但CAS更新item失败,就让遍历位置向后移动一个节点,准备进入下一次循环,②若遍历到链表的尾部仍然无法移除元素,就返回false.
public boolean remove(Object o) { if (o != null) { Node<E> next, pred = null; for (Node<E> p = first(); p != null; pred = p, p = next) { boolean removed = false; E item = p.item; if (item != null) { //item 非空,表明这不是待删除节点 if (!o.equals(item)) { next = succ(p);//还没找到对应的节点,获取后继节点 continue;//进入下一次循环,继续向后遍历查找 } removed = p.casItem(item, null);//o.equals(item) 找到这个节点p,将此节点的item设为null } next = succ(p); if (pred != null && next != null) pred.casNext(p, next);//将p的前驱、后继节点直接链接起来,p自身就被移除出链表了 if (removed) return true; //CAS更新将item成功,移除元素成功 } } return false; }
4)获取元素个数
size()方法就是在链表上从前往后遍历元素,一次循环将count计数加1 。
public int size() { int count = 0; for (Node<E> p = first(); p != null; p = succ(p)) if (p.item != null)//p.item为空,表示被删除的节点 // Collection.size() spec says to max out if (++count == Integer.MAX_VALUE) break; return count; }
这里遍历链表并不是从head为开始至tail结束,因为head和tail都不是真正意义上的头尾节点。
first()方法用于返回队列中第一个有效(未被删除)节点。
Node<E> first() { restartFromHead: for (;;) { for (Node<E> h = head, p = h, q;;) { boolean hasItem = (p.item != null); if (hasItem || (q = p.next) == null) { //节点待删除或队列中无任何元素时 updateHead(h, p);//尝试更新头节点head return hasItem ? p : null; } else if (p == q)//p的next属性自指,表示被删除节点,重新获取头节点 continue restartFromHead; else p = q;//重设p,遍历位置后移一个节点 } } }
succ()方法用来返回一个节点的有效后继节点,当p.next自指时返回head,其他情况直接返回p.next 。
p.next=p表明是其他线程已将p节点(p是头节点)移除出队列,但当前线程又刚好遍历到节点p,所以其有效后继节点是最新的头节点head.
final Node<E> succ(Node<E> p) { Node<E> next = p.next; return (p == next) ? head : next; }