今日头条:
- 输入为 ,卷积核为 ,还有步长 和 填充 ,求输出尺寸?求操作的 FLOPs?
答:输出尺寸为 ,
- 过拟合要怎么解决?
通常解决过拟合的方法有:Dropout(随机失活)、Weight Decay(权重衰减)、减少模型参数、Early Stop、Regularization(正则化,包括 正则化等)、Augmentation(数据增强)、合成数据、Batch Normalization(批次标准化)、Bagging 和 Boosting(模型融合)等;
- 几个激活函数都有什么优缺点(Sigmoid, Tanh, Relu)?
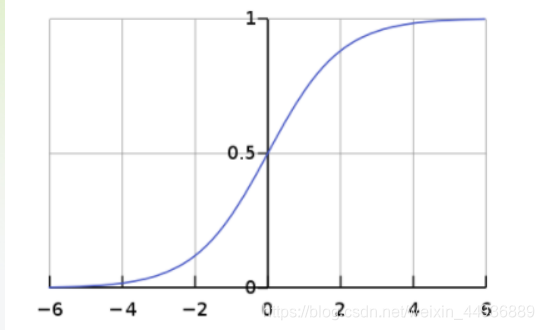
Sigmoid:
- 定义式:
- 函数曲线:
- 优点:
3.1 输出为 0 到 1 之间的连续实值,此输出范围和概率范围一致,因此可以用概率的方式解释输出;
3.2 将线性函数转变为非线性函数;- 缺点:
4.1 幂运算相对来讲比较耗时;
4.2 输出均值为非 0;
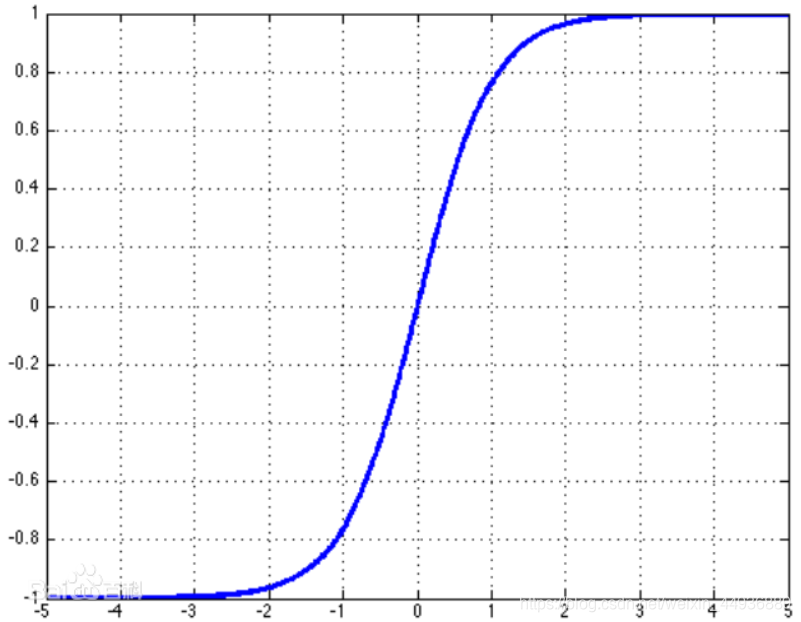
4.3 容易出现梯度消失的问题;Tanh:
- 定义式:
- 函数曲线:
- 优点:
3.1 Tanh 函数的导数比 Sigmoid 函数导数值更大、梯度变化更快,在训练过程中收敛速度更快;
3.2 使得输出均值为 0,可以提高训练的效率;
3.3 将线性函数转变为非线性函数;- 缺点:
4.1 幂运算相对来讲比较耗时;
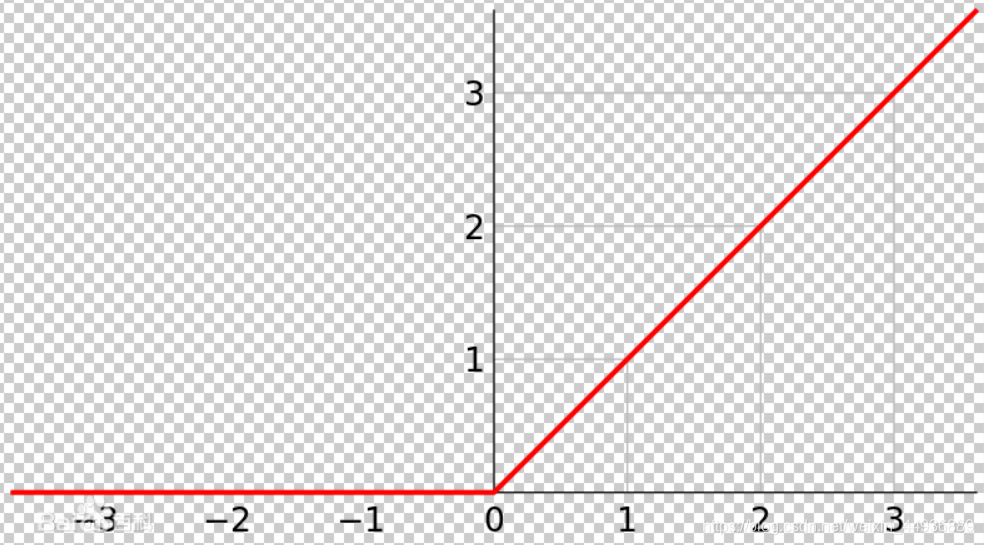
4.2 容易出现梯度消失;ReLU:
- 定义式:
- 函数曲线:
- 优点:
3.1 解决了梯度消失的问题;
3.2 计算速度和收敛速度非常快;- 缺点:
4.1 低维特征向高维转换时会部分丢失;
4.2 均值为非零;
- 概率题: 服从 均匀分布,求 的概率? 服从 均匀分布,求 的概率?
