仅供学习交流
需求分析:
爬取的资源:爬取某招聘网站的Java岗位的招聘信息,并保存到数据库。
代码示例:
1.准备工作
①引入依赖(pom.xml)
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<!--jsoup-->
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.11.2</version>
</dependency>
<!--客户端编程工具包-->
<dependency>
<groupId>org.apache.httpcomponents</groupId>
<artifactId>httpclient</artifactId>
<version>4.5.6</version>
</dependency>
<!--IO操作工具类库-->
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>
<!--MySql驱动-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>
<!--druid连接池-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.10</version>
</dependency>
<!--JDBCTemplate-->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-core</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-jdbc</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.0.8.RELEASE</version>
</dependency>
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
②准备数据库连接池与配置文件
通过数据库连接池获取数据库连接的操作封装成一个工具类(JDBCUtils.java) 教程
- 数据库连接池(JDBCUtils)
public class JDBCUtils {
//使用Druid数据库连接池技术获取数据库连接
private static DataSource createDataSource;
static{
try {
Properties pros = new Properties();
InputStream is = JDBCUtils.class.getResourceAsStream("/druid.properties");
//InputStream is = ClassLoader.getSystemClassLoader().getResourceAsStream("druid.properties");
pros.load(is);
createDataSource = DruidDataSourceFactory.createDataSource(pros);
} catch (Exception e) {
e.printStackTrace();
}
}
//得到连接的方法
public static Connection getConnection1() throws SQLException{
return createDataSource.getConnection();
}
//得到数据源的方法
public static DataSource getDataSource() {
return createDataSource;
}
}
- Druid数据库连接池配置文件(druid.properties)
url=jdbc:mysql:///recruitmentspider
username=root
password=root
driverClassName=com.mysql.jdbc.Driver
initialSize=10
maxActive=10
2.爬取资源
- 使用Jsoup解析HTML进行数据收集并把数据存储到数据库(SpiderLagouTest)
