文章目录
windows虚拟机中配置Hadoop Hive(二)
完全分布式:Hadoop守护进程运行在一个集群上
伪分布式:在单节点集群上运行Hadoop,其中所有的守护进程都运行在同一台机器上.对机器的消耗更小一点.
一 利用Xftp将软件包上传到Linux中
我们不要用root用户登录,使用Hadoop用户登录,将软件传输到Hadoop的目录下:
在xshell 中 检查一下是否有这几个软件:
二 配制免密登录
免密码登录的原因:如果集群不是伪分布式的,那么在存文件的时候,有多份,比如存了三份,那么在下载的时候他会从不同的块下载,你要下载node101的文件,需要先进入才能下载.如果不配置免密登录,需要先输入密码,三个结点的话每次输密码我可以接受,但是如果3个文件10000个块,块在不同的机器上,你要输入这么多密码,心里是不是很崩溃.
- 1 切换到root用户:
su - root - 2 关闭selinux:
vim /etc/selinux/config按i进入插入模式,SELINUX=disabled
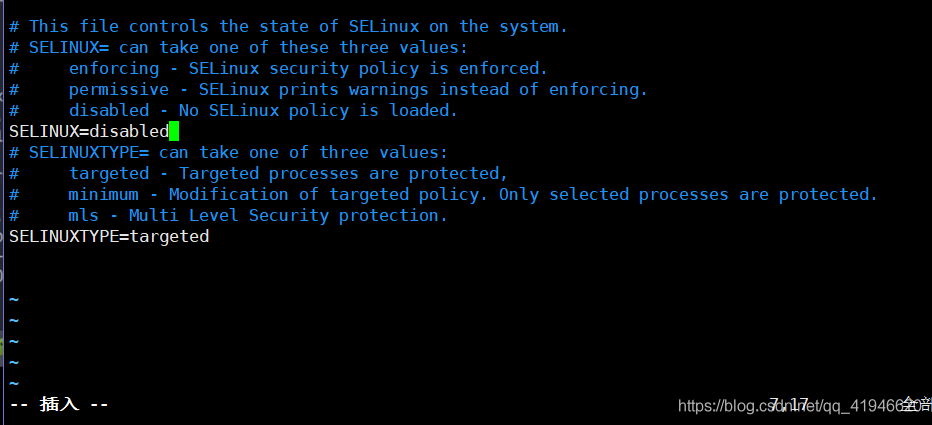
esc :wq 保存并退出.clear清屏
- 3 切换到Hadoop用户:
su - hadoop - 4 进入Hadoop的家目录:
cd
进入Hadoop家目录后,输入下面的命令:
注:ssh的意思登录到其他机器的意思,我现在是node100,要登录到101,在一个集群上是可以登录的,登录后相当于可以进入另一台电脑上了.
ssh-keygen -t rsa[输入完后连按4个回车]
ssh node100[yes,输入hadoop用户的密码]
ssh-copy-id node100[输入hadoop用户的密码]
检查是否成功:ssh node100 不需要密码即可登录
三 解压软件包到/opt/module
先切换到root,在opt里面创建一个文件夹module:
在root用户下切换到opt文件夹:cd /opt/
创建module文件夹:mkdir module
更改所有者和所有组给Hadoop:
chgrp hadoop module/
chown hadoop module/