- Batch Normalization 的原理和作用?
将一个 batch 的数据变换到均值为 0、方差为 1 的正态分布上,从而使数据分布一致,每层的梯度不会随着网络结构的加深发生太大变化,从而避免发生梯度消失并且加快收敛,同时还有防止过拟合的效果;

- 举一个改进激活函数的例子?
h-swish 函数,是 MobileNet V3 提出的,用于改进 swish 函数在嵌入式设备计算效率低的问题;
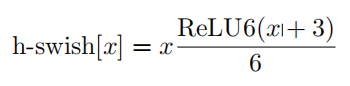
拼多多:
- L2正则化的特点和使用场景?
正则化目的是限制参数过多或者过大,避免模型更加复杂,适用于数据充足的场景下防止过拟合;
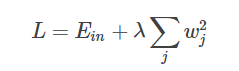
- L1正则化损失函数如何求解?
参考这一篇:https://www.cnblogs.com/heguanyou/archive/2017/09/23/7582578.html
- LSTM 的结构及公式?


虹软科技:
- Loss 优化的几个方法?
主要有三大类:
- 基本梯度下降法,包括 GD,BGD,SGD;
- 动量优化法,包括 Momentum,NAG 等;
- 自适应学习率优化法,包括 Adam,AdaGrad,RMSProp 等
- 动量法的表达式?
- 标准动量优化方法(MomentumOptimizer):
- 牛顿加速梯度动量优化方法(NAG, Nesterov accelerated gradient):
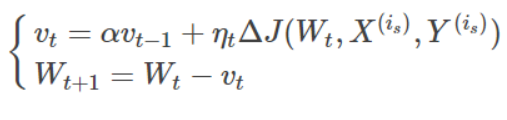

- 随机梯度下降相比全局梯度下降好处是什么?
- 当处理大量数据时,比如SSD或者faster-rcnn等目标检测模型,每个样本都有大量候选框参与训练,这时使用随机梯度下降法能够加快梯度的计算;
- 每次只随机选择一个样本来更新模型参数,因此每次的学习是非常快速的,并且可以进行在线更新;
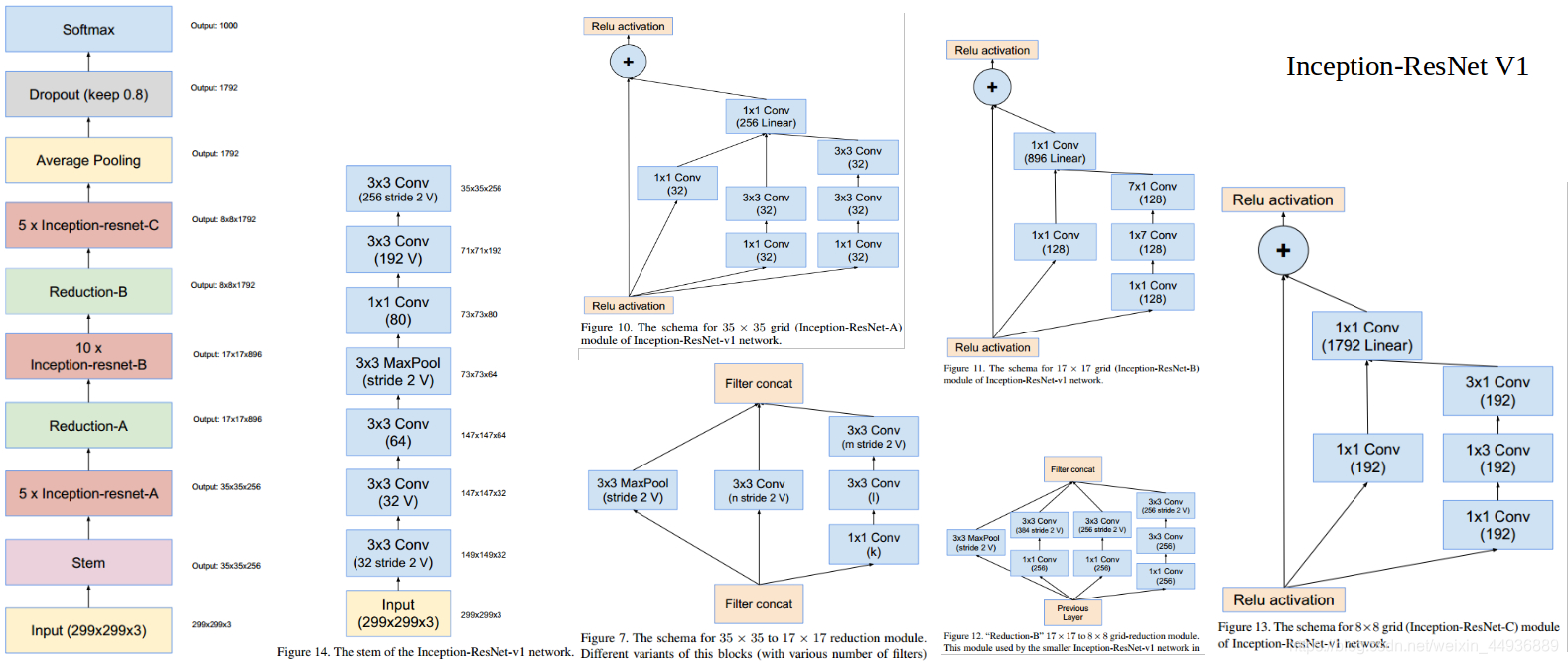
- 介绍 Inception-resnet v1?
并行结构、非对称卷积、残差;
小红书:
- 归一化有哪些方式?
- min-max 标准化(Min-max normalization):
1.1 公式:
1.2 适用场景:
适用于数据集中的场景,如果 max 和 min 不稳定,很容易使得归一化结果不稳定;- z-score 0均值标准化(zero-mean normalization):
2.1 公式:
2.2 适用场景:
