前言:这是一个轻量的视频标注软件,相比于ViTBAT等软件而言,不需要安装就可以使用。但是由于是一个韩国人开发的,所以相关的说明不太够,所以这里进行一个darklabel软件的使用指南。之后会在这个视频标注的基础上进行一些脚本的编制,有利于ReID数据集、目标检测数据集和MOT数据集的快速构建
文章目录
1. 官方相关说明
它是一个实用程序,可以沿着视频(avi,mpg)或图像列表中对象的矩形边界框以各种格式标记和保存。 该程序可用于创建用于对象识别或图像跟踪目的的数据库。最大的功能是快速响应,便捷的界面以及减少工作量的便捷 功能(自动跟踪,使用插值进行标记,自动ID标记)。 任何人都可以将其用于非商业目的,如果您有任何问题或建议,请在评论中让我知道。最初是为我自己创建的,最近我 花了些时间来改进该程序(ver1.3)。我们已经改进了难以看清的细微之处,但是改善了程序的质量,执行的稳定性 和未知性。
软件示意:
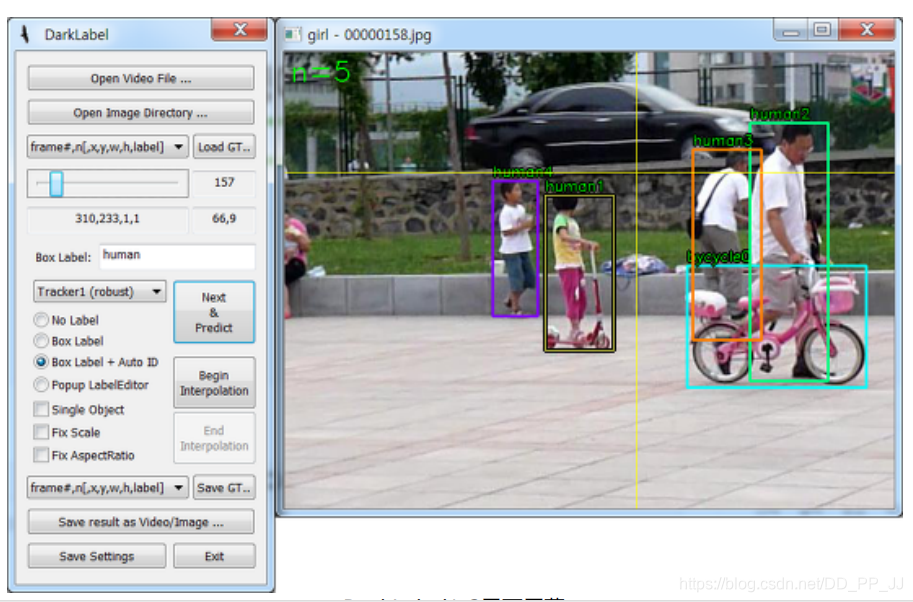
工具栏在左侧:
2. 主要功能和特点
-
支持各种格式的视频(avi,mpg等)和图像列表(jpg,bmp,png等)
-
多框设置和标签设置支持
-
支持对象识别和图像跟踪中使用的各种数据格式
扫描二维码关注公众号,回复: 9779793 查看本文章
-
使用图像跟踪器自动标记(通过跟踪标记)
-
支持使用插值功能的间隔标签
-
自动标记功能,可按类别自动为每个对象分配唯一的ID
3. 主要用法
3.1 鼠标/键盘界面(Shift / Ctrl = Shift或Ctrl)
- 鼠标拖动:创建一个框
- Shift / Ctrl +拖动:编辑框
- 双击:选择/取消相同ID对象的轨迹
- 右键单击:删除所有选定的对象轨迹(删除部分)
- 右键单击:删除最近创建的框(如果未选择任何轨迹)
- Shift / Ctrl +右键单击(特定框):仅删除所选框
- Shift / Ctrl +右键单击(空):删除当前屏幕上的所有框
- Shift / Ctrl +双击(特定框):修改所选框的标签
- Shift / Ctrl +双击(轨迹):在所选轨迹上批量更改标签
- 箭头键/ PgUp / PgDn / Home / End:移动视频帧(图像)
- Enter键:使用图像跟踪功能自动生成框(通过跟踪进行标记)
3.2 指定标签和ID
- 无标签:创建未标签的框
- 框标签:用户指定的标签(例如,人类)
- box标签+自动编号:自动编号自定义标签(例如human0,human1等)
- 如果指定了id,则可以选择/编辑轨迹单位对象
- popuplabeleditor:注册标签列表窗口的弹出窗口(已在labels.txt文件中注册)
- 如果在弹出窗口中按快捷键(1〜9),则会自动输入标签。
- Label + id显示在屏幕上,但在内部,标签和ID分开。
- 当另存为gt数据时,选择仅标签格式以保存可见标签(标签+ id)
- 另存为gt数据时,如果选择了标签和ID分类格式,则标签和ID将分开保存。
3.3 追踪功能
- 通过使用图像跟踪功能设置下一帧的框(分配相同的ID /标签)
- 多达100个同时跟踪
- tracker1(稳健)算法:长时间跟踪目标
- tracker2(准确)算法:准确跟踪目标(例如汽车)
- 输入键/下一步和预测按钮
- 注意!使用跟踪时,下一帧上的原始框消失
