一、前言
目前,除了windows以外最为流行的操作系统便是基于LinUx的操作系统。对于操作系统这门课程的初学者Linux具有一些独特的优势:
- Linux是一个免费的性能优秀的操作系统。
- Linux性能优秀而其源代码公开,使得不同领域和不同层次的用户可以根据自己的应用需求对Linux内核进行裁减。
- 可靠性高,稳定性好,移植性好。同目前流行的操作系统相比,Linux是非常稳定和可靠的,这一点已经得到很多用户的肯定。
- 大量的辅助说明文档。
本文 基于linux2.6.23,对进程的组织、状态的转换以及调度算法CFS(Completely Fair Scheduler 完全公平调度)进行学习分析。
二、进程的组织
Linux 内核使用 task_struct 数据结构来关联所有与进程有关的数据和结构,Linux 内核所有涉及到进程和程序的所有算法都是围绕该数据结构建立的,是内核中最重要的数据结构之一。该数据结构在内核文件 include/linux/sched.h 中定义。
2.1进程的ID类型
要想了解内核如何来组织和管理进程ID,先要知道进程ID的类型:
- PID:这是 Linux 中在其命名空间中唯一标识进程而分配给它的一个号码,称做进程ID号,简称PID。在使用 fork 或 clone 系统调用时产生的进程均会由内核分配一个新的唯一的PID值。
- TGID:在一个进程中,如果以CLONE_THREAD标志来调用clone建立的进程就是该进程的一个线程,它们处于一个线程组,该线程组的ID叫做TGID。处于相同的线程组中的所有进程都有相同的TGID;线程组组长的TGID与其PID相同;一个进程没有使用线程,则其TGID与PID也相同。
- PGID:另外,独立的进程可以组成进程组(使用setpgrp系统调用),进程组可以简化向所有组内进程发送信号的操作,例如用管道连接的进程处在同一进程组内。进程组ID叫做PGID,进程组内的所有进程都有相同的PGID,等于该组组长的PID。
- SID:几个进程组可以合并成一个会话组(使用setsid系统调用),可以用于终端程序设计。会话组中所有进程都有相同的SID。
2.2进程ID的哈希表
在系统运行过程中,可能会有成百上千的进程在运行,这时候进程的查找效率就尤关重要,比如系统管理员使用kill 1024命令去终止PID=1024的进程,内核会从这个PID导出对应的进程描述符进行处理。内核为了提高查找效率,专门使用了4个哈希表PIDTYPE_PID、PIDTYPE_TGID、PIDTYPE_PGID、PIDTYPE_SID用于索引进程描述符。为什么要4个?这样我们就可以用pid、tgid、pgrp、session去找进程,4个哈希表说明如下:

在内核中,这四个哈希表一共占16个页框,也就是每个哈希表占4个页框,它们每个可以拥有2048个表项,内核会把把这四个哈希表的地址保存到pid_hash数组中。以pid的哈希表为例,怎么在2048个表项中保存32767个PID值,内核会对每个已经分配的PID值进行一个处理,得到的结果的数值就是对应的表项,处理结果相同的PID被串成一个链表,如下:
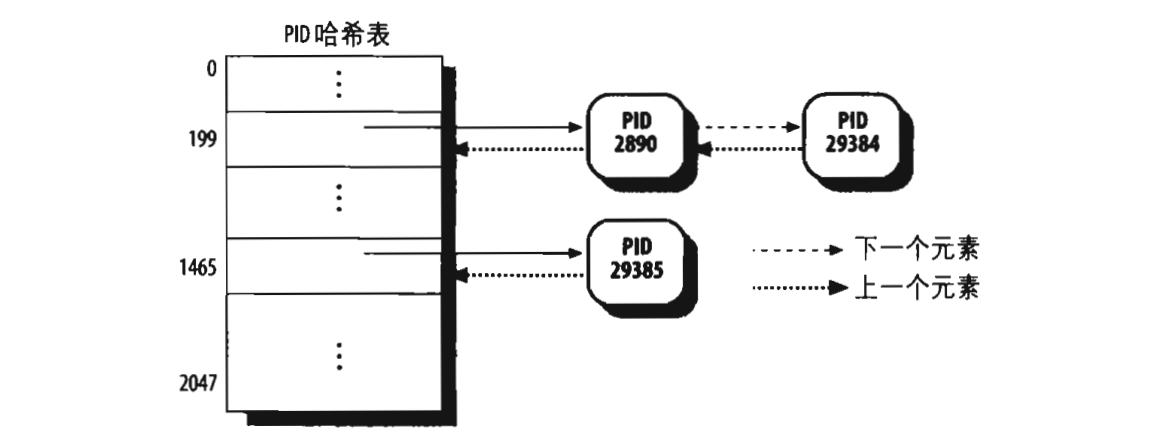