在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,表现更好;
海康威视:
- L1、L2正则化在什么任务上分别会优先考虑?
假设模型中有很多特征,其中不乏相关性特征,可以用L1消除共线性问题;
在训练样本足够多的情况,然后尝试使用L2来防止过拟合问题;
- 两层神经网络的权重都是0,bias有值,这个网络能正常训练吗?
不能,因为权重为 0,每次传入不同数据得到的结果相同;
网易:
- C++和python的区别?
- C++是静态类型的,而python是动态类型的;
- python是一种脚本语言,是解释执行的,不需要经过编译;C++需要编译后运行语言,在特定的机器上编译后在特定的机上运行,运行效率高,安全稳定,但编译后的程序一般是不跨平台的;
- python是逐句解释执行的,C++是先编译成本地代码,期间还有编译期的类型检查,不存在动态类型、动态检查,并且可以进行编译器优化;
- Python比C++好在哪里?
自动能实现内存回收机制,开发效率高;
- python怎么做内存回收?
- 当对象不再被引用指向的时候,垃圾收集器可以释放该对象;
- 手动回收:gc.collect();
招银网络科技:
- 哪种激活函数能缓解梯度爆炸弥散 ?
relu、leakrelu、elu 等;
- Pooling是不是线性操作?
不是;
- Dropout介绍?
Dropout 是指在模型训练时随机让网络某些隐含层节点的权重不工作,不工作的那些节点可以暂时认为不是网络结构的一部分,但是它的权重得保留下来(只是暂时不更新而已),用于防止模型过拟合;
- 输入是特征向量的分类网络,怎么找比较重要的那些特征?
使用 SE-Net 的 SE 模块;
- yolo 介绍?
- 检测任务中解决正负样本不均衡的方法?
- online hard example mining(OHEM);
- Focal Loss;
- class balanced cross-entropy;
- local rank,PISA,ISR;
- 过采样;
- dropout为什么能解决过拟合 ?
简单的回答是:防止参数过分依赖训练数据,减少神经元之间复杂的共适应关系,增加参数对数据集的泛化能力;
- 卷积有哪些变种?
分组卷积(Group Convolution)、空洞(扩张)卷积(Dilated/Atrous Convolution)、深度可分离卷积(depthwise separable convolution)、可变形卷积网络(Deformable Convolution)、反卷积(deconvolution)、图卷积(Graph Convolution)和 X-卷积(PointCNN);