建议使用tracker2,效果很好,几乎不用人工调整
3.4 插值功能
- 跟踪功能方便,但问题不准确
- 在视频部分按对象标记时使用
- 开始插补按钮:开始插补功能
- 在目标对象的轨迹的一半处绘制一个方框(航路点的种类)
- 航路点框为紫色,插值框为黑色。
- 更正插值错误的部分(Shift / Ctrl +拖动),添加任意数量的航路点(不考虑顺序)/删除
- 结束插补按钮:将工作结束和工作轨迹注册为数据
3.5 导入视频/视频并在帧之间移动
- 打开视频文件:打开视频文件(avi,mpg,mp4,wmv,mov,…)
- 打开图像目录:打开文件夹中的所有图像(jpg,bmp,png等)
- 在视频帧之间移动:键盘→,←,PgUp,PgDn,Home,End,滑块控制
3.6 保存并调出作业数据
- 加载GT:以所选格式加载地面真相文件。
- 保存GT:以所选数据格式保存到目前为止已获得的结果。
- 导入数据时,需要选择与实际数据文件匹配的格式,但是在保存数据时,可以将其保存为所需的任何格式。
- 在图像列表中工作时,使用帧号(frame#)格式,按文件名排序时的图像顺序将变为帧号(对于诸如00000.jpg,00002.jpg等的列表很有用)
- 保存设置:保存当前选择的数据格式和选项(运行程序时自动还原)
3.7 数据格式(语法)
- |:换行
- []:重复短语
- frame#:帧号(视频的帧号,图像列表中的图像顺序)
- iname:图像文件名(仅在使用图像列表时有效)
- 标签:标签
- id:对象的唯一ID
- n:在图像上设置的边界矩形的数量
- x,y:边界矩形的左侧和顶部位置
- w,h:边界矩形的宽度和高度
- cx,cy:边界矩形的中心坐标
- x1,y1,x2,y2:边界矩形的左上,右下位置
4. 举栗子
-
选择open video file,选择一个视频打开,最好不要太长
-
左右拖动一下滑块,看一下准备标注的对象
-
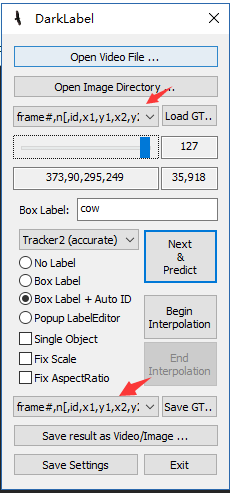
如果标注视频选择左侧工具栏中第三行,下拉找到frame开头的内容比如:frame#, n, [id, x1,y1,x2,y2,label],意思是左上角坐标和右下角坐标。
-
然后右侧框中进行画框,然后可以采用以下几种方法继续标注
- 画框以后,长按Enter键,就会采用Tracker2中的模式进行预测,效果不多
- 先点击begin interpolation按钮,然后画框,然后按左右键对视频帧进行移动,然后再画一个关键框,完成后点击End interpolation按钮结束(这种模式可以进行通过插值进行预测中间帧)
-
最后选择合适的标注模型,点击Save GT,保存为txt文件
5. ffmpeg切割视频
ffmpeg -i C:/plutopr.mp4 -acodec copy
-vf scale=1280:720
-ss 00:00:10 -t 15 C:/cutout1.mp4 -y
- -ss time_off set the start time offset 设置从视频的哪个时间点开始截取,上文从视频的第10s开始截取
- -to 截到视频的哪个时间点结束。上文到视频的第15s结束。截出的视频共5s.如果用-t 表示截取多长的时间如 上文-to 换位-t则是截取从视频的第10s开始,截取15s时长的视频。即截出来的视频共15s.
