一、XQL/IQL
基于SparkSQL实现了一套即席查询服务,具有如下特性:
优雅的交互方式,支持多种数据源/接收器,多数据源混算
spark常驻服务,基于zookeeper的引擎自动发现
负载均衡,多个引擎随机执行
多会话模式实现并行查询
采用spark的FAIR调度,避免资源被大任务独占
基于spark的动态资源分配,在无任务的情况下不会占用执行者资源
支持集群和客户端模式启动
基于结构化流实现SQL动态添加流
类似SparkShell相互数据分析功能
高效的脚本管理,配合导入/包括语法完成各脚本的关联
对数据源操作的权限验证
XQL未开源,其架构及执行过程均由其文档得出。IQL可以看作XQL的一个简单实现版本。根据元数据信息加载各个数据源的数据到DataFrame、最后对通过spark sql对DataFrames进行联合查询操作。
github地址:https://github.com/teeyog/IQL
二、Moonbox

对SQL解析生成对各个数据源的查询计划、分别对各个数据源进行查询,得到对应的DataFrame、最后对DataFrames进行联合查询操作。
优点:
不维护元数据信息,则无元数据更新同步等问题
Github地址:https://github.com/edp963/moonbox
三、QuickSql
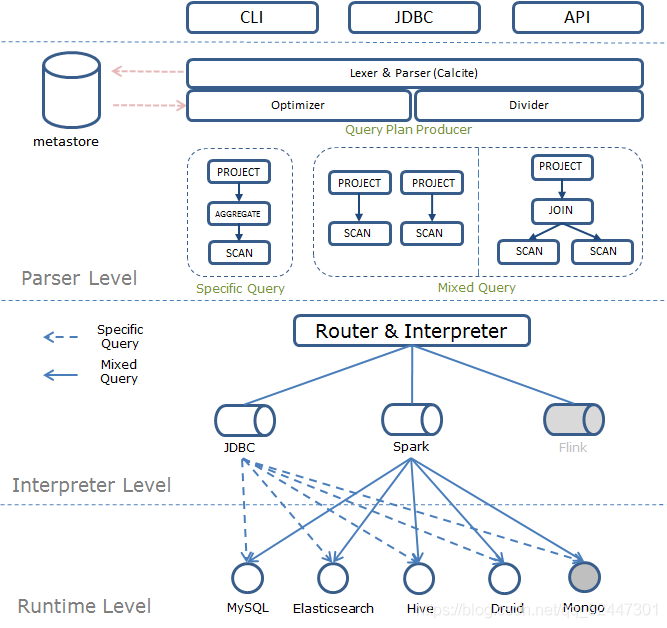
对用户输入的SQL通过Calcite进行解析优化、生成对各个数据源的查询计划、通过SparkCodeWrapper生成spark执行代码,提交到spark集群进行执行。代码中包括各个数据源的连接方式,查询语句等,查询出各个DataFrame、对DataFrames进行联合查询。
Github地址:https://github.com/Qihoo360/Quicksql
四、Druid
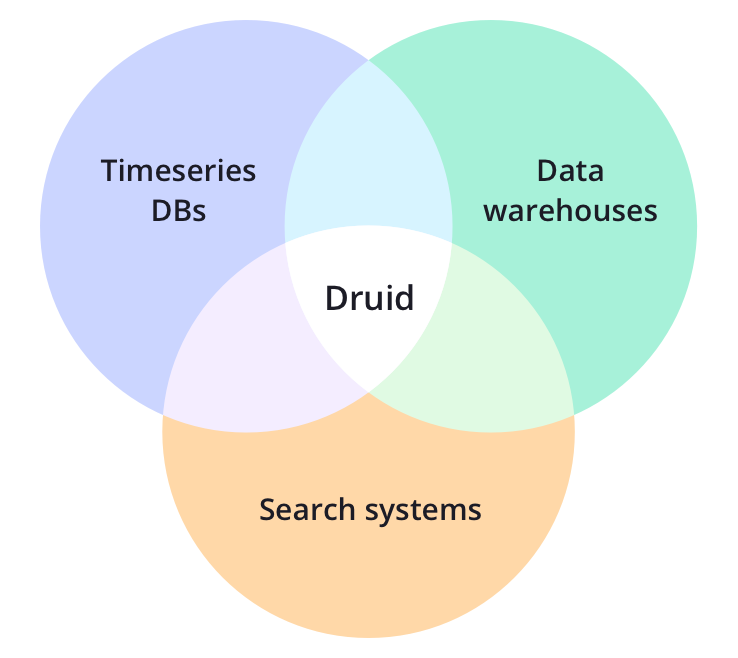
Apache Druid是一个开源的分布式数据存储。Druid的核心设计结合了数据仓库,时间序列数据库和搜索系统的思想,从而创建了一个统一的系统,可以对各种用例进行实时分析。Druid将这三个系统中的每个系统的关键特征合并到其接收层,存储格式,查询层和核心体系结构中。
Github地址:https://github.com/apache/druid/
五、mlsql
MLSQL语言是一个高效的面向大数据和机器学习的语言,脱胎于SQL,但又不止于SQL。MLSQL是一门标准的大数据/机器学习语言,MLSQL Engine则是执行该语言的分布式引擎。他们关系好比Java和JVM。
MLSQL Stack 则是一套解决方案,包含:
MLSQL Engine 如前所述,他是真实执行MLSQL的一个分布式引擎。
MLSQL Cluster 可以管理多个MLSQL Engine,主要功能目前是路由。
MLSQL Console 提供了一个Web控制台,可以理解为是编写MLSQL的一个IDE. 具备复杂的权限控制,脚本管理等。
MLSQL Store 提供了一些常见的功能模块,这包括脚本以及扩展Jar包,以及数据源依赖解决。
前三者为开源组件。
利用MLSQL Stack,可以轻易完成实现批处理,流式处理,机器学习,爬虫,API服务等多领域功能
Github地址:https://www.mlsql.tech/
六、SQLFlow
扩展SQL以支持AI。从数据中提取知识。当前支持MySQL,Apache Hive,阿里巴巴MaxCompute,XGBoost和TensorFlow。

官网:sqlflow
Github地址:https://sql-machine-learning.github.io/
七、最后常用的sql优化技巧:
1、列裁剪
2、投影消除
3、谓词下推
4、最大最小消除
5、常量传播
6、其他
