文章目录
- 1. hive概述
- 1.1. 简介
- 1.2. 为什么要使用hive
- 1.3. hive的特点
- 1.4. [架构](https://blog.csdn.net/u013595419/article/details/79632928)
- 1.5. hive的基本操作
- 1.6. hive的数据存储
- 2. hive的安装部署
- 2.1. [hive为什么要启用Metastore?](https://blog.csdn.net/qq_35440040/article/details/82462269)
- 2.2. [hive集群搭建(主要留意配置文件)](https://blog.csdn.net/yangang1223/article/details/80183038)
- 3. hive的基本操作
- 4. hive的集合类型
- 5. hive 严格模式
- 6. hive Shell 参数
- 7. hive函数
- 8. Hive 实战--累计报表(面试套路)
- 9. 好学而不勤问非真好学者
1. hive概述
1.1. 简介
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。- 主要用途:
用来做离线数据分析,比直接用mapreduce开发效率更高。
1.2. 为什么要使用hive
- 操作接口采用类SQL语法,提供快速开发的能力,避免了去写MapReduce,减少开发人员的学习成本,功能扩展很方便。
1.3. hive的特点
可扩展– hive可以自由的扩展集群的规模,一般情况下不需要重启服务。延展性– hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。容错– 良好的容错性,节点出现问题SQL仍可完成执行。
1.4. 架构
1.5. hive的基本操作
1.6. hive的数据存储
- Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可支持Text,SequenceFile,ParquetFile,RCFILE等)SequenceFile是hadoop中的一种文件格式:文件内容是以序列化的kv对象来组织的
- 只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符,Hive 就可以解析数据
- Hive 中包含以下数据模型:
DB、Table,External Table,Partition,Bucketdb:在hdfs中表现为${hive.metastore.warehouse.dir}目录下一个文件夹table:在hdfs中表现所属db目录下一个文件夹external table:与table类似,不过其数据存放位置可以在任意指定路径partition:在hdfs中表现为table目录下的子目录 注意这里分区的概念bucket:在hdfs中表现为同一个表目录下根据hash散列之后的多个文件
2. hive的安装部署
- 解压
修改配置文件百度云提取码;rbnz- 加载驱动包
- 安装hive和mysq/postgresql完成后,将mysql/postgresql的连接jar包拷贝到$HIVE_HOME/lib目录下
- Jline包版本不一致的问题,需要拷贝hive的lib目录中jline.2.12.jar的jar包替换掉hadoop中的 /home/hadoop/app/hadoop-2.6.4/share/hadoop/yarn/lib/jline-0.9.94.jar
2.1. hive为什么要启用Metastore?
2.2. hive集群搭建(主要留意配置文件)
3. hive的基本操作
3.1. 数据定义语言DDL
-
创建表

-
具体实例

-
修改表

3.2. 数据操纵语言DML
- Load操作

- Insert(将查询的结果插入hive表)

- 导出数据

3.3. 数据查询语言DQL

3.4. 桶表的相关案例
-
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。Hive也是 针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
-
把表(或者分区)组织成桶(Bucket)有两个理由:
- 获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
- 使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一小部分数据上试运行查询,会带来很多方便。
-
多表关联应用

-
桶表抽样查询
 扫描二维码关注公众号,回复: 9916534 查看本文章
扫描二维码关注公众号,回复: 9916534 查看本文章
-
Hive 区分cluster by、distribute by + sort by、order by以及创建表带有clustered by和sort by
3.5. Hive join(只支持等值链接,和sql用法类似)

4. hive的集合类型
集合类型主要包括:array,map,struct等,hive的特性支持集合类型,这特性是关系型数据库所不支持的,利用好集合类型可以有效提升SQL的查询速率.

5. hive 严格模式
hive提供了一个严格模式,可以防止用户执行那些可能产生意想不到的不好的效果的查询。即某些查询在严格模式下无法执行。通过设置hive.mapred.mode的值为strict,可以禁止3中类型的查询。

6. hive Shell 参数
6.1. hive命令行

6.2. hive参数配置方式

7. hive函数
7.1. 内置函数
- Hive官方文档
- 测试各种内置函数的快捷方法

7.2. hive自定义函数和Transform

8. Hive 实战–累计报表(面试套路)
- 要求输出每个客户在每个月的总访问次数,以及在当前月份之前所有月份的累计访问次数
- 创建表
create table t_access_times(username string,month string,salary int) row format delimited fields terminated by ‘,’; - 加载数据
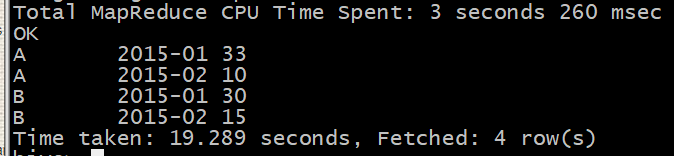
load data local inpath ‘/root/hivedata/t_access_times.dat’ into table t_access_times;A,2015-01,5 A,2015-01,15 B,2015-01,5 A,2015-01,8 B,2015-01,25 A,2015-01,5 A,2015-02,4 A,2015-02,6 B,2015-02,10 B,2015-02,5- 第一步,先求个用户的月访问次数
select username, month, sum(count) as count from t_access_time group by username, month;
- 第二步,将月总访问表 自己连接 自己
select A.,B. FROM
(select username,month,sum(count) as count from t_access_time group by username,month) A
inner join
(select username,month,sum(count) as count from t_access_time group by username,month) B
on
A.username=B.username
where B.month <= A.month

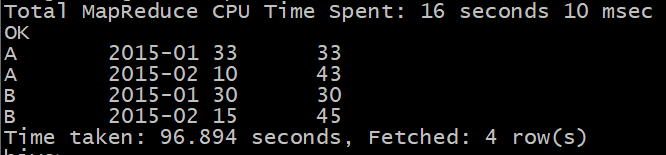
- 第三步,从上一步的结果中
进行分组查询,分组的字段是a.username a.month求月累计值: 将b.month <= a.month的所有b.salary求和即可
select A.username,A.month,max(A.count) as count,sum(B.count) as accumulate
from
(select username,month,sum(count) as count from t_access_time group by username,month) A
inner join
(select username,month,sum(count) as count from t_access_time group by username,month) B
on
A.username=B.username
where B.month <= A.month
group by A.username,A.month
order by A.username,A.month;
- 第一步,先求个用户的月访问次数