- -vcodec copy表示使用跟原视频一样的视频编解码器。
- -acodec copy表示使用跟原视频一样的音频编解码器。
- -i 表示源视频文件
- -y 表示如果输出文件已存在则覆盖。
- -vf 设置视频分辨率
6. 软件下载
链接:https://pan.baidu.com/s/1_0l0qXQ6zuA5y5x3IZ3yPw
提取码:l7ga
文件名:DarkLabel1.3_part1.zip
7. ReID数据集配置代码
import os
import shutil
import cv2
def preprocessVideo(video_path):
if not os.path.exists(video_frame_save_path):
os.mkdir(video_frame_save_path)
vidcap = cv2.VideoCapture(video_path)
(cap, frame) = vidcap.read()
height = frame.shape[0]
width = frame.shape[1]
cnt_frame = 0
while (cap):
cv2.imwrite(
os.path.join(video_frame_save_path, "frame_%d.jpg" % (cnt_frame)),
frame)
cnt_frame += 1
(cap, frame) = vidcap.read()
vidcap.release()
return width, height
def postprocess(video_frame_save_path):
if os.path.exists(video_frame_save_path):
shutil.rmtree(video_frame_save_path)
def extractVideoImgs(frame, video_frame_save_path, coords):
x1, y1, x2, y2 = coords
# get image from save path
img = cv2.imread(
os.path.join(video_frame_save_path, "frame_%d.jpg" % (frame)))
# crop
save_img = img[y1:y2, x1:x2]
return save_img
if __name__ == "__main__":
for num in range(1, 34):
txt_path = r"C:\Users\pprp\Videos\face_%d_gt.txt" % (num)
video_path = r"C:\Users\pprp\Videos\face_%d.mp4" % (num)
reid_dst_path = r"C:\Users\pprp\Videos\reid"
if not os.path.exists(txt_path):
continue
video_name = os.path.basename(video_path).split('.')[0]
video_frame_save_path = os.path.join(os.path.dirname(video_path),
video_name)
f_txt = open(txt_path, "r")
width, height = preprocessVideo(video_path)
for line in f_txt.readlines():
bboxes = line.split(',')
# print(len(bboxes))
ids = []
frame_id = int(bboxes[0])
num_object = int(bboxes[1])
for num_obj in range(num_object):
# obj = 0, 1, 2
obj_id = bboxes[1 + (num_obj) * 6 + 1]
obj_x1 = int(bboxes[1 + (num_obj) * 6 + 2])
obj_y1 = int(bboxes[1 + (num_obj) * 6 + 3])
obj_x2 = int(bboxes[1 + (num_obj) * 6 + 4])
obj_y2 = int(bboxes[1 + (num_obj) * 6 + 5])
# process coord
obj_x1 = max(1, obj_x1)
obj_y1 = max(1, obj_y1)
obj_x2 = min(width - 1, obj_x2)
obj_y2 = min(width - 1, obj_y2)
print("%s:%d-%d-%d-%d" %
(obj_id, obj_x1, obj_y1, obj_x2, obj_y2))
# mkdir for reid dataset
id_dir = os.path.join(reid_dst_path,
video_name + "_id_" + obj_id)
if not os.path.exists(id_dir):
os.mkdir(id_dir)
# save pic
img = extractVideoImgs(frame_id, video_frame_save_path,
(obj_x1, obj_y1, obj_x2, obj_y2))
cv2.imwrite(
os.path.join(id_dir, "filename_%s_frame_%d.jpg") %
(video_name, frame_id), img)
f_txt.close()
postprocess(video_frame_save_path)
主要需要修改:
txt_path = r"C:\Users\pprp\Videos\face_%d_gt.txt" % (num)
video_path = r"C:\Users\pprp\Videos\face_%d.mp4" % (num)
reid_dst_path = r"C:\Users\pprp\Videos\reid"
运行即可在reid_dst_path下找到对应的数据集。
如果遇到图片需要旋转的问题,可以采用如下代码:
import os
import cv2
import numpy as np
dirlist = ['face_%d_id_0' % i for i in range(8,9) ] # ['face_8_id_0']
rootdir = r"C:\Users\pprp\Videos\reid"
for item in dirlist:
new_dir = os.path.join(rootdir, item)
for jpg_name in os.listdir(new_dir):
print(jpg_name)
jpg_path = os.path.join(new_dir, jpg_name)
img = cv2.imread(jpg_path)
img = np.rot90(img)
cv2.imwrite(jpg_path,img)