回到的家目录开始解压:
cd
tar -zxvf ./jdk-8u181-linux-x64.tar.gz -C /opt/module/
tar -zxvf ./hadoop-2.7.3.tar.gz -C /opt/module/
tar -zxvf ./apache-hive-3.1.1-bin.tar.gz -C /opt/module/
四 编辑环境变量:
cd 进入家目录,这个.bash_profile是一个隐藏文件
vim ~/.bash_profile

在文件末尾(光标移到最后一行,按一个小写的o)添加
JAVA_HOME=/opt/module/jdk1.8.0_181
HADOOP_HOME=/opt/module/hadoop-2.7.3
HIVE_HOME=/opt/module/apache-hive-3.1.1-bin
PATH=
HOME/bin:
HADOOP_HOME/bin:
HIVE_HOME/bin
export JAVA_HOME
export HADOOP_HOME
export HIVE_HOME
export PATH

esc :wq
五 重新加载该文件 使环境变量生效
在Hadoop家目录
source ~/.bash_profile
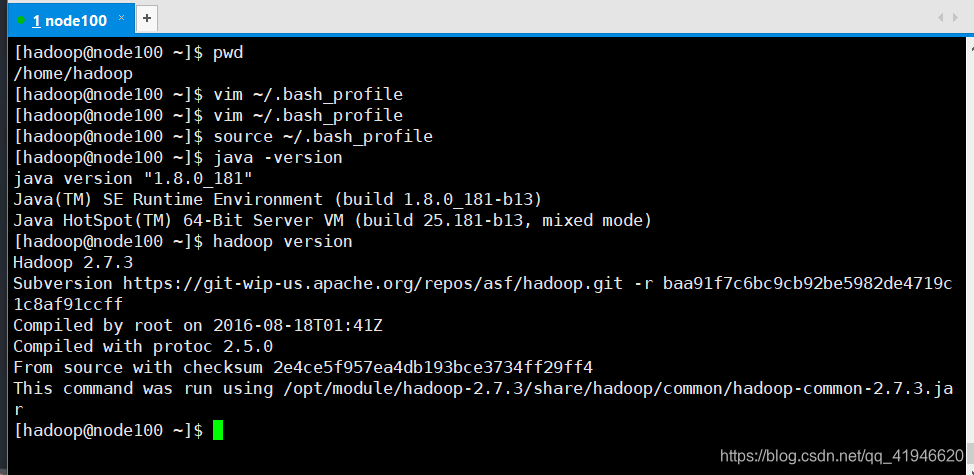
验证是否正确:
java -version
hadoop version
六 修改hadoop的配置文件:
在Hadoop用户下:
cd /opt/module/hadoop-2.7.3/etc/hadoop

etc是存放配置文件的.我们进入etc看看:

有一个Hadoop文件,进去:
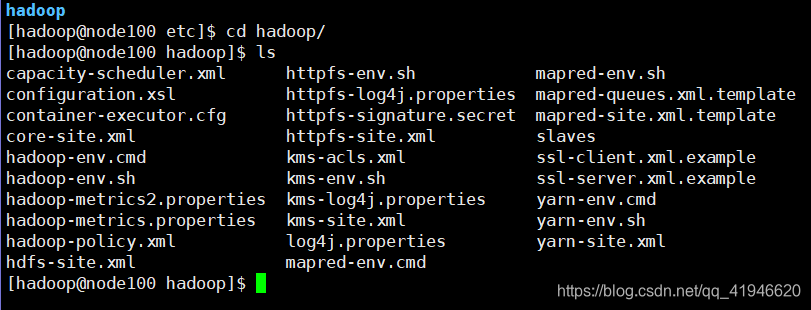
我们需要修改其中的几个:复制粘贴以下命令
1.vim ./hadoop-env.sh
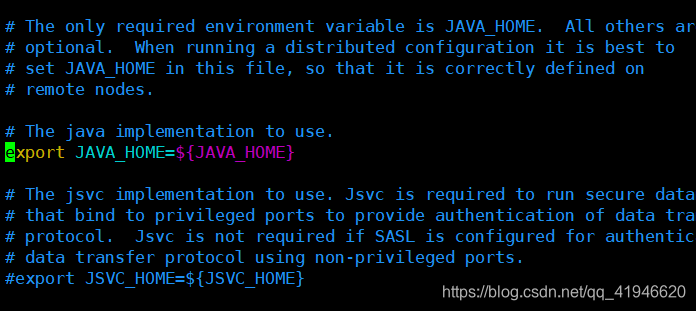
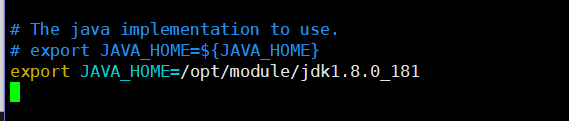
将光标地方的代码修改(或者注释)如下:注意jdk1.8.0_181要与你的版本对应,解压后的文件名!