当使用kill 29384命令时,内核会根据29384处理得出199,然后以199为下标,获取PID哈希表中对应的链表头,并在此链表中找出PID=29384的进程。对于另外三个哈希表,同理。
三、进程状态的转换
3.1 Linux进程状态有:
TASK_RUNNING : 就绪态或者运行态,进程就绪可以运行,但是不一定正在占有CPU,对应进程状态的R
TASK_INTERRUPTIBLE:睡眠态,但是进程处于浅度睡眠,可以响应信号,一般是进程主动sleep进入的状态,对应进程状态S
TASK_UNINTERRUPTIBLE:睡眠态,深度睡眠,不响应信号,典型场景是进程获取信号量阻塞,对应进程状态D
TASK_ZOMBIE:僵尸态,进程已退出或者结束,但是父进程还不知道,没有回收时的状态,对应进程状态Z
TASK_STOPED:停止,调试状态,对应进程状态T
3.2进程间的转换关系,如下图所示:
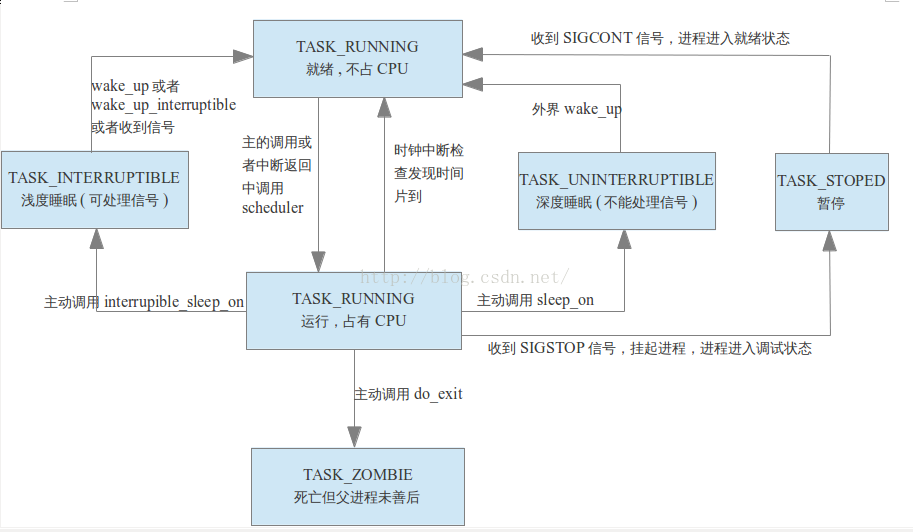
3.3 进程调度时机:
进程调度会引起进程状态转换,由上图可知如下情况会触发调度,进程终止或进程睡眠时主动exit或sleep释放CPU;浅度睡眠的进程被CFS调度选中唤醒,深度睡眠进程由于信号量,锁等的释放而被唤醒;进程收到信号量等;还有一种最常见的中断,异常。
四、进程的调度
4.1系统调度的概述
进程调度模块是Linux的关键子系统之一,由它决定系统将CPU等系统资源分配给哪个待处理的进程。如果说CPU是计算机的心脏,那么进程调度就是计算机的灵魂。调度的实质就是资源的分配,调度器的主要工作是如何使系统能够保持较短的响应时间和较高的吞吐量,如何在多个就绪进程中选取一个最值得运行的进程投入运行,而进程调度算法其实就是解决如何使资源分配策略最优化的关键。可见,调度器的好坏影响着05的整体性能,尤其是在(Real-time OPeration System)领域。
4.2Linux2.6.23进程调度模块的改进
由于Li~系统的开放性,Linux内核得到了持续不断的发展,在可靠性、可伸缩性和性能方面获得了长足的改进与优化,其调度系统也在一代又一代的新内核中得到更新,使系统整体性能有了很大的提升圆。目前,最新的Linux2.6.23对进程调度部分进行了较大的修改,新内核中调度器的主要特性包括三个方面:
(1)模块化的调度器接口。最新的Linux2.6.23内核中提供了进程调度器模块管理器,各种不同的调度算法都可以作为一个模块注册到该管理器中。不同的进程可以选择使用不同的调度模块。在Linux2.6.23内核中,进程调度模块实现了两个调度模块:cFS模块和实时调度模块,分别在kernel/sched_fair.c和kemel/sched_rt.c中实现。
(2)CFS调度器。CFS调度器试图按照对CPU时间的“最大需求”运行进程,这有助于确保每个进程可以获得对CPU的公平共享。
(3)CFSs组调度。组调度是为了使用户能公平的共享cPu。在新的Linux2.6进程调度模块中,实时进程调度较之前并没有做出大的改动,而为了实现一个全新的CFS(Completely Fair Scheduler)调度器,Linux2.6中与调度相关的内核部分有了较大的修改。本文主要分析和研究了Linux2.6.23内核进程调度中CFS调度器的相关理论。
