Zookeeper基本知识
ZooKeeper集群搭建
Zookeeper集群搭建指的是ZooKeeper分布式模式安装。通常由2n+1台servers组成。这是因为为了保证Leader选举(基于Paxos算法的实现)能过得到多数的支持,所以ZooKeeper集群的数量一般为奇数。
Zookeeper运行需要java环境,所以需要提前安装jdk。对于安装leader+follower模式的集群,大致过程如下:
- 配置主机名称到IP地址映射配置
- 修改ZooKeeper配置文件
- 远程复制分发安装文件
- 设置myid
- 启动ZooKeeper集群
如果要想使用Observer模式,可在对应节点的配置文件添加如下配置:
peerType=observer
其次,必须在配置文件指定哪些节点被指定为Observer,如:
server.1:node-1:2181:3181:observer
ZooKeeper概述
Zookeeper是一个 分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题。
ZooKeeper本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。
ZooKeeper特性
- 全局数据一致:集群中每个服务器保存一份相同的数据副本,client无论连接到哪个服务器,展示的数据都是一致的,这是最重要的特征;
- 可靠性:如果消息被其中一台服务器接受,那么将被所有的服务器接受。
- 顺序性:包括全局有序和偏序两种:全局有序是指如果在一台服务器上消息a在消息b前发布,则在所有Server上消息a都将在消息b前被发布;偏序是指如果一个消息b在消息a后被同一个发送者发布,a必将排在b前面。
- 数据更新原子性:一次数据更新要么成功(半数以上节点成功),要么失败,不存在中间状态
- 实时性:Zookeeper保证客户端将在一个时间间隔范围内获得服务器的更新信息,或者服务器失效的信息
ZooKeeper集群角色
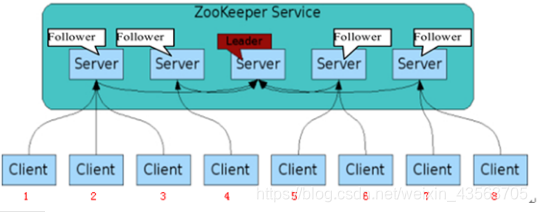
Leader:
Zookeeper集群工作的核心
事务请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性;
集群内部各个服务器的调度者。
对于create,setData,delete等有写操作的请求,则需要统一转发给leader处理,leader需要决定编号、执行操作,这个过程称为一个事务。
Follower:
处理客户端非事务(读操作)请求,转发事务请求给Leader;
参与集群Leader选举投票。
此外,针对访问量比较大的zookeeper集群,还可新增观察者角色。
Observer:
观察者角色,观察Zookeeper集群的最新状态变化并将这些状态同步过来,其对于非事务请求可以进行独立处理,对于事务请求,则会转发给Leader服务器进行处理。
不会参与任何形式的投票只提供非事务服务,通常用于在不影响集群事务处理能力的前提下提升集群的非事务处理能力。