export JAVA_HOME=/opt/module/jdk1.8.0_181
:wq
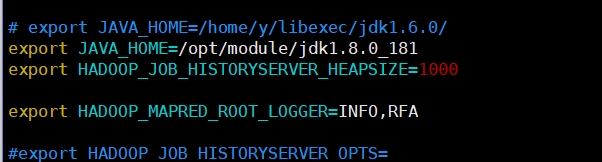
2.vim ./mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
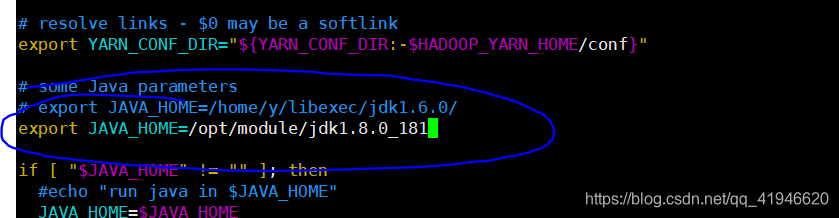
3.vim ./yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_181
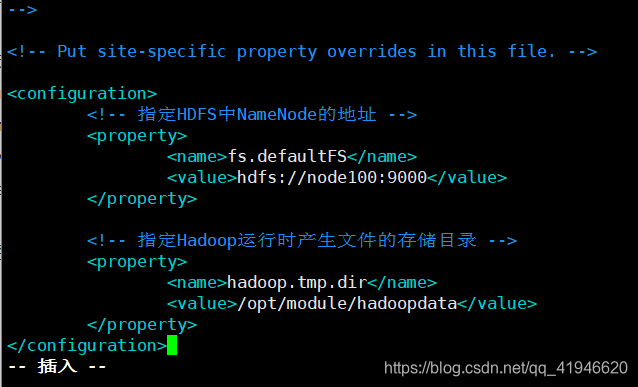
4.vim ./core-site.xml
在倒数第一行和倒数第二行中间, 按一个o键

<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node100:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoopdata</value>
</property>
复制粘贴,空白也要复制,中间的Node100要根据自己的机器名字更改:
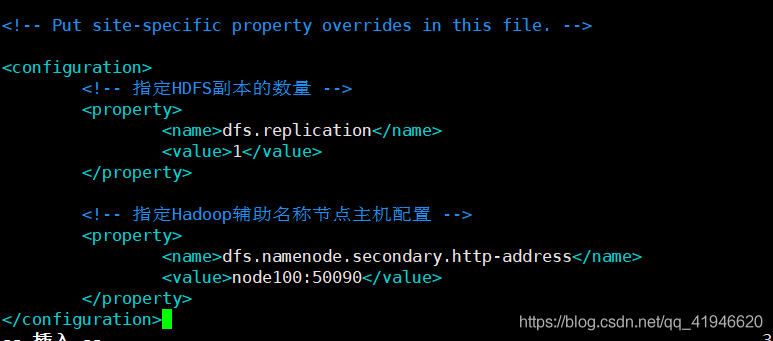
5.vim ./hdfs-site.xml