4.3CFS调度器的基本原理
CFS是“Completely Fair Scheduler”的缩写,其在最新的Linux2.6.23内核版本中发布,按照作者IngoMolnar的说法:“CFS百分之八十的工作可以用一句话概括—CFS在真实的硬件上模拟了完全理想的多进程处理器”。首先,“公平”绝不意味着“相等”,也就是说在分配处理器资源时,不能简单地将系统内所有进程都一视同仁,而要区别对待。这是因为系统内的进程本身就不是平等的,例如许多内核线程是用来应付某种紧急情况的,它们理应比普通的用户空间进程更优越一些。其次,绝对公平也是不可能实现的,CFS所关注的是时间上相对长程的公平,在每个小的时间区间很可能看起来并不是公平的,引起这种现象的可能是需要对以往的不公平作补偿、系统的负载发生变化、实现方法限制等诸多原因,所以说CFS中的“C”和“F”其实都不是绝对的。
假设一个单处理器系统内有三个运行参数完全相同并且同等重要的进程,在理想的公平条件下,它们应该同时开始,同时完成,但恐怕只有在多维时间的条件下,这种处理器才可能制造出来。所以,必然会有进程的开始执行时间被延迟了,为了做到公平,它在占用处理器时也要将这部分时间找补回来。这样,依据什么指标选择要占用处理器的进程的问题就得到了解决—只需要选择等待处理器时间最长的进程那个就行了,即将要占用处理器时间最长的那个进程。在系统满负荷时,最大只能分配其指定配额。简单地按照进程数量分割显然与上面刚刚介绍的关于公平和相等的讨论相矛盾,某个处理器上各种进程的权重才是更好的指标,它可以包含各个进程权重(重要程度)不同的情形。显然,系统不是满负荷时,不想因为“配额”的原因让处理器空闲。例如:当处理器上有两个进程是纯计算进程(不休眠),且两者的权重相等,也就是公平的情况下,它们应该分别占有50%的处理器时间。如果其中一个进程早于另一个提前结束了,那么不希望剩下的那个进程还只能使用50%的处理器时间。实际上不仅仅在处理器调度上有这种要求,在分组交换网络等领域上也有类似需求,这类调度有一个名字:work一conserving调度,VirtualClock就是其中一种兼具实现容易和表现优异两种优点的方法。在这种方法里,除了实际的时钟,每个处理器所对应的运行队列还维护着一个虚拟时钟。它的前进步伐与该处理器上的进程权重成反比,也就是说当系统内有多个进程时,虚拟时钟的步调就按总权重大小成比例地慢下来,也即虚拟时间单元会按比例变长。例如:系统内有两个就绪进程,一个权值为1,另一个权值为2,这样虚拟时间单元就是3个实际时间单元。每个虚拟时间单元内这两个进程应该分别获得1/3和2/3的处理器时间。每个进程也都有自己的虚拟时钟,它们的前进步伐与自己的权重成反比。套用上面的例子,第一个进程的虚拟时钟单元与实际时间单元相同,为1;第二个进程的虚拟时钟单元为1/2。每个虚拟时间单元结束时,若进程得到公平待遇了,则它们的虚拟时钟与运行队列的虚拟时钟是相同的。否则,若进程的虚拟时钟慢于运行队列的,则说明该进程需要补偿了,反而就应该遏制该进程了。