urllib库:
1:urllib库是Python中一个最基本的网络请求库,可以模拟浏览器的行为向指定的服务器发送一个请求,并保存服务器的数据
urllib是python自带的标准库,无需安装,直接使用

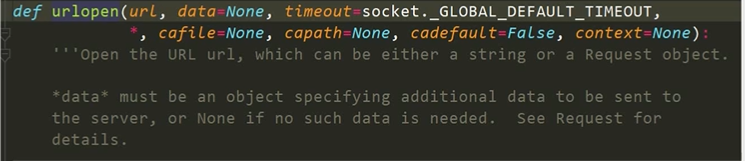
urlopen函数: 在Python3的urllib库中,所有的网络请求相关的方法,都会被集成到urllib.request模块下面了,看一些urlopen函数的基本使用:

urlopen函数详解
创建一个表示远程的url的类文件对象,然后像本地一样操作这个类文件对象来获取远程数据
url:请求的url
data:请求的data,如果设置了这个值,那么将变成post请求.
返回值:返回值是一个http.client.HTTPResponse对象,这个对象是一个类文件句柄对象.如果有read(size), readline readline以及getcode等方法
urlretrieve函数:
这个函数可以方便的将网页上的一个文件保存到本地.以下代码可以非常方便的将百度的首页下载到本地
代码如下:
from urllib import request
r = request.urlretrieve('http://www.baidu.com/','baidu.html')
urlencode函数
urlencode可以把字典数据转换为url编码的数据
from urllib import parse
# 定义一个字典类型的数据
data = {'name': '光头强', 'age': '18'}
# 通过pares.ulrencode的方法来进行转换数据
qs = parse.urlencode(data)
print(qs)
***
#返回的结果是十六进制的名字
name=%E5%85%89%E5%A4%B4%E5%BC%BA&age=18
from urllib import request, parse
# 创建一个字典类型的数据
data = {'word': '古天乐'}
# 通过parse.urlencode方法来实现字符串拼接
result = parse.urlencode(data)
# 使用.format方法
url = 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&{result}'
# 获取网页的源代码
html = request.urlopen(url)
# 打印网页的源代码,并设置他的一个编码格式为utf*8
print(html.read().decode('utf-8'))
***
#返回结果为网页源代码
parse_qs函数
可以将经过编码的url参数进行解码
data = {'name': '古天乐', 'age': 18}
result = parse.urlencode(data) # 将data中的数据进行解码
print(result) # 返回的结果是一个进行编码后结果
####
name=%E5%8F%A4%E5%A4%A9%E4%B9%90&age=18
result_list = parse.parse_qs(result) # 返回的结果是一个进行编码后在进行解码的结果
print(result_list) # 返回的是一个字典类型
###
{'name': ['古天乐'], 'age': ['18']}
urlparse函数和urlsplit函数
有时候拿到一个url,想到对这个url中的各个组成部分进行分割,那么这个时候就可以使用urlparse或者是urlsplit来进行分割
urlparse 和urlsplit基本上是一模一样的的
唯一不一样的地方是:urlparse里面有params属性,而urlsplit没有params属性
from urllib import parse
