金字塔场景解析网络——PSPNet(解读)(原论文)
文中提出了金字塔池模块和金字塔场景解析网络(PSPNet),通过基于不同区域的上下文聚合来利用全局上下文信息的能力。全局先验表示有效地在场景解析任务中产生高质量的结果,而PSPNet为像素级预测提供了优越的框架。所提出的方法在PASCAL VOC 2012上获得了mIoU准确率85.4%的新记录,在Cityscapes上获得了80.2%的准确率。
文章贡献
- 基于FCN的像素预测框架,提出了一种结合困难场景上下文特征的金字塔场景解析网络。
- 基于深度监督损失为深度ResNet制定有效的优化策略。
- 为最先进的场景解析和语义分割构建了一个实用的系统。
FCN问题
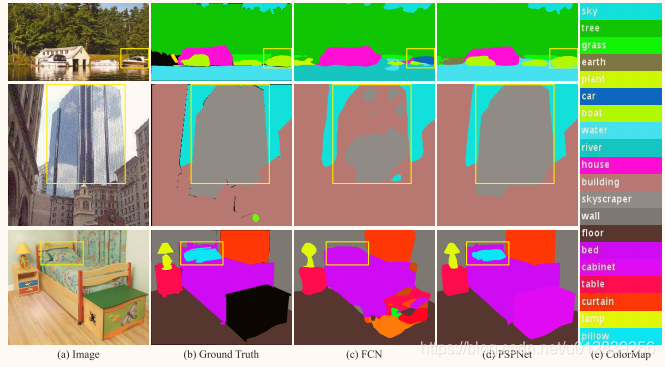
- 船看成车,缺乏收集上下文信息的能力增加了错误分类的可能性。
- 第二行图中,既是摩天大楼,又是建筑,应排除这些结果,以便整个对象既可以是摩天大楼,也可以是建筑物,但不能同时包含两者。 可以通过利用类别之间的关系来解决这个问题。
- 如图2的第三行所示,枕头具有与床单类似的外观。 俯瞰全球场景类别可能无法解析枕头。 为了提高非常小或大的对象的性能,应该注意包含不显眼类别的不同子区域。
总结这些观察结果,许多错误与不同感受领域的情境关系和全局信息部分相关或完全相关。
金字塔池化模块(PPModule)
金字塔池化模块是一种有效的全局上下文先验。
在深度神经网络中,感受野的大小可以大致指示我们使用上下文信息的程度。理论上 resnet 的接收场已经大于输入图像,但zhou等人表示(论文:Object detectors emerge in deep scene cnns),CNN的经验感受野远小于理论感受野,特别是高层。这使得许多网络没有充分融入重要的全部前景特征。提出了一种全局场景的金字塔池化模型。
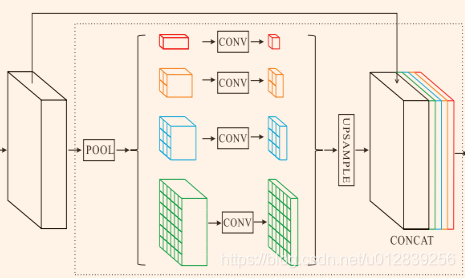
金字塔池模块融合了四种不同金字塔尺度下的功能。用红色突出显示的最粗糙级别是生成单个bin输出的全局池化。下面的金字塔级别将特征图分为不同的子区域,并为不同的位置形成集合表示(1×1、2×2、3×3和6×6)。金字塔池化模块中不同级别的输出包含不同大小的功能图。为了保持全局特征的权重,在每个金字塔层次后使用1×1卷积层,当金字塔层次大小为n时,将上下文表示的维数降到原来的维数的1/n,然后直接对低维特征图进行双线性插值,得到与原来特征图相同的维数特征。
PSPNet
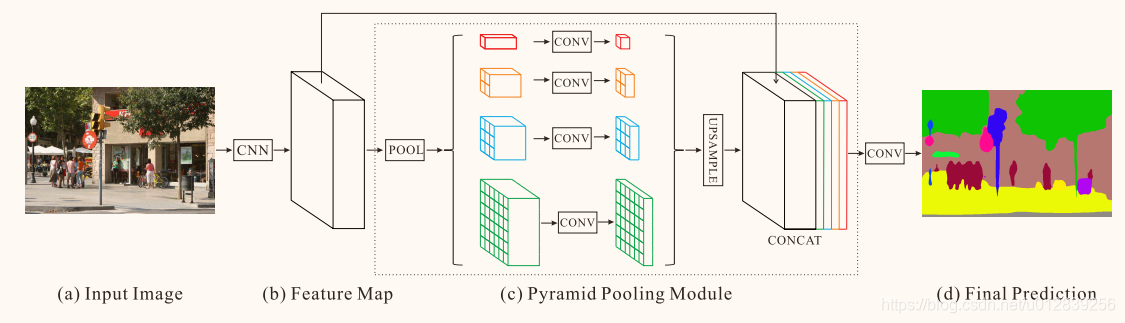
- 对于输入图像,使用一个带有扩展网络策略的预训练 resnet 模型来提取特征图。最终的特征图尺寸是输入图像的1/8。
- 使用4层金字塔池化模块来收集上下文信息。
- 将前面的特征图与金字塔池化模型生成的特征图连接CONCAT起来。
- 卷积生成最终预测图。
基于Resnet的FCN的深度监督
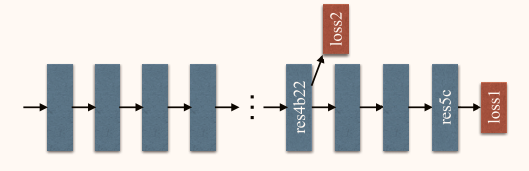
每个蓝色框表示一个残差块。在res4b22残差块后增加辅助损失。辅助损失有助于优化学习过程,而主分支损失承担的责任最大。我们增加权重以平衡辅助损失。