在最简单的情况下,通常选择具有最小虚拟时钟的进程就可以做到不错的公平了。由以上可知,运行队列上的虚拟时钟实际上就是判断公平与否的标尺,这就是CFS使用虚拟时钟的方针,这个时钟用cfsesrq结构中的fair--clock成员表示,在函数uPdat几curr()内维护着它的前进步伐。对于每个CPU上的调度实体,CFS使用按时间排序的红黑树来进行维护。该方法能够良好运行的原因在于:①红黑树可以始终保持平衡。②红黑树是二叉树,查找操作的时间复杂度为对数。但是除了最左侧查找以外,很难执行其他查找,并且最左侧的节点指针始终被缓存。③对于大多数操作,红黑树的执行时间为O(logn)。O(fogn)行为具有可测量的延迟,但是对于较大的进程数无关紧要。④红黑树可通过内部存储实现,不需使用外部分配即可对数据结构进行维护。下面将分析Linux2.6.23中CFS实现的关键部分,以深入理解CFS的工作原理。
4.3.1核心数据结构
1、改进后的struct task_struct
Linux2.6.23内核仍然用数据结构task_struct(在include/linux/sched.h中定义)来表示进程,尽管对线程进行了优化,但内核线程的表示仍然与进程相同。随着调度器的改进,task_struct的内容也有了改进,交互式进程优先支持、内核抢占支持等新特性,在task_struct中都有所体现。CFS去掉了优先级数组(struct prio_array),引入了调度实体(scheduling entity)和调度类(scheduling classes),分别由structsched--entity和structschedeeclass定义。因此,task--吕truct包含了关于sched_entity和sched_class这两种结构的信息,下面将对这两种结构进行重点分析。
(1)structsched---entity。该结构表示每个可以调度的对象,每个进程都对应一个调度实体,其包含了用于实现单个进程或进程组调度的完整信息,定义如下:

- 其中,wait_runiime表示调度实体在进入就绪队列之后等待处理器的时间;
- fair_key是调度实体插入红黑树的键值;
- load是当前实体的负载状况;
- run_node用来实现红黑树的链接;
- on_rq表示其是否在运行队列上;
- exe_start表示其开始执行的时间;
- sum_exec_runtime表示其执行的总时间;
- 另外还有一些相关的调度统计信息及组调度的相关信息。
(2)structsched。lass。该结构提供了Linux进程调度过程所必需的接口,其采用了面向对象的方法,是模块化调度器的核心数据结构。调度类通过链表将各个调度模块连接起来,新的调度模块只要实现了这些接口就可以加入到内核中。其数据结构定义如下:

- 其中,next用来链接调度模块;
- enqueu_task()是当进程进入运行态时调用,它将调度实体(进程)插入到红黑树中并将变量nr_running加1;
- dequeue一ask()是当某个进程退出可运行状态时调用,它将调度实体从红黑树中删除并将变量nr_running减1;
