在上一篇文章 数据分析利器 pandas 系列教程(一):从 Series 说起 中:详细介绍了 pandas 基础数据结构 Series,今天说说另一种数据结构 DataFrame。

dataframe 是表格型的数据结构,由一组有序的列组成,可以看成是由 Series 组成的字典,举个例子:
| / | name | sex | course | grade |
|---|---|---|---|---|
| 0 | Bob | male | math | 99 |
| 1 | Alice | female | english | 92 |
| 2 | Joe | male | chinese | 89 |
| 3 | Bob | male | chinese | 88 |
| 4 | Alice | female | chinese | 95 |
| 5 | Joe | male | english | 93 |
| 6 | Bob | male | english | 95 |
| 7 | Alice | female | math | 79 |
| 8 | Joe | male | math | 89 |
创建 dataframe 的常见方式
同 series 一样,dataframe 也有 index,不同的是,series 除了 index,只有一列,而 dataframe 通常有很多列,比如上面的 dataframe 就有四列,而且都有名字:name、sex、course、grade,通过这些名字,可以索引到某一列,这些名字称为列(索引),因此,在 dataframe,我更愿意将 index 称为行索引,以此和列索引区分开。
创建 dataframe 其实有 N 种方法,没必要一一掌握,毕竟常用的不过两三种,我也不打算把所有的创建方式都说一遍,那样有炫技的嫌疑,按照自己的理解,我把这些创建方式统一分为两大类:按列的方式创建、按行的方式创建,只讲这两大类下各自最具代表性的创建方式。
以创建上面那个 dataframe 为例,后同。
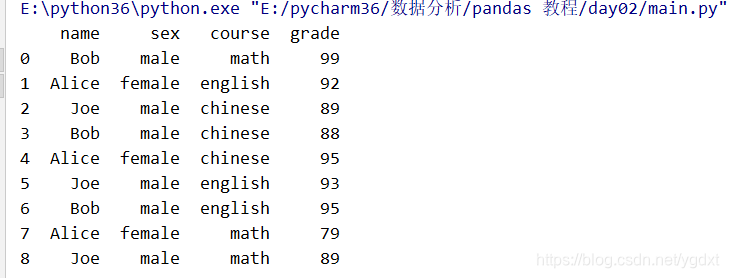
通过列创建
import pandas as pd
#没有设置行索引 index,取默认值
df = pd.DataFrame({'name':['Bob','Alice','Joe']*3,
'sex':['male','female','male']*3,
'course':['math','english','chinese','chinese','chinese','english','english','math','math'],
'grade':[99,92,89,88,95,93,95,79,89]})
print(df)
通过行创建
data = [['Bob','male','math',99],
['Alice','female','english',92],
['Joe','male','chinese',89],
['Bob','male','chinese',88],
['Alice','female','chinese',95],
['Joe','male','english',93],
['Bob','male','english',95],
['Alice','female','math',79],
['Joe','male','math',89]]
columns = ['name','sex','course','grade']
df = pd.DataFrame(data=data,columns=columns)
print(df)
打印结果同上。
dataframe 的基本属性和整体描述
| 属性 | 含义 |
|---|---|
| df.shape | df 的行数、列数 |
| df.index | df 的行索引 |
| df.columns | df 的列索引(名称) |
| df.dtypes | df 各列数据类型 |
| df.valuse | df 对象值,是一个二维 ndarray 数组 |
print(df.shape,'\n')
print(df.index,'\n')
print(df.columns,'\n')
print(df.dtypes,'\n')
print(df.values,'\n')

