——自写程序统计自己的CSDN博客访问量
我的个人主页
首先解析一下我的个人主页
-
要获得全部博客,页码
进入个人主页之后显示的我的博客第1页,如果只分析一页的,只需传入这个网址就行了,要分析另外几页呢,要每次自己修改网址么,我不想那么干
看一下第2页的网址
https://blog.csdn.net/BBJG_001/article/list/2第3页的
https://blog.csdn.net/BBJG_001/article/list/3虽然第1页的网址默认是https://blog.csdn.net/BBJG_001,但是当我这样写时
https://blog.csdn.net/BBJG_001/article/list/1响应的网页也确实是第1页,那么我就发现了规律,这些页数只是最后的数字不同罢了,那么我可以这么写了
baseurl = 'https://blog.csdn.net/BBJG_001/article/list/' for i in range(1, lastpage): currenturl = baseurl + str(i) res = requests.get(currenturl) '''处理过程'''我见过的很多分页的网站都有这种规律
那么另一个问题又来了,how can I get the lastpage,这得向网页中去找答案
进入网页,通过F12 或 Ctrl+Shift+I 或 网页上右击 =》检查 打开网页检查工具,选择在Elements选项卡,在htmls源码上移动鼠标,左边会发生响应的反应,这样可以轻松的找到某些部分的源码所在
我本来打算通过解析html页面获取最后一页,但是失败了,这里好像是动态生成的,根据用户的实际博文数量动态生成页码,但是后来在一对script中发现了这些数据
这个就不能用BeautifulSoup来获得了,我用正则表达式进行了属性提取
match = re.search(r'pageSize = (\d+).+\n.+listTotal = (\d+)', r0.text, flags=re.M) pageSize = match.group(1) listTotal = match.group(2)然后拼接每页的url
baseurl = 'https://blog.csdn.net/BBJG_001/article/list/' pages = int(listTotal)//int(pageSize)+1 for i in range(1,pages+1): url = baseurl+str(i) -
解析网页
然后分析我的博客列表中的一页
先获取改网页对象
res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser')一个博客项包含在一个class=article-item-box csdn-tracking-statistics的div下,获得所有的这样的div列表
divs = soup.find_all(name='div', attrs={'class': 'article-item-box csdn-tracking-statistics'})遍历上面的div列表从每个div中取出a标签组成一个a标签的列表
aas = [div.find('a') for div in divs] # 获得包含文章链接的a标签遍历上面的div列表从每个div中取出包含阅读数的span标签组成一个span标签的列表
spans = [div.find(name='span', attrs={'class': 'num'}) for div in divs] # 获得包含阅读量的span分别从a列表中提取href、从span列表中提取数字,组成{href : num}的字典
data = {a.attrs.get('href'): int(span.text) for a, span in zip(aas, spans)} -
数据处理
print('最受欢迎的文章:', max(alldata, key=alldata.get)) # 返回字典中最大值对应的key # 最受欢迎的文章: https://blog.csdn.net/BBJG_001/article/details/104189333 plt.bar(range(len(alldata)), list(alldata.values())) # 柱状图 plt.ylim(0, 250) # 为了不使结果看着太过悬殊,限制y轴高度 plt.show()出图如下
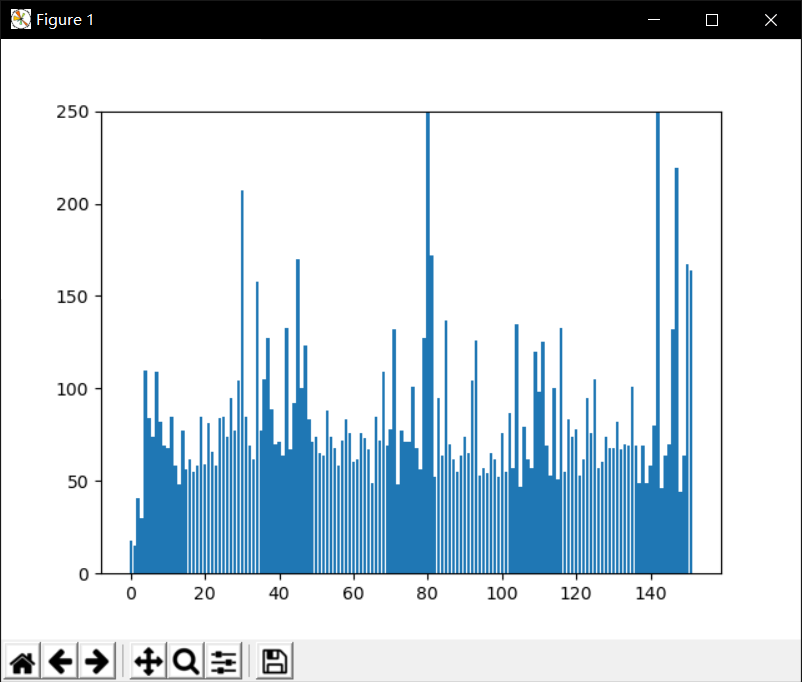
-
完整代码
import requests from bs4 import BeautifulSoup # 解析html网页的 import re import matplotlib.pyplot as plt def getaPageData(url): res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser') divs = soup.find_all(name='div', attrs={'class': 'article-item-box csdn-tracking-statistics'}) aas = [div.find('a') for div in divs] # 获得包含文章链接的a标签 spans = [div.find(name='span', attrs={'class': 'num'}) for div in divs] # 获得包含阅读量的span return {a.attrs.get('href'): int(span.text) for a, span in zip(aas, spans)} # 封装成字典返回 if __name__ == '__main__': indexurl = 'https://blog.csdn.net/BBJG_001' baseurl = 'https://blog.csdn.net/BBJG_001/article/list/' r0 = requests.get(indexurl) alldata = {} match = re.search(r'pageSize = (\d+).+\n.+listTotal = (\d+)', r0.text, flags=re.M) pageSize = match.group(1) # 40 listTotal = match.group(2) # 152 pages = int(listTotal) // int(pageSize) + 1 for i in range(1, pages + 1): url = baseurl + str(i) datai = getaPageData(url) alldata.update(datai) # 向alldata中追加本轮url的数据 print('最受欢迎的文章:', max(alldata, key=alldata.get)) # 返回字典中最大值对应的key plt.bar(range(len(alldata)), list(alldata.values())) # 柱状图 plt.ylim(0, 250) # 为了不使结果看着太过悬殊,限制y轴高度 plt.show() -
相关参考