- yield_task()在compat_yield_sysctl关闭的情况下,执行调度实体先出队后入队,在这种情况下,它将调度实体放在红黑树的最右端;
- check_preempt_curr()检查当前进程是否可以被抢占,在实际抢占正在运行的进程之前,CFS调度程序模块将执行公平性测试,这将驱动唤醒式(wakeup)抢占;
- pick_next_task()选择最合适的进程以作为下一个运行的进程;
- put_prev_task()是将当前正在运行的进程让出CPU的使用权,如果current_task己执行完毕就会被从runqueue移除,否则重新放回runqueue等待下次调度;
- load_balance()是在多处理器中用到的负载均衡函数;
- set_curr_task()是当一个进程改变它的调度类或改变它的进程组时调用的;
- task_tick()通常调用time_tick()函数,它可能引起进程切换,这将驱动运行时(running)抢占;
- task_new():内核调度程序为调度模块提供了管理新进程启动的机会,CFS调度模块使用它进行组调度,而实时进程的调度则不会使用这个函数。
4.3.2红黑树算法研究
红黑树是一种平衡二叉查找树的变体,它的左右子树高差有可能大于1,所以红黑树不是严格意义上的平衡二叉树(AVL),但对之进行平衡的代价较低,其平均统计性能要强于AvL〔68j。红黑树的每个节点的属性除了有一个key和3个指针:p~t、Ichild、rchild外,还有一个属性:cofor:红或黑。与大多数二叉查找树一样,红黑树中较小的键值也是在左子树保存。红黑树除了具有二叉查找树的所有性质外,还具有以下5点性质:①节点是红色或黑色。②根是黑色。③所有叶子都是黑色(叶子是NIL节点)。④每个红色节点的两个子节点都是黑色(从每个叶子到根的所有路径上不能有两个连续的红色节点)。⑤从任一个节点到其每个叶子的所有路径都包含相同数目的黑色节点。因为红黑树是一种特化的二叉查找树,所以红黑树上的只读操作与普通二叉查找树相同。然而,在红黑树上进行插入和删除操作会导致其不再符合红黑树的性质,这就需要对相关节点进行一系列的调整以保持红黑树的性质。下面将分别给出红黑树节点的删除和插入算法。在红黑树的删除、插入算法中,要用到很多左旋(Left一Rotate)和右旋(形ght一Rotate)操作。所谓Left一Rotate(x)就是把节点
x向左下方向移动一格,然后让x原来的右子节点代替它的位置,而形ght一Rotate(y)就是Left一Rotate(x)的逆操作,其操作过程如图2一1所示(节点x、y可以出现于树中的任何位置,字母a、b和c表示任意子树):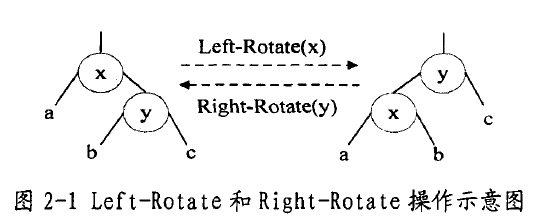
4.3.3算法时间复杂度证明
下面对红黑树节点插入和删除算法的时间复杂度进行证明。
证明:设h(v)一以节点v为根的子树的高度,bh(v) = 从v到子树中任何叶子的黑色节点的数目(不包括节点v),称为v的黑色高度。
若h(v)=0,则v必是NIL,即bh(v)=0。,可得2^(bh(v) )- 1=1-1=0。
归纳假设:h(v)=k的v有2^(bh(v) -1)- 1=1-1个内部节点,则h(v')=k+l的v'有2^(bh(v) )-1个内部节点。