注意各列的数据类型,由于 pandas 可以自己推断数据类型,因此 grade 为 64 位 int 型而不是 object 类型。
| 函数 | 作用 |
|---|---|
| df.head() | 打印前面 n 行,默认 5 行 |
| df.tail() | 打印后面 n 行,默认 5 行 |
| df.info() | 打印行数、列数、列索引、列非空值个数等整体概览信息 |
| df.describe() | 打印计数、均值、方差、最小值、四分位数、最大值等整体描述信息 |
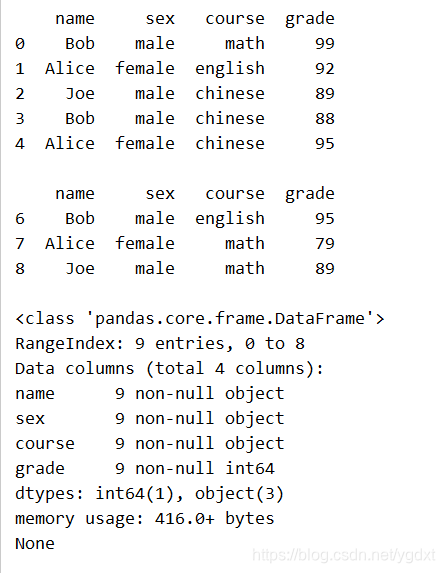
print(df.head(),'\n')
print(df.tail(3),'\n')
print(df.info(),'\n')
print(df.describe(),'\n')

dataframe 查询
loc[] 和 iloc[]
看过 数据分析利器 pandas 系列教程(一):从 Series 说起 的读者应该知道,iloc[] 的 i 是 integer 的意思,意味着 iloc[] 只能通过位置查询,而 loc[] 可以通过行、列索引查询;类似地,这两个函数既可以查询,也可以新增、修改。
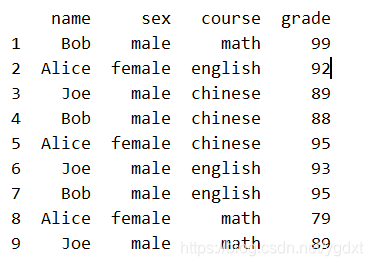
为体现差异,我们先把行索引从 0-8 变换为 1-9(均指前闭后闭区间,而 range() 是前闭后开区间):
df.index = range(1,10)
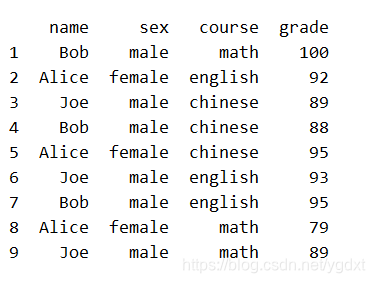
假定我们要完成一个任务:把 Bob 的 math 成绩改成 100。
用 loc[] 完成如下:
df.loc[1,'grade'] = 100
print(df,'\n')
而用 iloc[],对应的代码如下:
df.iloc[0,3] = 100
print(df,'\n')
iloc[] 是根据位置查询的,和行索引、列索引没有一点儿关系,这也是我为什么事先修改行索引的缘故,方便对比iloc[]和loc[]的第一个参数信息。
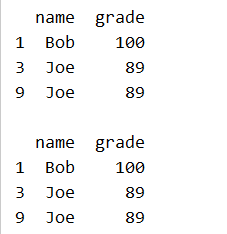
这两次查询都是 点查询,其实 loc[] 和 iloc[] 也支持 块查询,示例代码如下:
print(df.loc[[1,3,9],['name','grade']],'\n')
print(df.iloc[[0,2,8],[0,3]])
遍历查询
for index,row in df.iterrows():
print(index,': ',row['name'],row['sex'],row['course'],row['grade'])

与 Series 的关系
通过 series 可以创建 dataframe:
names = pd.Series(['Bob','Alice','Joe']*3)
sexs = pd.Series(['male','female','male']*3)
courses = pd.Series(['math','english','chinese','chinese','chinese','english','english','math','math'])
grades = pd.Series([99,92,89,88,95,93,95,79,89])
df = pd.DataFrame({'name':names,'sex':sexs,'course':courses,'grade':grades})
打印结果就是文章开头那个 dataframe,这种创建方式可以划分到 按列的方式创建,不过没有上面所讲的那种方式常用。
而 dataframe 可以通过 df[列名] 的方式得到 series:
print(df['name'],type(df['name']),'\n')
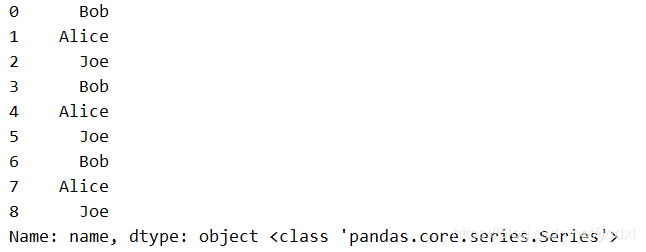
于是乎,所有对 series 的操作,适用于 df['name']:
print(df['name'].values,type(df['name'].values),'\n')
print(df['name'].unique(),type(df['name'].unique()),'\n')

