正在找JAVA工作的人。。。(1-3年)
本文目录
1、JAVA基础
2、HashMap
3、JVM
4、HTTP协议
5、设计模式
6、SpringBoot
7、MySQL
8、Mybatis
9、Docker
10、Session和cookies
11、CMM/CMMI的概念
12、敏捷开发经验?
面试内容
1、简单自我介绍
答:我叫xxx,来自xxx,工作xxx年,先后在xxx公司工作,做了哪些项目。
(有什么爱好:听音乐,写代码,打乒乓球、羽毛球之类的)
2、简述项目内容,并简单说一下自己承担的角色。
答:为了解决xxx问题而开发了一套xxx系统。简述系统整体架构,说一下自己在项目中开发的模块(业务及设计)
3、JAVA基础
4、多轮面试下来,自我介绍和项目经验不关心了,接下来问你最擅长什么,简单说一下。
答:我对xxx方面有些了解,然后开始和面试官嘴炮详细。
5、反问面试官(薪资待遇、工作内容,使用技术 ,项目负责,也可以说暂时没有)
待遇(包吃包住?)
加班吗?星期六星期天
试用期多长
工作地点(出差吗?)
项目负责
什么时候签合同?
有二面三面吗?多久有消息?
6、面试结束,回去等消息,hr跟你谈薪资福利
JAVA基础
1、JAVA跨平台开发原理
答:JAVA为多版本系统提供了统一接口(每个版本系统各有一个jdk,jvm),JAVA开发者只需要遵守JAVA开发规范,调用统一接口即可。
2、JAVA开发环境搭建
JDK,JAVA_HOME环境变量,IDE设置工作目录和默认编码,,Web服务器(Tomcat),Git/SVN版本管理,Maven/gradle构建工具。
3、JAVA有几种基本数据类型?
byte int long short float double char boolean
4、int占多少字节?4个32位
5、JAVA三大特征:封装、继承、多态 (、抽象)举例说明
6、有了基本数据类型,为什么还要封装类型?
因为基本数据类型不具备面向对象的特性。
7.==和equals的区别
==比较基本数据类型时,直接比较值,比较引用类型,比较的是地址。
equals调用的是对象的equals方法
8、String和StringBuilder的区别?StringBuilder和StringBuffer的区别?
String是内容不可变的字符串,StringBuilder和StringBuffer是内容可变的字符串,使用append方法,其中StringBuilder是线程不安全效率高,StringBuffer线程安全而效率低(append方法加锁了)
9、集合List、set、map
List(ArrayList 数组型查找快,删除和增加慢,LinkedList 查找慢,删除和增加快)
10、HashMap和HashTable的区别?还有ConcurrentHashMap的效果?
HashMap线程不安全效率高(key和value可以为null),HashTable线程安全,效率低(key和value不能为null)。ConcurrentHashMap线程安全效率又高。
11、拷贝文件用字节流还是字符流?垃圾问题
12、线程有几种启动方式。
方式一:继承Thread类(不推荐,JAVA只能单继承,继承了Thread类就不能再继承,扩展性不强)调用start方法启动。new Thread(继承了Thread类的类或实现了Runnable接口的类).start()启动之后执行的是run方法。
方式二:类实现runnable接口。
如何区分线程?thread.setName()
13、有没有使用过线程并发库?
简单了解过,JAVA通过Executors提供了四个静态方法创建线程池(最主要的newFixedThreadPool可以控制线程池的大小,超过的线程会在队列中等待)
使用线程池的优势:1、防止线程过多使系统运行缓慢或崩溃。2、线程池不需要每次创建或销毁,节约资源,响应时间快。
14、所有的类都从Object类继承了哪些方法?
继承了clone,equals,toString,hashcode,getClass,notify,wait
HashMap
定义HashMap时,会初始化一个初始容量(也可以自定义,默认是16)
JAVA7 (数组、链表)
JAVA8(数组、链表、红黑树)
第一次put会初始化数组。
初始容量为什么必须是2的指数幂?加载因子为什么是0.75?