因为h(v')>0所以它是个内部节点,同样它应有黑色高度是bh(v')或bh(v')-1(依据v'是红色还是黑色)的个儿子。
归纳假设每个儿子都有至少2^(bh(v')-1)-1个内部接点,则v‘’有2^(bh(v')-1)-1+2bh(v')-1+1=2(bh(v'))-1个内部节点。假设成立,这证明了以某一节点v为根的子树有至少2^(bh(v))-1个内部节点。
根据红黑树的性质,可知在从根到叶子的任何路径上至少有一半的节点是黑色,所以根的黑色高度至少是h(root)/2,故有n>=2^(h(root)/2)-1。
进一步可得b(root)<=2log(n+1),可见根的高度不大于2log(n+1)。己知在一棵高度为h的二叉查找树上的删除、插入等算法的时间复杂度时间为O(h),而包含n个节点的红黑树就是一种二叉查找树,所以红黑树节点插入和删除算法的时间复杂度不大于O(2log(n+1)),即为O(logn)。
4.3.4进程调度策略
Linux2.6.23内核中针对不同类型的进程提供了四种调度策略是SCHED_NORMAL、CHEDBAI_BATCH、SCHED_FIFO和SCHED_RR。
(1)SCHED_NORMAL。该策略是Linux2.6内核中是默认的分时调度策略,用于普通非实时进程的调度。其将所有进程都插入到一棵红黑树中,不断更新维护这棵红黑树,并且总是选择红黑树最左边的那个进程进行调度。
(2)SCHED_BATCH。该策略是Linux中独有的调度策略,主要用于计算密集型非实时进程的调度。其与SCHED_NORMAL很相似,不同之处在于SCHED_BATCH级的进程都被系统当作计算密集型的非实时进程,在调度时系统对此类型的进程有一些轻微的“惩罚”,因此这种调度策略比较适合响应时间要求较低的非交互进程。
(3)SCHED_FIFO。该策略遵守POSIX1.b标准的FIFO(先入先出)调度规则,用于实时进程的调度。在Linux2.6中,SCHED_FIFO级的进程会比任何SCHED_NORMAU/SCHED_BATCH级的进程都优先得到调度。一旦一个SCHED_FIFO级的进程处于可执行状态,就会一直执行,直到此进程主动释放CPU,或者CPU被另一个具有更高找少rt_priority的实时进程抢占。
(4)SCHED_RR。该策略遵守POSIX1.b标准的RR(循环round一robin)调度规则,用于实时进程的调度,每个进程依次地按时间片轮流执行。除了时间片有些不同外,这种策略与SCHED_FIFO类似。Linux2.6.23进程调度模块分为CFS算法模块和实时调度模块两部分:在CFS算法模块中,非实时进程以红黑树的方式排序,采用SCHED_NORMAL和SCHED_BATCH调度策略对非实时进程进行调度;在实时调度模块中,实时进程采用O(1)方式排序,采用sCHED_FIFO和SCHED_RR对实时进程进行调度。
4.3.5进程调度流程
