一、结构
由于输入与输出长度很多时候是不等长的,先回顾一下Seq2Seq的结构
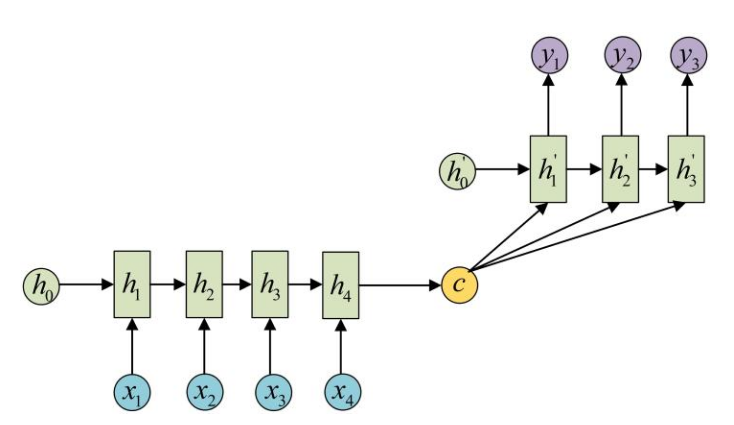
这种结构在负担集中在c身上,在句子较长时比较不好。例如在机器翻译中,考虑到每个输出的词,都跟所有输入的词有关,但有的关系大,有的关系小,于是有下面的结构:
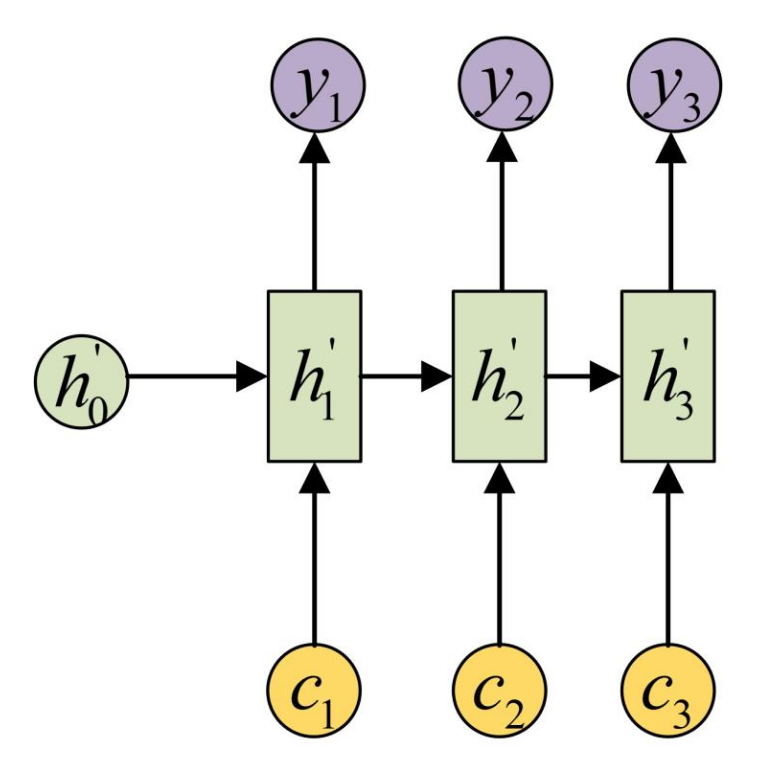

合起来的总结构就是:

二、为什么不直接对输入x使用attention机制?
注意到,上文求c的过程,描述并不完全准确。实际上h2、h3、h4包含的并不只有对应词的信息,也包含的有前面词的信息,因为它们是RNN的隐藏状态。所以,Attention机制其实是用在了h隐藏状态上,那为什么不直接应用在输入x上呢?
如果直接应用在输入的x上,那输入句子的RNN结构就没有了,那么输入句子的词序关系就学不到了。注意到Attention机制只是加权求和,并不包括各个变量的顺序关系。
虽然在输出阶段,依然使用了RNN结构,但是输出句子的词序关系,与输入句子的词序关系是不同的,例如中文翻译成英文,语法语序是不同的。所以Attention机制和RNN结构结合起来