如果不是,会就近转换为2的指数幂。
HashMap中数组初始化后,通过key的hashcode做一个hash映射(采用位运算),有冲突时采用拉链法(头插)解决hash冲突。(hashcode & (length -1) 位运算 == hashcode % 16,前提条件是length必须是2的指数幂,否则可能导致数组越界)
多次调用put,可能触发多次扩容(每次扩容需要rehash,此时位运算的优势就体现出来了)
为什么HashMap线程不安全?
JAVA7:
1、数据丢失(扩容的时候)
2、死锁(使用链表的时候,多线程扩容导致链表成环出不来)
JAVA8:
避免了死锁。(迁移链的时候,搞四组指针均匀迁移到新扩容数组)
为什么加载因子是0.75?
加载因子0.5就浪费空间,1就导致链表过长查询效率低,数学原理:牛顿二项式 ln 2约等于0.693
扩容。
链表转红黑树过程?
先判断数组长度 <64,即便链表长度达到8,则优先选择扩容。
如果数组长度超过64,才将长度超过8(阈值)的链表(实际的链表长度是9)
红黑树的5个性质:
1、每个节点只有红色和黑色
JVM
JVM的内存模型是怎样的?
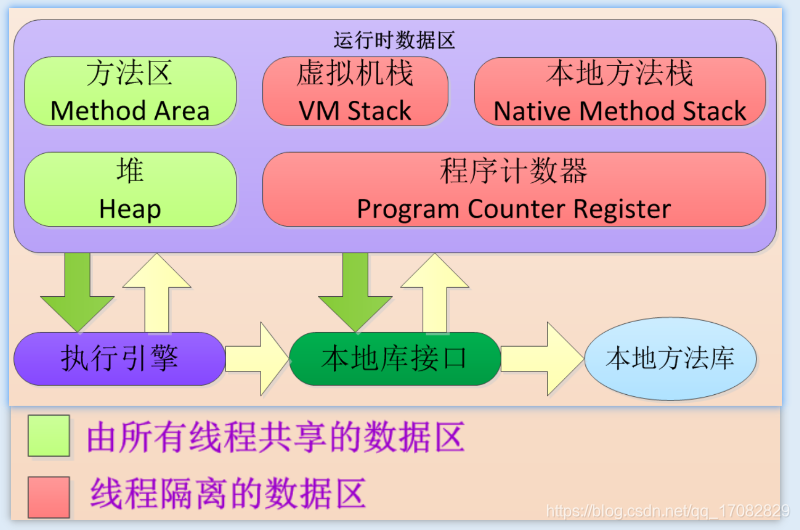
引用详细地址,说的特别好
答:
分为线程共享区和线程隔离区(独占区)
其中线程共享区有两块,一块叫做方法区,是堆的一个逻辑部分,也叫持久代或永久代,用于存储类的信息(类名、方法、字段),常量池,静态变量,编译后的代码等,另一块叫做JAVA堆,用于存储对象实例和数组,垃圾回收的主要区域!
堆里面分为新生代和老年代,新生代里面分为Eden、survivor、tenured gen。
线程隔离区有三块,包括虚拟机栈和本地方法栈,以及程序计数器,
虚拟机栈存储的单元叫栈帧,一个栈帧主要划分为局部变量表,操作数栈,指向当前方法所属的类的运行时常量池的引用,动态链接,方法的返回地址,运行的是JAVA的方法。

本地方法栈除了调用的是本地方法之外,和虚拟机栈几乎一样。
程序计数器可以认为是当前线程运行的行号指示器。由于程序计数器中存储的数据所占空间的大小不会随程序的执行而发生改变,因此,此内存区域是唯一一个在JVM规范中没有规定任何OutOfMemoryError情况的区域。
垃圾回收机制?
如何判定对象为垃圾对象?
方法一、引用计数法,每被引用一次,就+1,引用无效一次就-1,为0就回收(现JVM已弃用?因为对象之间互相有引用时,这种检测方法就失效了)
方法二、可达性分析,以虚拟机栈中的局部变量表中的所有引用作为GC Root,深度遍历堆中的所有实例(即找到引用链,不在引用链中的实例需要被回收)
如何回收?
