1. 使用索引的好处:
1、保证数据记录的唯一性;
2、加快数据检索速度;
3、加快表与表间的连接速度;
4、在使用ORDER BY和GROUP BY子句中进行检索数据时可以显著减少查询中分组和排序的时间;
5、可以在检索数据的过程中使用优化隐藏器,提高系统性能。
2.聚集索引
-
作用:聚集索引中的键值的逻辑顺序决定了表中相应行的物理顺序。
-
原理:平时我们使用电话簿,我们会将各个人物,按姓氏的字母大小等来进行排序,为了方便以后好查找,聚集索引也类型,聚集索引确定表中数据的物理顺序,让数据在物理存储中按一定的顺序来组织存储,方便以后的查找。
-
注意点:
- 主键默认设置为聚集索引
- 由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引,但该索引可以包含多个列,就像电话簿可以按姓氏和名字进行组织一样。
3.非聚集索引
-
原理:该索引中索引的逻辑顺序与磁盘上行的物理存储顺序不同。
-
说明:类似于字典,有目录,通过目录查找到相应的字才能找到相应的说明。索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
4. 适用情况
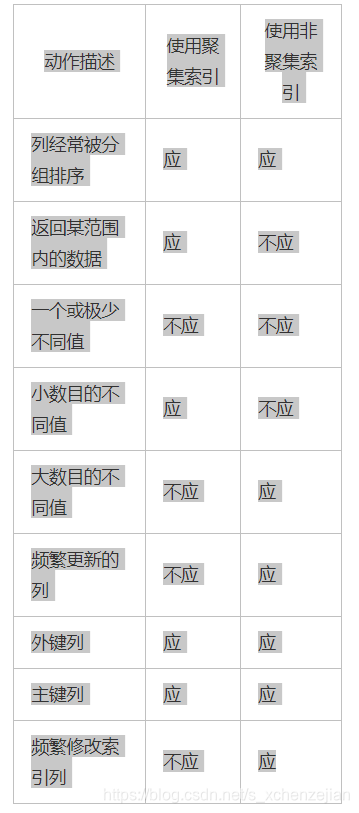
5.注意点
- 主键就应该是聚集索引
通常我们建立主键都是设置一个id自增,而在适用中一般会通过名字或者日期等来查找数据,而不是通过自动生成的id。
另外一方面,我们一个表又只能有一个聚集索引,如果设置为聚集索引就很浪费。
只要建立索引就能显著提高查询速度
参考文章:https://blog.csdn.net/zhou_xuexi/article/details/78028931
6. 相关sql语句:
| 动作描述 | 使用聚集索引 | 使用非聚集索引 |
|---|---|---|
列经常被分组排序 应 应
返回某范围内的数据 应 不应
一个或极少不同值 不应 不应
小数目的不同值 应 不应
大数目的不同值 不应 应
频繁更新的列 不应 应
外键列 应 应
主键列 应 应
频繁修改索引列 不应 应
//
创建索引
create CLUSTERED INDEX 索引名称 ON 表名(字段名)
//删除索引
alter table 表名 drop constraint 主键约束名称
//将指定字段设置成主键非聚集索引
alter table 表名 add constraint 主键约束名称 primary key NONCLUSTERED(字段名)
//创建表指定主键为非聚集索引,默认不写NONCLUSTERED为聚集索引
CREATE TABLE Test
(
ID INT PRIMARY KEY NONCLUSTERED --非聚集索引
)