Linux2.6.23进程调度的时机与以往相比并无多大变化,主要还是在时钟中断时进行检查。当时钟中断发生时系统会调用函数scheduler_tick(),该函数会根据当前进程所属的调度类调用其中断处理函数,对于CFS调度模块就是函数task_tick_fair(),而对于实时调度模块就是函数task_tick_rt()。其中,函数task_tick_fair()首先更新运行队列信息,然后检查该进程是否需要被抢占。检查过程是比较当前进程的实际运行时间与理想运行时间,如果实际运行时间超过理想运行时间则需要重新进行调度。这时会设置当前进程的TIF NEED RESCHED标志,在内核控制路径退出时会检查该标志,若该标志被设置则进行调度;函数task_tick_rt()首先判断进程的调度策略是否为SCHED_RD,若是则递减当前进程的时间片,如果时间片为0,则根据实时进程的优先级重新为当前进程分配时间片,若运行队列上不止一个进程,则将该进程放到队列尾部,并设置当前进程的TIF_NEED_RESCHED标志。
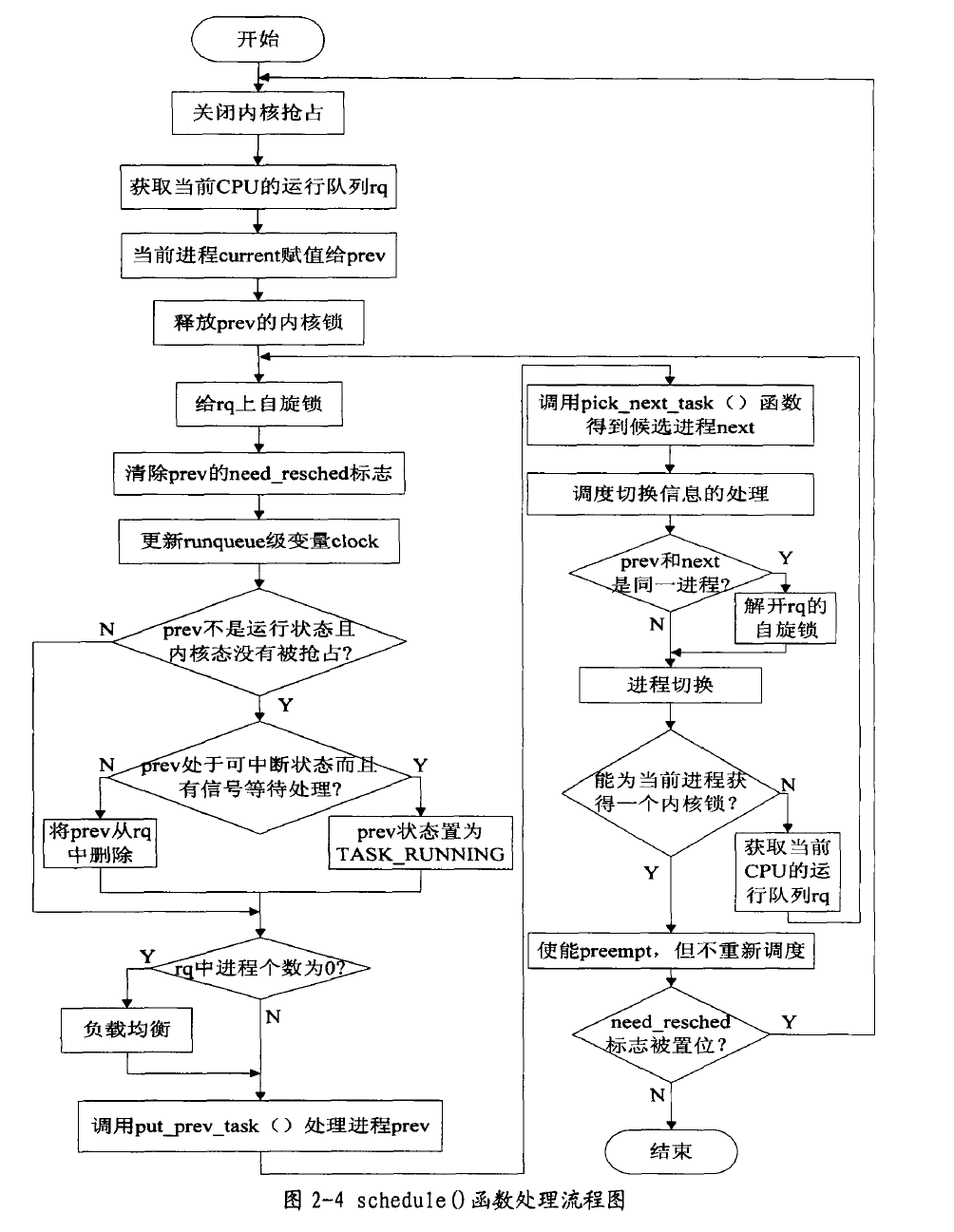
Linux2.6.23内核依然采用schedule()函数(在kemel/sched.c中实现)进行调度,其核心流程与之前并没有什么太大变化,所不同的是如何选择新进程。当前核心中系统会根据已经注册的调度类依次从运行队列中选择合适的进程,直到找到一个。这是通过调用sched_class中的函数pick_next_task()实现的,在CFS算法模块中该函数是Pick_next_task_fair(),它的实现相当简单,仅仅是从红黑树中提取其最左边的节点。在schedule()函数中有两个重要数据:prev和next。其中prev指向当前进程,也就是即将被切换出CPU的进程;next指向下一个进程,也就是即将被切换进CPU的进程。schedule()函数的主要处理流程如图2一4所示:
五、谈谈自己对该操作系统进程模型的看法
summary:
本文基于linux2.6.23,对进程的组织、状态的转换以及调度算法CFS(Completely Fair Scheduler 完全公平调度)进行了学习分析。介绍了进程调度模块在Linux2.6内核中的角色与地位,分析了最新的Linux2.6.23内核在进程调度方面的改进;其次从CFS调度算法所涉及的数据结构、红黑树算法以及算法复杂度、进程调度策略等方面深入剖析了CFS调度器在Linux2.6.23内核中的实现原理,最后分析总结了最新Linux2.6.23内核中进程调度模块的调度策略和调度流程。说到此处,想起在过去一年的时间里跟随老师学习了数字逻辑和计算机组成原理这两门课程,曾听过这样一个比如,通过学习数字逻辑可以学习到计算机的运算方式(与、并、非等),为后续学习计算机思想打下必要的基础,而通过学习并掌握计算机组成原理的知识可以了解计算机的思想,并设计出自己简单的cpu(请允许我将它称为微型操作系统),此时就像一个建筑师有了砌屋舍的能力,但并没有垒砌大厦的能力。而现在学习操作系统这门课程 和这次实验,真正的感受到了“摩天大楼”的宏伟壮阔,感叹程序员前辈鬼斧神工的同时,也深深体会到了自己的不足。但是,每一栋大楼毫无例外都是一砖一瓦垒起的,我想通过老师的指导和自己的不断学习,一定可以学好这门课程,为掌握建厦的能力打下更稳固的基础。
---恢复内容结束---