1、万物皆字节
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一 样如此。所以,字节流可以传输任意文件数据。在操作流的时候,我们要时刻明确,无论使用什么样的流对象,底层传输的始终为二进制数据。就是汉子也不例外,在存储时也是一个个的字节。既然都是字节,为什么还会产生乱码呢?
2、字节和字符
字节: 一个字节(byte)等于八个位(bit),相当于八个开关。
字符: Java规定了字符的内码要用UTF-16编码,所以1个字符=2个字节。但我们通常采用UTF-8的编码格式,UTF-8编码是变长编码,通常汉字占三个字节,扩展B区以后的汉字占四个字节。由于UTF-8特点的编码方式,读取文件时可以判断一个字符占多少字节,从而保证数据的读取完整。因此,一个字符等于多少字节,是由编码方式决定的。
重点来了,系统在读取文件时,是怎么判断多少字节是一个字符呢?请看下图!系统在从开头扫描字节,从开端的0-1数字就能判断这个字要读取多少字节。
所以就得出了结论,使用字节流操作中文不一定会乱码!只是看你处理的方式!

3、何时不会乱码 – 写完再读
当你以字节流方式读取一个文件时,不间断地写入一个文件,此时就不会乱码。因为你只是将一串0-1数字复制进另一个文件,并不涉及中途读取的情况,等你把所有的中文的字节流写进去,此时系统读取仍会转化为一个一个的汉字。
准备工作:
import java.io.File;
import java.io.FileOutputStream;
/**
* @author RuiMing Lin
* @date 2020-03-13 22:09
*/
public class Demo3 {
public static void main(String[] args) throws Exception{
File fis = new File("fis.txt");
fis.createNewFile(); // 创建一个空文件 fis.txt
File fos = new File("fos.txt");
fos.createNewFile(); // 创建一个空文件 fos.txt
FileOutputStream fileOutputStream = new FileOutputStream(fis);
fileOutputStream.write("我爱你,中国!".getBytes()); // 向fis.txt写入 “我爱你,中国”
fileOutputStream.close();
}
}
写入fos.txt文件:
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
/**
* @author RuiMing Lin
* @date 2020-03-13 22:09
*/
public class Demo3 {
public static void main(String[] args) throws Exception{
FileInputStream fileInputStream = new FileInputStream("fis.txt");
FileOutputStream fileOutputStream = new FileOutputStream("fos.txt");
int len;
while ((len = fileInputStream.read())!= -1){
fileOutputStream.write(len); // 一次写入一个字节,或者一次写入多个字节也可以
}
fileInputStream.close();
fileOutputStream.close();
}
}
结果输出:
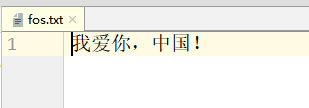
4、何时会乱码 – 边写边读
当你以字节流边读取边使用的话,就很有可能发生乱码!
import java.io.FileInputStream;
/**
* @author RuiMing Lin
* @date 2020-03-13 22:21
*/
public class Demo4 {
public static void main(String[] args) throws Exception{
FileInputStream fileInputStream = new FileInputStream("fis.txt");
int len;
byte[] bytes = new byte[3]; //假设一个汉字占3个字节
while ((len = fileInputStream.read(bytes)) != -1){
System.out.print(new String(bytes,"utf-8")); //使用print,不进行换行
}
fileInputStream.close();
}
}
结果输出:
我爱你,中国!
咋一看好像不会乱码!这是因为“我爱你,中国!”中每一个字和标点符号都是三个字节的,因此不会乱码!
当我们把“我爱你,中国!”改为“China,我爱你!”,看看此时的结果:

5、字符流为什么不会乱码
从上面的utf-8编码方式可以知道,字符流读取一串0-1数字时,会根据前面几位判断要读取几个字节,当发现时1110**** 10****** 10******时,就会读取3个字节就立马刹住不读取,此时读取内容为一个汉字。
有错误的地方敬请指出!觉得写得可以的话麻烦给个赞!欢迎大家评论区或者私信交流!