<!-- 指定HDFS副本的数量 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node100:50090</value>
</property>
6.cp ./mapred-site.xml.template ./mapred-site.xml
先复制过去,然后编辑复制后的文件

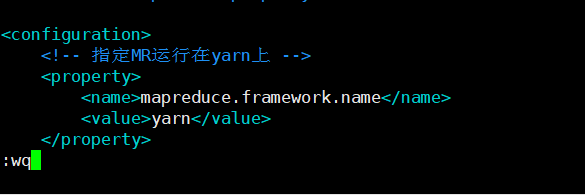
vim ./mapred-site.xml (z注意一定要先在指定位置上按i才能编辑)
<!-- 指定MR运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
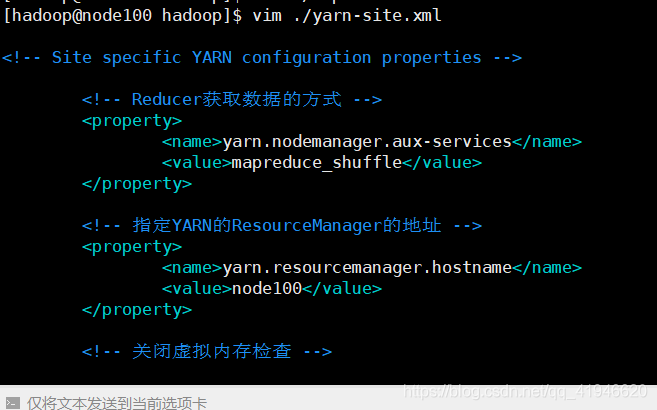
7.vim ./yarn-site.xml
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node100</value>
</property>
<!-- 关闭虚拟内存检查 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
8.vim ./slaves
删除(正常模式下小写dd)localhost,改为node100
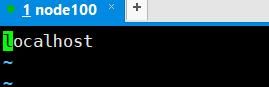
node100