这里我纠正一下我上篇文章中的错误之处:series.values 或 series.unique() 返回的并不是列表,虽然打印结果像列表(因为对 __str__()函数进行了重载),但实际上却是 ndarray 对象,一种类似列表的数组,可以通过 .tolist() 转为列表。
print(df['name'].values.tolist(),type(df['name'].values.tolist()),'\n')
print(df['name'].unique().tolist(),type(df['name'].unique().tolist()),'\n')

series 上次漏说了一个重要的操作 apply():对列上的数据作处理,它可以使用 lambda 表达式作为参数,也可以使用已定义函数的函数名称(不需要带上())作为参数,比如我们让每个人的每门课成绩加减 10 分:
# lambda 表达式适用于比较简单的处理
df['grade'] = df['grade'].apply(lambda x:x-10)
print(df,'\n')
# 定义函数适用于比较复杂的处理,这里仅作示例
def operate(x):
return x+10
df['grade'] = df['grade'].apply(operate)
print(df)
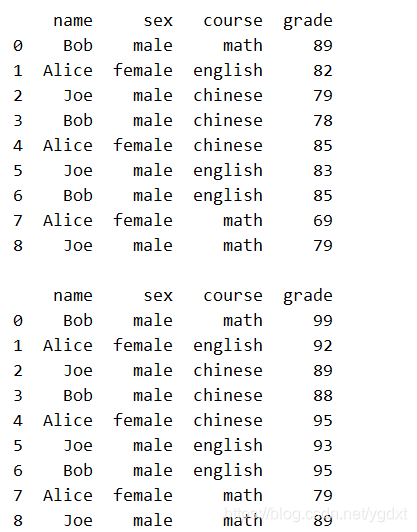
注意 apply() 函数是有返回值的,并且是要用 df['grade'] 接收而不是 df,否则整个 dataframe 只会剩下 grade 这一列。
新增删除行或列
新增/删除行或列方法不甚枚举,这里我抛砖引玉只说几种常用的。
删除行/列通过 drop() 函数即可完成:
# drop() 的第一个参数是行索引或者列索引
# axis = 0 删除行
df.drop([0,7,8],axis=0,inplace=True) # 删除所有人的数学成绩
# axis = 0 删除列
df.drop(['sex'],axis=1,inplace=True) # 删除所有人的性别信息
print(df)
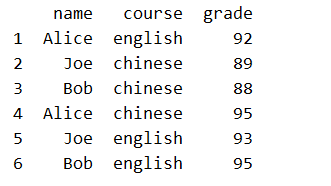
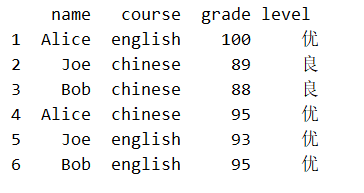
和 series 一样,新增一行可用 set_value(),at[],loc[],如果行索引存在,则是修改,否则就是新增;下面三行代码,每一行的效果相同,都是修改了 Alice 的 english 成绩 为 100:
# 不一定非得要列表,只要是可迭代对象即可
df.loc[1] = ['Alice', 'english', 100]
df.at[1] = ['Alice', 'english', 100]
# set_value 会在将来被舍弃
df.set_value(1, df.columns, ['Alice', 'english', 100], takeable=False)
新增一列可以通过 df[列名]=可迭代对象 或者 df[:,列名]=可迭代对象 实现,来个任务驱动,比如新增一列成绩等级,60 分以下为不及格,60-89 为良,90-100 为优:
level = []
for grade in df['grade'].values.tolist():
if grade<60:
level.append('不及格')
elif grade>=60 and grade<90:
level.append('良')
else:
level.append('优')
df['level'] = level
print(df)
至此,pandas 中两种基本数据结构说完了,下一篇来谈谈 pandas 中各种读写文件函数的坑。