public class SpiderLagouTest {
int substring=1;
@Test
public void test() throws IOException {
String url="https://www.lagou.com/zhaopin/Java/"+substring+"/";
//爬取招聘信息
fetchRecruitmentData(url);
}
private void fetchRecruitmentData(String url) throws IOException {
try {
//过10秒在爬取(如果是持续爬取,爬取五六页就爬取不到数据了)
Thread.sleep(10000);
} catch (InterruptedException e) {
e.printStackTrace();
}
//1.读取url,得到Document
Document document = Jsoup.connect(url).get();
//2.得到招聘信息Elements,循环处理每个Element
Elements elements = document.select(".item_con_list .con_list_item");
for (Element element : elements) {
//得到公司名
String companyName = element.select(".company_name a").text();
System.out.println("公司名称:"+companyName);
//得到工作地址
String workAddress = element.select(".add em").text();
System.out.println("工作地址:"+workAddress);
//得到招聘职位
String tip=element.select(".p_top h3").text();
System.out.println("招聘职位:"+tip);
//得到工资,工作经验,学历要求
String money_bot = element.select(".p_bot").text();// 得到的money_b为:15k-25k 经验3-5年 / 本科
System.out.println(money_bot);
//public String substring(int beginIndex,int endIndex):返回一个新字符串,它是此字符串的一个子字符串。该子字符串从指定的 beginIndex 处开始,直到索引 endIndex - 1 处的字符。因此,该子字符串的长度为 endIndex-beginIndex。
String money = money_bot.substring(0,money_bot.indexOf(" "));
System.out.println("工资范围:"+money);
//public String substring(int beginIndex):返回一个新的字符串,它是此字符串的一个子字符串。该子字符串从指定索引处的字符开始,直到此字符串末尾。
//public int indexOf(String str) 返回指定子字符串str在此字符串中第一次出现处的索引。
String workExperience = money_bot.substring(money_bot.indexOf(" ")+1,money_bot.indexOf("/"));
System.out.println("工作经验:"+workExperience);
String education = money_bot.substring(money_bot.indexOf("/")+2);
System.out.println("学历要求:"+education);
//得到行业领域 融资阶段 公司规模
String synopsis = element.select(".industry").text(); //得到的synopsis为:移动互联网,硬件 / D轮及以上 / 2000人以上
//行业领域
