在实际产品的软件开发过程中,很多时候会对代码的性能提出要求,追求最快的速度,提高程序运行效率,改善用户体验等,此时此刻,对代码的优化就非常有必要了,掌握代码的优化方法和技巧就很有必要了。
我们用下面的一段短小的代码为例,来看看优化的过程,并且简略分析一下起优化的原理。
这段代码在CRC的校验中有机会用到,功能是将一个字节的数据逐位的颠倒反转。
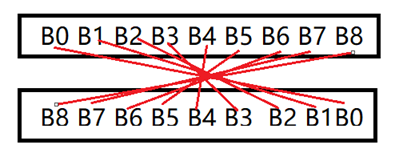
//功能: 将数据的位反转,即b0->b7,b1->b6...b7->b0
//des: 转换后的目标buffer
//src: 源数据
//len: 数据长度
void Invert8(unsigned char *des, unsigned char *src,unsigned int len)
{
unsigned char i,j,temp;
for (j = 0; j < len; j++)
{
temp = 0;
for (i = 0; i < 8; i++)
{
if((*src) & (1 << i))
temp |= 1 << (7 - i);
}
*des = temp;
des++;
src++;
}
}
我们先第一遍运行,看看这个常规写法的运行时间是多少(CPU速度72MHz)
调用:Invert8(dst,src,100); 颠倒100个字节
从运行结果我们看到,总计耗时:0.00002001s

第一步优化:优化内层循环体类的取值方法
if((src) & (1 << i))
优化为:
if(t & (1 << i))
这个位于for循环里面的判断语句,每一次都使用了src取原始数据,由于是采用指针的间接寻址(在汇编语言中就是变址寻址),这个循环就要发生8次的取数据运算。我们优化的时候,在这个循环外面先把数据取出来再参与运算:
t = *src;
有了这个数据预取动作后,在后面的循环内部就不需要再每一次去取数据了,看看优化前后的汇编代码对比,发现在循环内部少了一条取数据指令:
LDRB r6,[r1,#0x00]
只是在循环体外增加了一条LDRB r6,[r1,#0x00]指令,那么这样一来,一个8次循环就减少了7次取数据的操作,从而得以提高速度。
通过后面的仿真结果我们看出来,处理这100个字节的数据,优化后速度变为:0.00001785s了,速度提高了0.00000216s,速度提高了10.79%。
小有进展!


第二步 这个速度还没有达到我们期望的值,那么我们再看看,还有那些环节可以继续优化
for (i = 0; i < 8; i++)
{
if((*src) & (1 << i))
temp |= 1 << (7 - i);
}
仔细观察,在这个内循环里面,我们发现每一次循环都要进行一次移位运算(1 << i)和一次减法后的移位运算1 << (7 - i),那我们的目标就是消除这两个运算。
我们采用下面的方式解决了这两个问题:
if(t & 0x01)
temp |= 0x80;
if(t & 0x02)
temp |= 0x40;
if(t & 0x04)
temp |= 0x20;
if(t & 0x08)
temp |= 0x10;
if(t & 0x10)
temp |= 0x08;
if(t & 0x20)
temp |= 0x04;
if(t & 0x40)
temp |= 0x02;
if(t & 0x80)
temp |= 0x01;
通过这样修改以后,用空间(代码量会增加)来换取时间,达到了优化的目的。
运行的结果:0.00000692,仅仅为原来的34.5%,也就是说我们经过这两步的优化,速度提升了将近3倍,是不是非常厉害啊!

总结:
在优化代码的时候,对于只执行一次的代码,优化的价值不大,我们优化代码的目标就是循环体里面的代码部分,哪怕一次减少一条指令的开销,循环次数一旦多起来了,最后优化的效果就非常明显。特别对于底层驱动和中断函数,写最优的代码是一种良好编码习惯和能力的表现。
原创文章,欢迎转载,请注明来源,未经书面允许,请勿用于商业用途。