回收策略:
1、标记-清除算法。用于老年代,两个问题:清除之后内存不连续,可能引起第二次垃圾回收产生了效率问题和空间问题。
2、复制算法。主要用于新生代,将堆中的内存划分为一大块Eden区域(80%)和两小块Survivor区域a和b(各10%),每次分配新实例对象时,都丢到Eden区域,每次垃圾回收时,将Eden区域还存活的对象实例按内存区域顺序丢到其中一块survivor区域a,另一块survivor区域b也丢进来a,下一次垃圾回收时除了Eden丢到b,a也丢到b(互相复制互相丢并清空自己),如果一块survivor区域满了,就选择性的将一些存活对象实例丢到tenured gen区域。优势:浪费内存小
3、标记整理(清除)算法。主要用于老年代,相比较标记清除算法,仅在清除对象实例之前,划分一块小空间,将小空间不需要回收的对象实例移动到大空间去,将需要清除的对象实例放进小空间一起清除,提升了效率。
4、分代收集算法,结合复制算法和标记整理算法,分新生代和老年代使用不同的策略。
垃圾回收器:
1、Serial.最古老最悠久的垃圾收集器,对于新生代(复制算法),单线程,效率高,适用于桌面应用
2、parnew。多线程收集(新生代收集器,复制算法),客户端环境下效率不如serial
3、parellel scavengen(多线程,新生代收集器,复制算法)达到可控制的吞吐量
(吞吐量=CPU用于运行用户代码的时间与CPU消耗总时间的比值)
(吞吐量=执行用户代码的时间/(执行用户代码时间+垃圾回收占用时间))
使用两个参数来控制
-XX:MaxGCPauseMillis 垃圾收集器停顿时间ms为单位
-XX:GCTimeRatio 吞吐量大小(0,100)
4、cms。并发收集器(边扔边打扫,老年代收集器),用于回收老年代内存,同时只能使用serial或parnew收集新生代,把并行线程和垃圾回收线程同时标记,同时清理,优点:并发清理,低停顿。缺点:CPU占用高,无法处理浮动垃圾(打扫完之后不管了要等下一次),空间碎片
5、G1收集器。JDK9默认指定收集器。优势:并行并发,分代收集,空间整合(类似标记整理算法),低停顿(可预测的停顿),利用多核CPU。筛选回收用了一张remeber set表记录哪些实例不会被回收。
HTTP协议
Get和POST请求有什么区别?
答:
- Get是不安全的,因为在传输过程,数据被放在请求的URL中;Post的所有操作对用户来说都是不可见的。
- Get传送的数据量较小,这主要是因为受URL长度限制;Post传送的数据量较大,一般被默认为不受限制。
- Get限制Form表单的数据集的值必须为ASCII字符;而Post支持整个ISO10646字符集。
- Get执行效率却比Post方法好。Get是form提交的默认方法。
设计模式(单点登录:一处登录多处保持登录状态)
设计模式是什么?常见的设计模式有哪些?
设计模式是经过多次实践总结出来的可以反复使用的设计方法,代表了最佳的实践,可以套用的一种模板。使用设计模式是为了重用代码、让代码更容易被他人理解、保证代码可靠性。
有23种设计模式,这些模式可以分为三大类:创建型模式(Creational Patterns)、结构型模式(Structural Patterns)、行为型模式(Behavioral Patterns)。当然,我们还会讨论另一类设计模式:J2EE 设计模式。
总体来说设计模式分为三大类:
创建型模式,共五种:工厂方法模式、抽象工厂模式、单例模式、建造者模式、原型模式。
结构型模式,共七种:适配器模式、装饰器模式、代理模式、外观模式、桥接模式、组合模式、享元模式。
行为型模式,共十一种:策略模式、模板方法模式、观察者模式、迭代子模式、责任链模式、命令模式、备忘录模式、状态模式、访问者模式、中介者模式、解释器模式。
设计模式详解
策略模式实现的一种办法
原型设计模式:Spring 配置bean时,scope 为Prototype 时,扫到该beans.xml文件,在创建bean时,getBeans方法中有个doGetBean方法中,会判断该bean是否Prototype ,是就创建原型对象,不是就正常创建。
单例模式(饱汉模式,饥汉模式)
三部曲:
一、构造方法私有化,只有自己的类中能创建实例。
二、在自己的类中创建一个单实例。(饱汉:需要时才创建。饥汉:一出来就创建)
三、提供一个方法获取该实例对象。(创建时需要进行方法同步)
例如:线程池,数据库连接池、Runtime类(饿汉模式)、defaultSingletonBeanRegistry、ReactiveAdapterRegistry双锁饱汉,proxyFactoryBean(spring)
工厂方法模式:Spring IOC容器就实现了该模式,我们只需要加好配置和注解,不关心对象如何被创建,由SpringIOC容器来管理这些对象的生命周期。
实现了工厂方法模式:tomcatUrlStreamHandleFactory
代理模式:SpringAOP就是实现了代理模式。
SpringBoot
SpringBoot有几种配置文件?