String industryfield = synopsis.substring(0 ,synopsis.indexOf("/"));
System.out.println("行业领域:"+industryfield);
//融资阶段
String financingStage = synopsis.substring(synopsis.indexOf("/")+2,synopsis.lastIndexOf("/"));
System.out.println("融资阶段:"+financingStage);
//公司规模
String companySize = synopsis.substring(synopsis.lastIndexOf("/") + 2);
System.out.println("公司规模:"+companySize);
//得到技术或福利标签
String skill = element.select(".list_item_bot .li_b_l").text();
System.out.println("职位描述或福利标签:"+skill);
//得到福利信息
String welfare = element.select(".li_b_r").text();
System.out.println("职位福利:"+welfare);
//得到企业图片
String src = element.select(".com_logo img").attr("src");
//获取到的src为://www.lgstatic.com/thumbnail_120x120/i/image/M00/A5/6B/Cgp3O1ir8wOAJzPbAAIHeppEuoE288.png
String path= fetchImage("http:" + src);
System.out.println("图片保存路径:"+path);
//存储到数据库
JdbcTemplate jdbcTemplate = new JdbcTemplate(JDBCUtils.getDataSource());
String sql="INSERT INTO lagou_java2 (id,companyName,workAddress,tip,money,workExperience,education,industryfield,financingStage,companySize,skill,welfare,path) VALUES (null,?,?,?,?,?,?,?,?,?,?,?,?);";
jdbcTemplate.update(sql,companyName,workAddress,tip,money,workExperience,education,industryfield,financingStage,companySize,skill,welfare,path);
System.out.println("---------------------");
}
//3.得到下一页的url
//通过浏览器开发者工具查看到下一页的链接地址:https://www.lagou.com/zhaopin/Java/2/
if(substring<10){
substring = Integer.parseInt(url.substring(url.lastIndexOf("/") - 1, url.lastIndexOf("/")))+1;
System.out.println(substring+"<10" );
}else if(substring>=10&&substring<100){
substring = Integer.parseInt(url.substring(url.lastIndexOf("/") - 2, url.lastIndexOf("/")))+1;
System.out.println(substring+">=10&&"+substring+"<100");
}else if(substring>100){
substring = Integer.parseInt(url.substring(url.lastIndexOf("/") - 3, url.lastIndexOf("/")))+1;
