Audio System 一 之 音频基础知识
Google Pixel、Pixel XL 内核代码(Kernel-3.18):Kernel source for Pixel and Pixel XL - GitHub
AOSP 源码(Android 7.1.2):Android 系统全套源代码分享 (更新到 8.1.0_r1)
一、音频基础知识
理解音频的一些基础知识,对于我们分析整个音频系统是大有裨益的。
它可以让我们从实现的层面去思考,音频系统的目的是什么,然后才是怎么样去完成这个目的。
声音有哪些重要属性呢?
-
响度(Loudness)
响度就是人类可以感知到的各种声音的大小,也就是音量。响度与声波的振幅有直接关系。
-
音调(Pitch)
音调与声音的频率有关系,当声音的频率越大时,人耳所感知到的音调就越高,否则就越低。
-
音色(Quality)
同一种乐器,使用不同的材质来制作,所表现出来的音色效果是不一样的,这是由物体本身的结构特性所决定的。
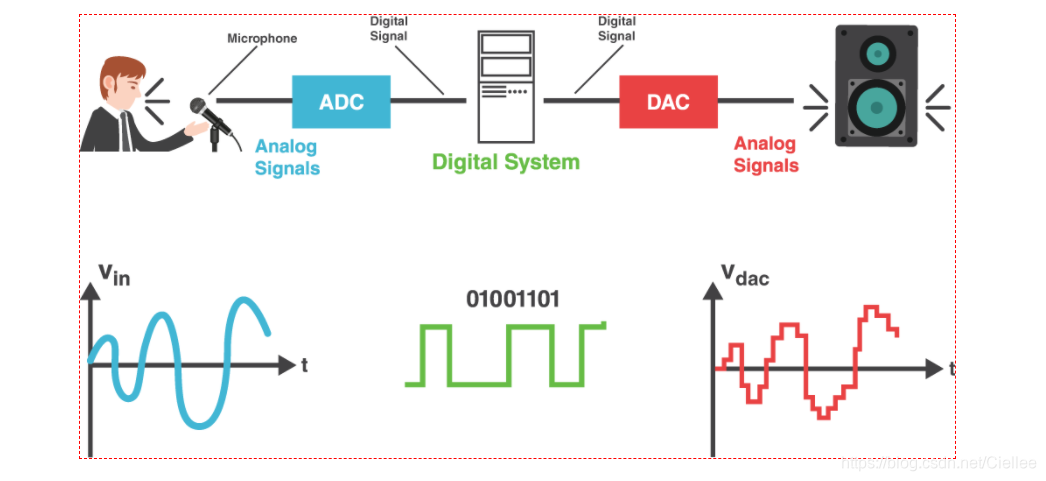
如何将各种媒体源数字化呢?

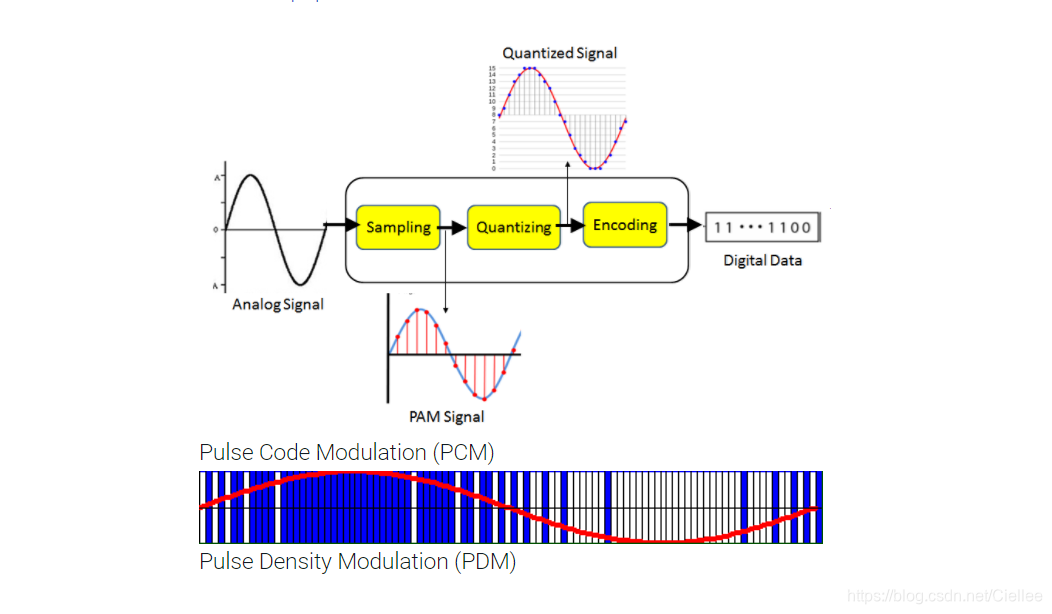
将声波波形信号通过 ADC 转换成计算机支持的二进制的过程叫做音频采样 (Audio Sampling)。
采样 (Sampling) 的核心是把连续的模拟信号转换成离散的数字信号。
-
样本(Sample)
采样的初始资料,比如一段连续的声音波形。
-
采样器(Sampler)
采样器是将样本转换成终态信号的关键。
它可以是一个子系统,也可以指一个操作过程,甚至是一个算法,取决于不同的信号处理场景。理
想的采样器要求尽可能不产生信号失真。
-
量化(Quantization)
采样后的值还需要通过量化,也就是将连续值近似为某个范围内有限多个离散值的处理过程。
因为原始数据是模拟的连续信号,而数字信号则是离散的,它的表达范围是有限的,所以量化是必不可少的一个步骤。
-
编码(Coding)
计算机的世界里,所有数值都是用二进制表示的,因而我们还需要把量化值进行二进制编码。
这一步通常与量化同时进行。
-
采样率(samplerate)
采样就是把模拟信号数字化的过程,不仅仅是音频需要采样,所有的模拟信号都需要通过采样转换为可以用0101来表示的数字信号
示意图如下所示:
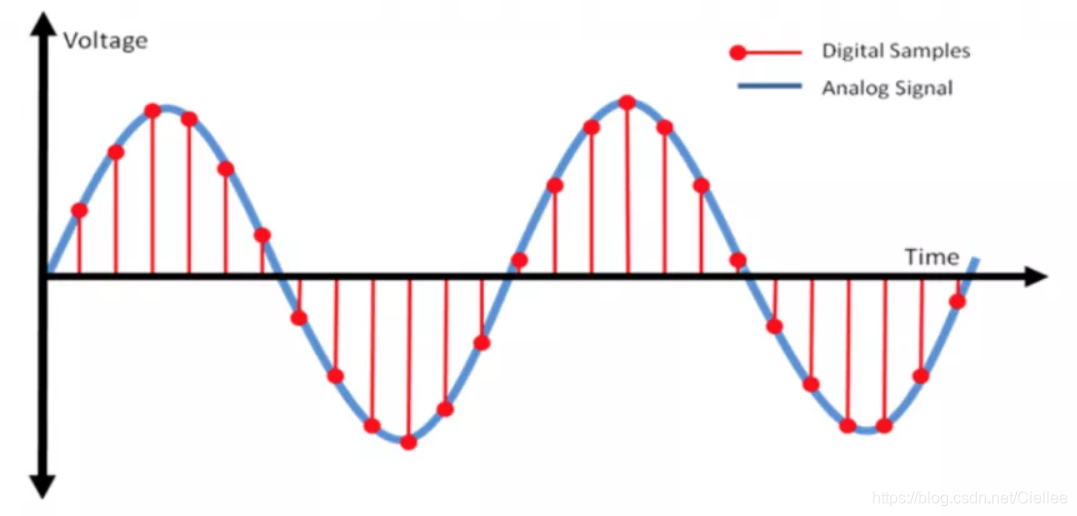
蓝色代表模拟音频信号,红色的点代表采样得到的量化数值。
采样频率越高,红色的间隔就越密集,记录这一段音频信号所用的数据量就越大,同时音频质量也就越高。
根据奈奎斯特理论,采样频率只要不低于音频信号最高频率的两倍,就可以无损失地还原原始的声音。
通常人耳能听到频率范围大约在20Hz~20kHz之间的声音,为了保证声音不失真,采样频率应在40kHz以上。