properties和yaml文件,yaml文件是一种简洁的非标记的语言,它的配置内容比较结构化。
SpringBoot的优势?
答:配置很少,可以独立运行,内置tomcat,不需要打war包部署到容器
SpringBoot的核心注解?
SpringBootApplication ->EnableAutoConfiguration->Import(AutoConfigurationImportSelector.class)(读取spring.factories文件,过滤无用的)
@ComponentScan
@Configuration
ConfigurationProperties可以读取配置文件的内容
SpringBoot如何做到bean管理?
答:通过springIOC管理->beanFactory
SpringBoot这些注解之间有何区别?
答:四个元注解,以及各注解的作用
MySQL
MySQL如何优化?
mysql详细优化
答:
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by涉及的列上建立索引。应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,可以用union all
2.少用left join
3、灵活使用exsit和in
4、表结构优化,比如尽量使用varchar不用char,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
5. 什么情况下设置了索引但无法使用 ?
① 以“%”开头的LIKE语句,模糊匹配
② OR语句前后没有同时使用索引
③ 数据类型出现隐式转化(如varchar不加单引号的话可能会自动转换为int型)
4、数据频繁删减导致索引失效,所以要尽量保留冗余数据
数据库优化方案
① SQL语句及索引的优化
② 数据库表结构的优化
③ 系统配置的优化
④ 硬件的优化
选取最适用的字段属性,尽可能减少定义字段宽度,尽量把字段设置NOTNULL,例如’省份’、'性别’最好适用ENUM
· 使用连接(JOIN)来代替子查询
· 适用联合(UNION)来代替手动创建的临时表
· 事务处理
· 锁定表、优化事务处理
· 适用外键,优化锁定表
· 建立索引
MyBatis
什么是mybatis?
数据持久层的一个开源框架。
为什么需要持久化?垃圾问题,内存太贵
为什么需要mybatis?
传统的jdbc太麻烦了,为了简化持久层开发。框架能自动化很多东西。
Mybatis的优点:
1、简单易学。
2、灵活。
3、sql和代码的分离,提高了可维护性。
4、提供映射标签,支持对象与数据库的orm字段关系映射
5、提供对象关系映射标签,支持对象关系组建维护
6、提供xml标签,支持编写动态sql。
Docker
Session和Cookie的区别
都是会话跟踪技术。
session的实现依赖于cookie,sessionId(session的唯一标识)需要存放在客户端
session存在服务器,cookie存在客户端。
session安全,cookie不安全(本地可以进行cookie欺骗)
session存太多,为了减轻服务器性能,重要的放在session,其他的放在cookie
单个cookie保存不能超过4k,而许多浏览器限制单个网站不超过20个cookie
CMM/CMMI的基本概念
"CMM是指“能力成熟度模型”,其英文全称为Capability Maturity Model for Software,英文缩写为SW-CMM,简称CMM。
它是对于软件组织在定义、实施、度量、控制和改善其软件过程的实践中各个发展阶段的描述。
CMM的核心是把软件开发视为一个过程,并根据这一原则对软件开发和维护进行过程监控和研究,以使其更加科学化、标准化、使企业能够更好地实现商业目标。
CMMI认证是由美国软件工程学会(software engineering institue,简称SEI)制定的一套专门针对软件产品的质量管理和质量保证标准.
CMMI 的全称为:Capability Maturity Model Integration,即能力成熟度模型集成。
敏捷开发经验?
使用过JIRA