九、格式化hadoop集群
注意:这个命令只能格式化一次,再一次格式化就会出问题了!
在node100这台机器上执行:hdfs namenode -format
格式化好后就可以启动或者关闭Hadoop集群了
十、启动/关闭hadoop集群
在node100这台机器上执行启动:start-all.sh
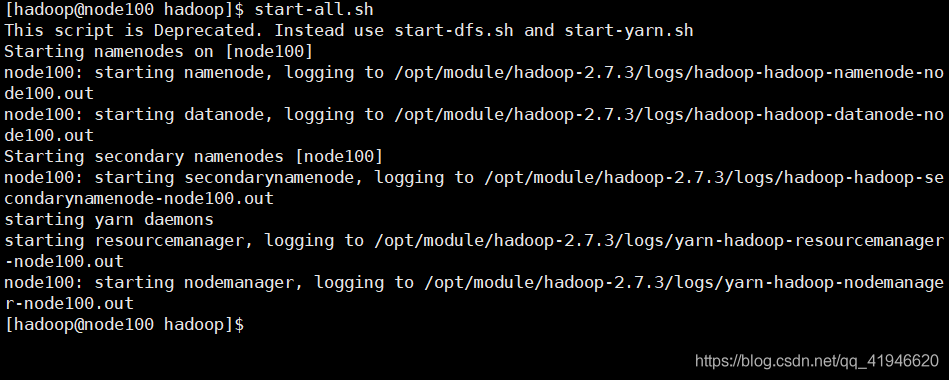
查看是否成功运行: jps
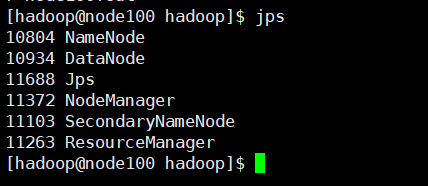
一共6个进程,多一个少一个都不行
在node100这台机器上执行关闭:stop-all.sh
十一、验证集群
- 验证页面是否正常:在自己电脑的浏览器里输入如下地址:IP地址可在终端ifconfig找到
192.168.5.100:50070
192.168.5.100:8088
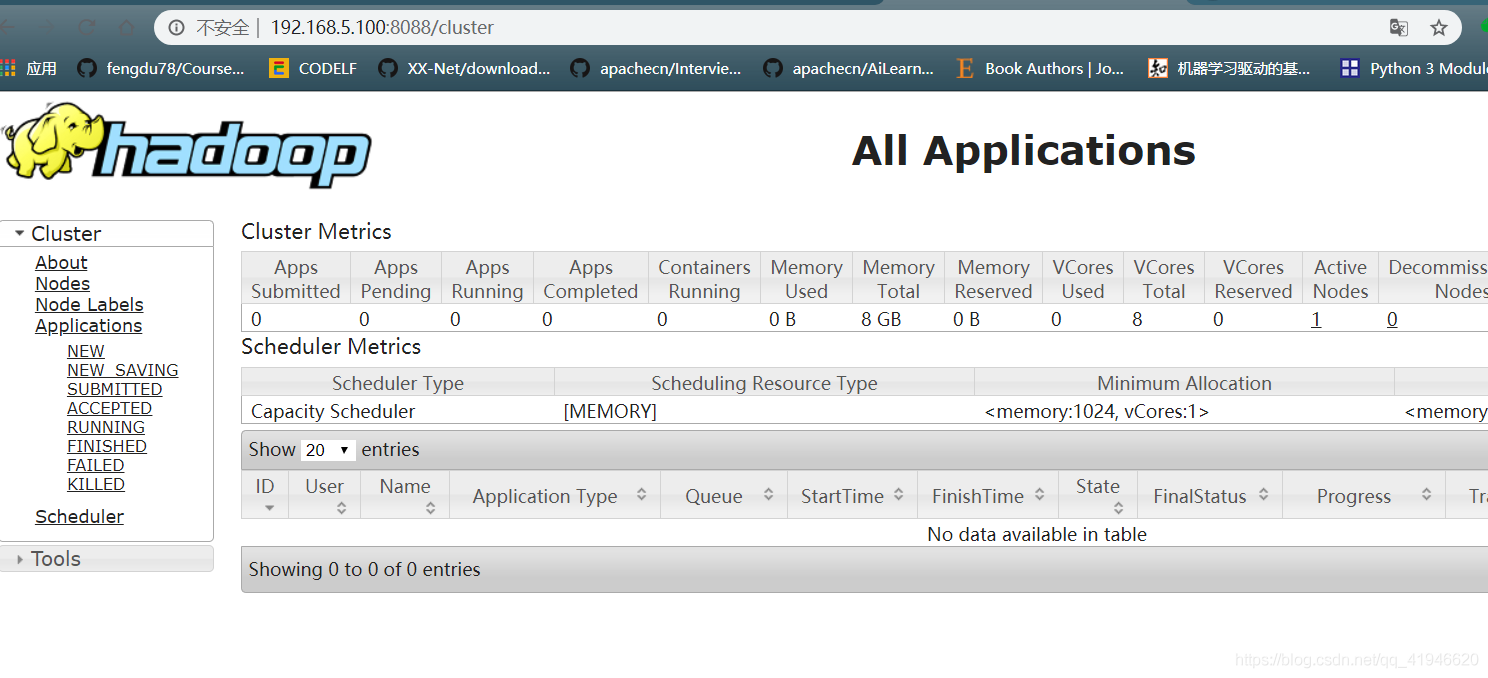
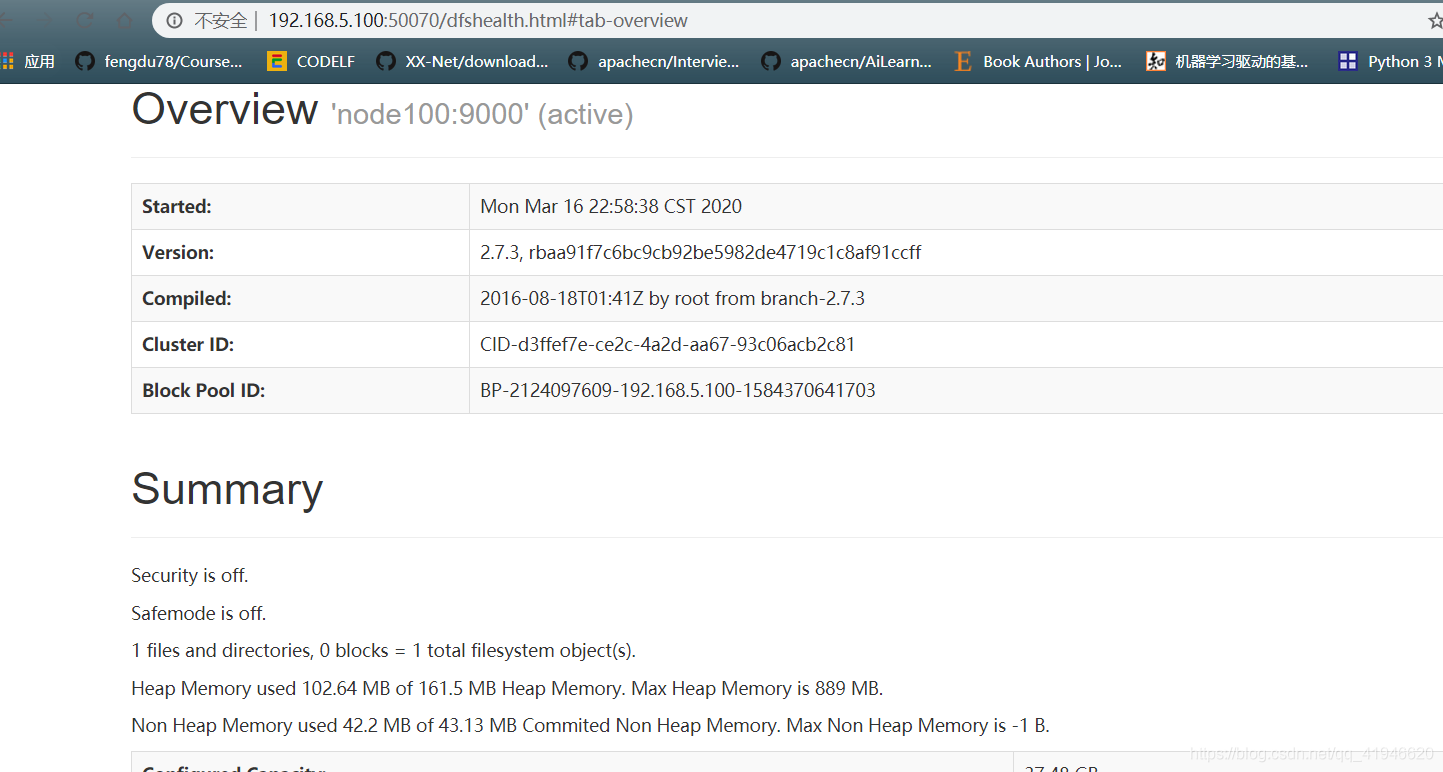
如果页面显示不出来可能是防火墙没有关闭:
关闭防火墙的方法:切换到root用户,
systemctl stop firewalld.service
systemctl disable firewalld.service
十二、Hadoop的wordcount