}
System.out.println("开始爬取第"+substring+"页");
String href="https://www.lagou.com/zhaopin/Java/"+substring +"/";
System.out.println(href);
System.out.println("============================================================================");
fetchRecruitmentData(href);
}
private static String fetchImage(String src) throws IOException {
// 1.创建一个浏览器对象
CloseableHttpClient client = HttpClients.createDefault();
//2.创建请求信息,设置请求的地址
HttpGet get = new HttpGet(src);
//3.使用浏览器发送请求,把get请求发送,并得到响应结果
CloseableHttpResponse response = client.execute(get);
//4.判断是否是正常响应
//文件存储路径与文件名
// src ———> http://www.lgstatic.com/thumbnail_120x120/i/image/M00/A5/6B/Cgp3O1ir8wOAJzPbAAIHeppEuoE288.png
String localPath="I:\\testSpider\\"+src.substring(src.lastIndexOf("/")+1);
if (response.getStatusLine().getStatusCode() == 200) {
//5. 获取响应的内容(响应体对象)
HttpEntity entity = response.getEntity();
//6. 获取响应体内容的输入流(响应体里是图片的二进制数据,使用输入流读取数据)
InputStream inputStream = entity.getContent();
OutputStream outputStream = null;
try {
//7. 创建一个输出流
outputStream = new FileOutputStream(localPath);
//8. 把输入流数据写到输出流
org.apache.commons.io.IOUtils.copy(inputStream, outputStream);
} catch (FileNotFoundException e) {
System.out.println("src= "+src+" 无法保存图片");
}finally {
//9. 关闭流
inputStream.close();
if(outputStream!=null){
outputStream.close();
}
}
}
//10. 结束响应
response.close();
return localPath;
}
}
3.爬取效果与数据处理
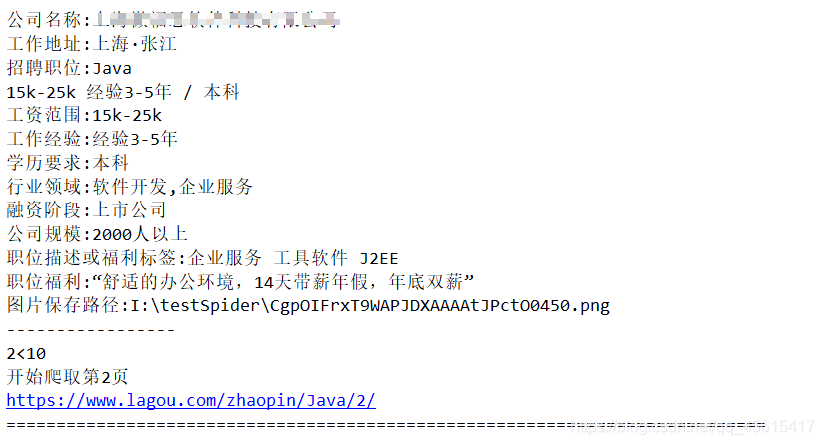
- 控制台输出:
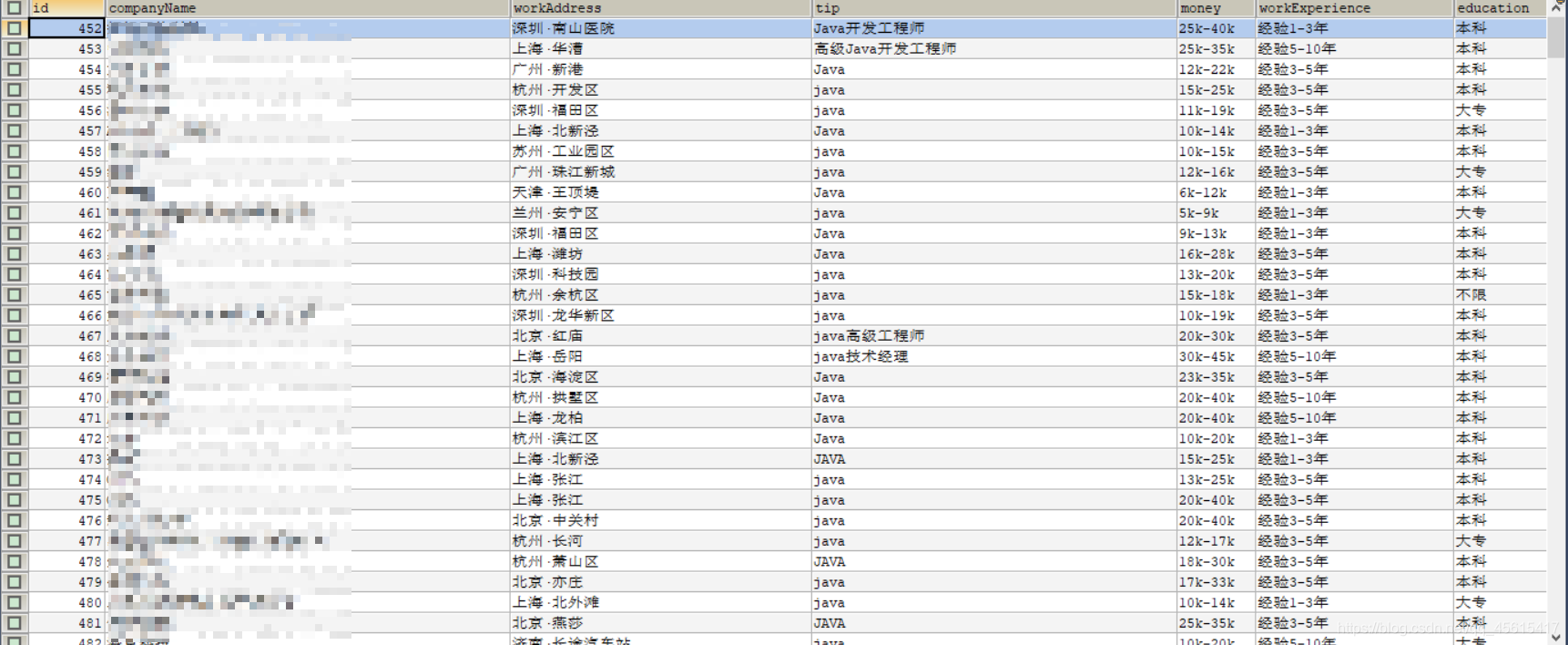
- 刷新查看数据库中的数据:
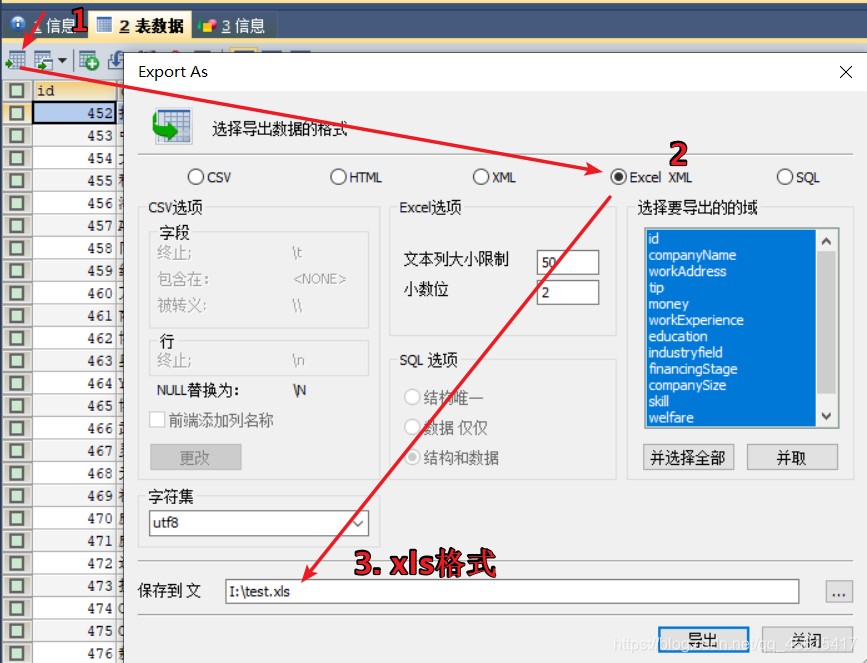
- 把数据库中的数据导出为excel:

遇到的问题:
持续爬取,爬取到六页后就爬取不到数据了,开始以为是网址的参数索引问题,打出日志发现索引没有问题,下一页的网址也能访问,但是通过程序爬取就是爬取不到。后来想到是不是访问太频繁,被关进“小黑屋”了???,于是在每次爬取下一页前休眠5秒,还是不行,爬取六页后还是爬取不到数据。觉得应该也不是这个问题,又折腾了很久…最后感觉还是访问太频繁的问题,然后把休眠时间改为10秒。。。。。成功爬取了30页招聘数据。

存在的问题:
如在爬取Java岗位的招聘信息时,有30页招聘数据,爬取完30页后,程序还会继续爬取,需手动停止。
