整理自《统计学习方法——李航》

如果只是根据最后的结果对样本进行分类,那么直接可以分成两类,一类是“是”,一类是“否”。
根据前面讲的信息增益,这里的经验熵为:
![]()
然后还可以进行分类再计算。比如先分成是否是老年人还是中年或者青年人,然后再继续下分类别。
假设我们设置两层分类:

那么经过计算以后得到新的信息熵:
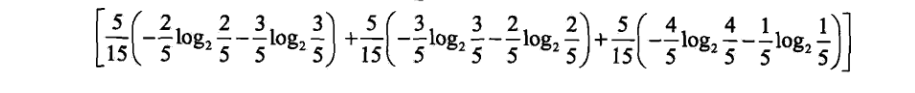
计算得到值 0.888
所以信息增益为0.971-0.888=0.083.
同理,还可以根据是否有工作进行两级分类,以及根据是否有房子进行两级分类。得到的信息增益各不相同。信息增益最大的分类方式则可以认为是最好的分类方式。
ID3算法详解。
书中已经说得非常明白了,这里也仅仅整理一下结果:
在进行了第一轮的分类以后,我们选择用是否有自己的房子作为第一个树节点,因为它的信息增益最大。
然后我们开始进行第二轮分类。第二轮我们判断下一种用于分类的特征:
因为有房子,则分类全都是“是”,所以不用再继续细分了。
如果没有房子,则可以根据下一种分类特征进行分类,剩余的三种特征分类的信息增益如下:
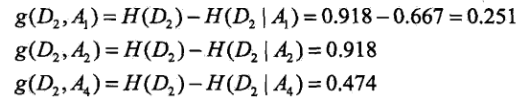
所以我们选择第二个特征作为新的分类方式,即有没有工作。
然后发现有工作的都是“是”。没有工作的都是“否”。如此,分类完毕。

缺点是在不断细分的过程中会造成过拟合现象,所以需要使用改进的算法。
C4.5算法。
C4.5就是设定阈值。如果在某一个树枝的最大的信息增益小于该阈值,则不继续进行分类,而是把该树枝中比例最大的一个类别作为该树枝的分类结果。