url = 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%8F%A4%E5%A4%A9%E4%B9%90'
result = parse.urlparse(url)
print(result) # 对URL中的数据进行分割,对各各部分组成的数据进行分割
result_list = parse.urlsplit(url)
print(result_list) # 也是对URL的数据进行分割,唯一不一样的是urlsplit少了params属性的内容
#####
ParseResult(scheme='http', netloc='image.baidu.com', path='/search/index', params='', query='tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%8F%A4%E5%A4%A9%E4%B9%90', fragment='')
SplitResult(scheme='http', netloc='image.baidu.com', path='/search/index', query='tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%8F%A4%E5%A4%A9%E4%B9%90', fragment='')
from urllib import parse
url = 'http://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%8F%A4%E5%A4%A9%E4%B9%90'
result = parse.urlparse(url)
print(result)# 对URL中的数据进行分割,对各各部分组成的数据进行分割
data = result.query
data_list = parse.parse_qs(data) #将经过编码后的文件进行解码
print(data_list)
####
ParseResult(scheme='http', netloc='image.baidu.com', path='/search/index', params='', query='tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&word=%E5%8F%A4%E5%A4%A9%E4%B9%90', fragment='')
{'tn': ['baiduimage'], 'ps': ['1'], 'ct': ['201326592'], 'lm': ['-1'], 'cl': ['2'], 'nc': ['1'], 'ie': ['utf-8'], 'word': ['古天乐']}
request.Requests函数
当我们想设置请求头的时候,我们需要使用到
requests.Requests:如果我们想要在请求的时候增加一些请求头,那么就必须使用request.Requests类来实现,比如要增加一个Users-Agent
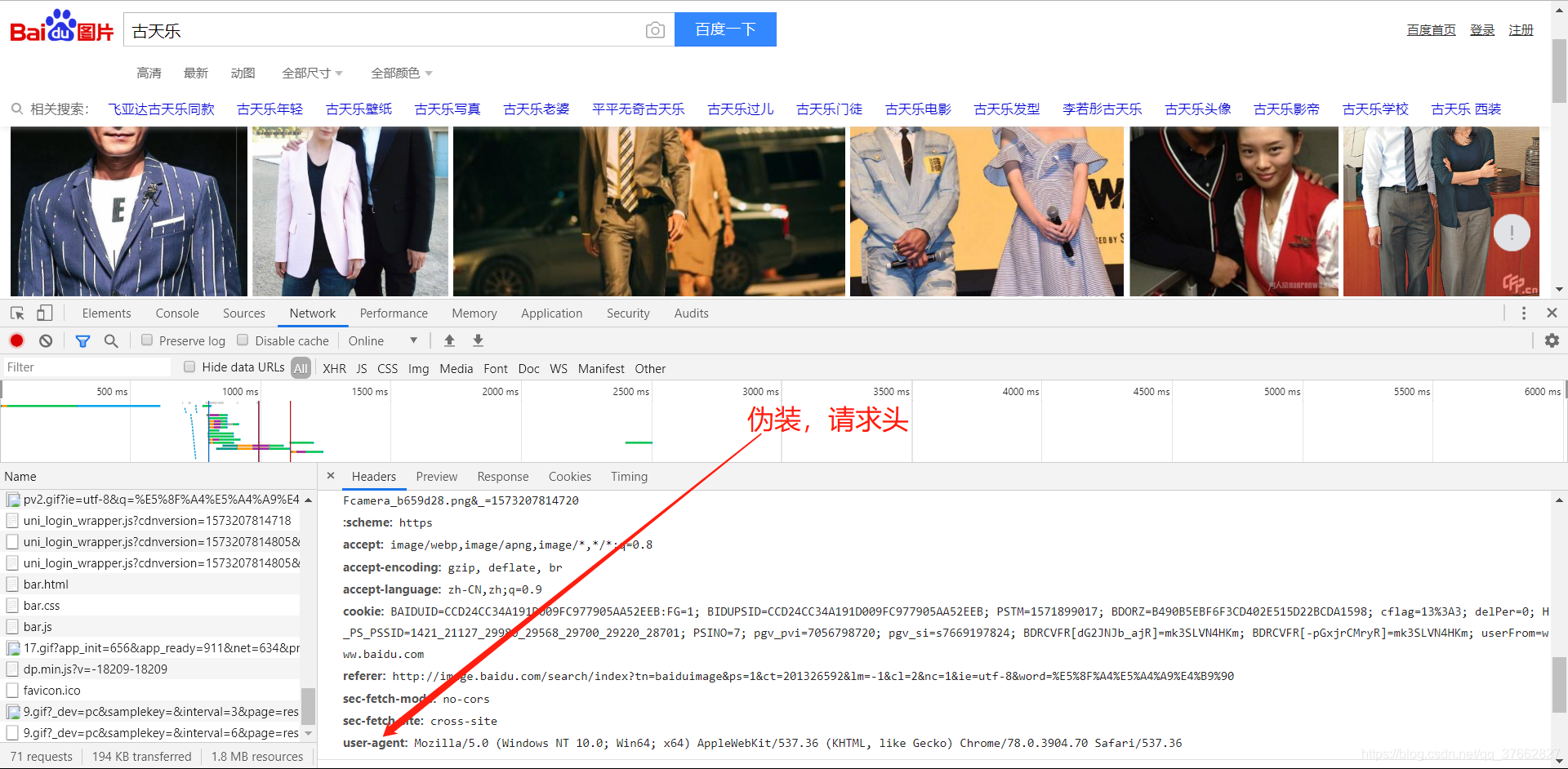
from urllib import request,parse
url = 'https://maoyan.com/'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',
'Referer': 'https://maoyan.com/'
}
result = request.Request(url,headers=headers)
html = request.urlopen(result)
print(html.read().decode('utf-8'))