跑一下任务吧,在Hadoop的家目录中创建一个文件
1.vim word.txt
编写:
hello python
hello java
hello scala
hello world
welcome to beijing
:wq保存
2.wordcount测试
在集群上创建一个文件夹:
hadoop fs -mkdir /test
在browse the file system访问文件系统
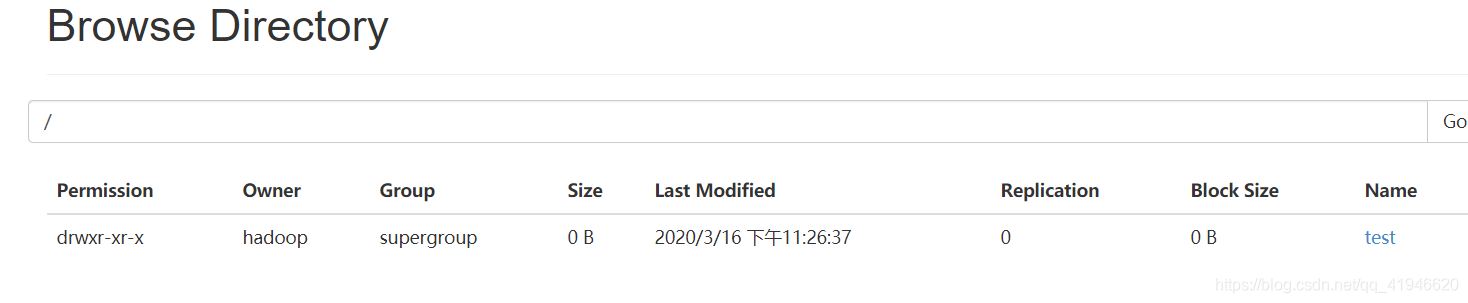
将之前创建的world,txt复制到test中(在家目录执行)
hadoop fs -put ./word.txt /test


执行(统计上个文件中每个单词出现的次数):
hadoop jar /opt/module/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /test/word.txt /output
验证(出现结果):
hadoop fs -cat /output/part-r-00000
十三、Hive的安装
hive --version
开始安装:
在hdfs上创建hive数据存放目录
hadoop fs -mkdir /tmp # tmp目录其实已经存在了,在刚刚跑任务的时候就已经出现了
hadoop fs -mkdir -p /user/hive/warehouse