常用的音频采样频率有:8kHz、11.025kHz、22.05kHz、16kHz、37.8kHz、44.1kHz、48kHz、96kHz、192kHz等。
-
量化精度(位宽)
上图(1.8)中,每一个红色的采样点,都需要用一个数值来表示大小,
这个数值的数据类型大小可以是:4bit、8bit、16bit、32bit等等,
位数越多,表示得就越精细,声音质量自然就越好,当然,数据量也会成倍增大。常见的位宽是:8bit 或者 16bit
-
声道数(channels)
由于音频的采集和播放是可以叠加的,因此,可以同时从多个音频源采集声音,
并分别输出到不同的扬声器,故声道数一般表示声音录制时的音源数量或回放时相应的扬声器数量。单声道(Mono)和双声道(Stereo)比较常见,顾名思义,前者的声道数为1,后者为2
-
音频帧(frame)
这个概念在应用开发中非常重要,网上很多文章都没有专门介绍这个概念。
音频跟视频很不一样,视频每一帧就是一张图像,而从上面的正玄波可以看出,音频数据是流式的,本身没有明确的一帧帧的概念,
在实际的应用中,为了音频算法处理/传输的方便,一般约定俗成取2.5ms~60ms为单位的数据量为一帧音频。这个时间被称之为“采样时间”,其长度没有特别的标准,它是根据编解码器和具体应用的需求来决定的,
我们可以计算一下一帧音频帧的大小:假设某音频信号是采样率为8kHz、双通道、位宽为16bit,20ms一帧,则一帧音频数据的大小为:
int size = 8000 x 2 x 16bit x 0.02s = 5120 bit = 640 byte
-
常见的音频编码方式有哪些?
上面提到过,模拟的音频信号转换为数字信号需要经过采样和量化,量化的过程被称之为编码,根据不同的量化策略,产生了许多不同的编码方式。
常见的编码方式有:
PCM 和 ADPCM,这些数据代表着无损的原始数字音频信号,添加一些文件头信息,就可以存储为WAV文件了,它是一种由微软和IBM联合开发的用于音频数字存储的标准,可以很容易地被解析和播放。
-
常见的音频压缩格式有哪些?
首先简单介绍一下音频数据压缩的最基本的原理:因为有冗余信息,所以可以压缩。(1) 频谱掩蔽效应:
人耳所能察觉的声音信号的频率范围为20Hz~20KHz,在这个频率范围以外的音频信号属于冗余信号。(2) 时域掩蔽效应:
当强音信号和弱音信号同时出现时,弱信号会听不到,因此,弱音信号也属于冗余信号。下面简单列出常见的音频压缩格式:
MP3,AAC,OGG,WMA,Opus,FLAC,APE,M4A,AMR,等等
-
奈奎斯特采样理论
“当对被采样的模拟信号进行还原时,其最高频率只有采样频率的一半”。
换句话说,如果我们要完整重构原始的模拟信号,则采样频率就必须是它的两倍以上。
比如人的声音范围是2~ 20kHZ,那么选择的采样频率就应该在40kHZ左右,数值太小则声音将产生失真现象,而数值太大也无法明显提升人耳所能感知的音质。
-
总结(音频处理和播放过程)