7.5.4 读-复制-更新
RCU(Read-Copy-Update,读-复制-更新),是基于其原理命名的。RCU并不是新的锁机制,Linux社区关于RCU的经典文档位于https://www.kernel.org/doc/ols/2001/read-copy.pdf,Linux内核源代码Documentation/RCU/也包含了RCU的一些讲解。
不同于自旋锁,使用RCU的读端没有锁、内存屏障、原子指令类的开销,几乎可以认为是直接读(只是简单地标明读开始和读结束),而RCU的写执行单元在访问它的共享资源前首先复制一个副本,然后对副本进行修改,最后使用一个回调机制在适当的时机把指向原来数据的指针重新指向新的被修改的数据,这个时机就是所有引用该数据的CPU都退出对共享数据读操作的时候。等待适当时机的这一时期称为宽限期。
比如,由struct foo结构体组成的链表:
struct foo {
struct list_head list;
int a;
int b;
int c;
};
假设进程A要修改链表中某个节点N的成员a、b。自旋锁的思路是排他性地访问这个链表,等所有其他持有自旋锁的进程或者中断把自旋锁释放后,进程A再拿到自旋锁访问链表并找到N节点,之后修改它的a、b两个成员,完成后解锁。而RCU的思路则不同,它直接制造一个新的节点M,把N的内容复制给M,之后在M上修改a、b,用M来代替N原本在链表的位置。之后进程A等待在链表前期已经存在的所有读端结束后,再释放原来的N。
RCU可以看作读写锁的高性能版本,相比读写锁,RCU的优点既允许多个读执行单元同时访问被保护的数据,又允许多个读执行单元和多个写执行单元同时访问被保护的数据。但是,RCU不能替代读写锁,因为如果写比较多时,对读执行单元的性能提高不能弥补写执行单元同步导致的损失。因为使用RCU时,写执行单元之间的同步开销会比较大,它需要延迟数据结构的释放,复制被修改的数据结构,它也必须使用某种锁机制来同步并发的其他写执行单元的修改操作。
Linux中提供的RCU操作包括如下4种。
1.读锁定
rcu_read_lock()
rcu_read_lock_bh()
2.读解锁
rcu_read_unlock()
rcu_read_unlock_bh()
使用RCU进行读的模式如下:
rcu_read_lock()
.../* 读临界区*/
rcu_read_unlock()
3.同步RCU
synchronize_rcu()
该函数由RCU写执行单元调用,它将阻塞写执行单元,直到当前CPU上所有的已经存在的读执行单元完成读临界区,写执行单元才可以继续下一步操作。synchronize_rcu()并不需要等待后续读临界区的完成,如图7.9所示。
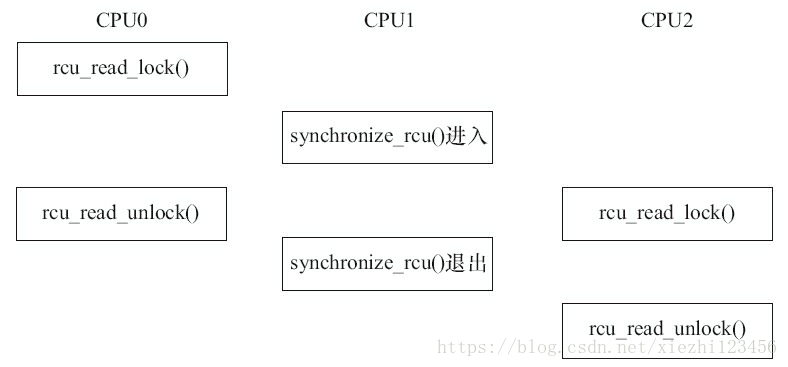
图7.9 synchronize_rcu
4.挂接回调
void call_rcu(struct rcu_head *head, void (*func)(struct rcu_head *rcu));
函数call_rcu()也由RCU写执行单元调用,与synchronize_rcu()不同的是,函数call_rcu()不会使写执行单元阻塞,可以在中断上下文或软中断中使用。call_rcu()把函数func挂接到RCU回调函数链上,然后立即返回。挂接的回调函数会在一个宽限期结束(即所有已经存在的RCU读临界区完成)后被执行。
rcu_assign_pointer(p, v)
给RCU保护的指针赋一个新的值。
读端使用rcu_dereference()获取一个RCU保护的指针,之后既可以安全地引用它(访问它指向的区域)。一般需要在rcu_read_lock()/rcu_read_unlock()保护的区间引用这个指针,例如:
rcu_read_lock();
irq_rt = rcu_dereference(kvm->irq_routing);
if (irq < irq_rt->nr_rt_entries)
hlist_for_each_entry(e, &irq_rt->map[irq], link) {
if (likely(e->type == KVM_IRQ_ROUTING_MSI))
ret = kvm_set_msi_inatomic(e, kvm);
else
ret = -EWOULDBLOCK;
break;
}
rcu_read_unlock();
rcu_access_pointer(p)
读端使用rcu_access_pointer()获取一个RCU保护的指针,之后并不引用它。这种情况下,只关心指针本身的值,而不关心指针指向的内容。
对于链表数据结构,Linux内核增加了专门的RCU保护的链表操作API:
1)static inline void list_add_rcu(struct list_head *new, struct list_head *head);
该函数把链表元素new插入RCU保护的链表head的开头。
2)static inline void list_add_tail_rcu(struct list_head *new,struct list_head *head);
该函数把新的链表元素new添加到被RCU保护的链表的末尾。
3)static inline void list_del_rcu(struct list_head *entry);
该函数从RCU保护的链表中删除指定的链表元素entry。
4)static inline void list_replace_rcu(struct list_head *old, struct list_head *new);
它使用新的链表元素new取代旧的链表元素old。
5)list_for_each_entry_rcu(pos, head)
该宏用于遍历由RCU保护的链表head,只要在读执行单元临界区使用该函数,它就可以安全地和其他RCU保护的链表操作函数(如list_add_rcu())并发运行。