#给予权限
hadoop fs -chmod g+w /tmp
hadoop fs -chmod g+w /user/hive/warehouse
在hive的软件目录下执行初始化命令
进入hive目录: cd /opt/module/apache-hive-3.1.1-bin/
bin/schematool -dbType derby -initSchema
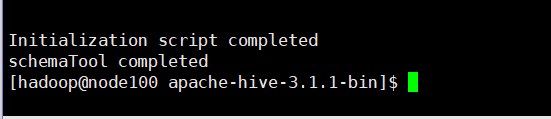
初始化成功后就会在hive的安装目录下生成derby.log日志文件和metastore_db元数据库
启动hive:在apach目录下输入 bin/hive (必须在这个目录下启动)
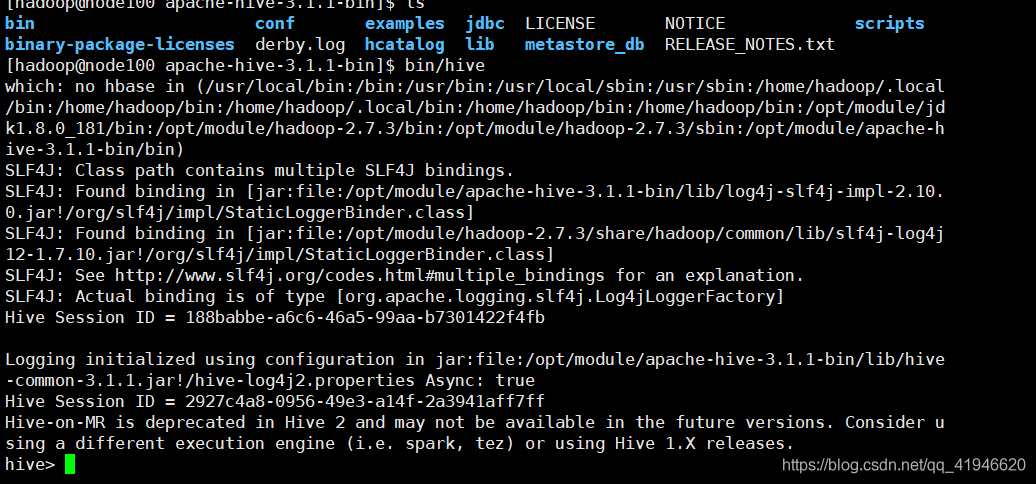
查看数据库:show databases;
验证成功,不要执行其他命令:退出来 quit;
注意:离开hadoop安全模式 hadoop dfsadmin -safemode leave(因为有时候会提示你你的集群处于安全模式下,如果你在安全模式下就执行这一句话)
MapReduce是一种传统的面向批量任务的处理框架。像Tez这样的新处理引擎越来越倾向于近实时的查询访问。随着Yarn的出现,HDFS正日益成为一个多租户环境,允许很多数据访问模式,例如批量访问、实时访问和交互访问。
