目录
(一) 定义
并查集(Union Find): 是一种树型的数据结构, 用于处理一些不相交集合(Disjoint Sets)的合并及查询问题.
- 合并(union): 将两个子集合并成同一个集合
- 查询(find): 判断两个元素是否属于同一子集
(二) 自定义并查集
1.并查集的接口
public interface UF {
int getSize();
/**
* p编号与q编号是否属于同一个集合, 是否连接
*
* @param p
* @param q
* @return
*/
boolean isConnected(int p, int q);
/**
* 合并编号p和元素q所属的集合
*
* @param p
* @param q
*/
void unionElements(int p, int q);
}
2.Quick Find方式实现的并查集
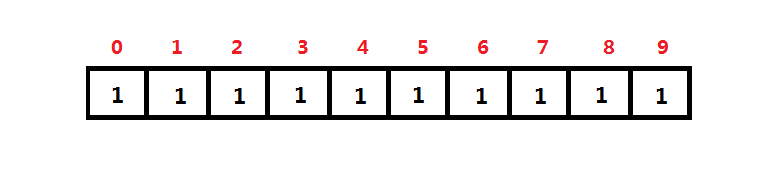
以数组的形式来表示并查集:
- 数组索引为数据编号ID, 编号ID具体意义根据业务需求而定(如学生编号, 员工编号)
- 通过数组元素的内容(集合编号)是否相同来判断数据编号是否为同一个集合

上图可知: ID0~4的集合编号为0, 属于一个集合; ID5~9的集合编号为1, 属于另一个集合.
public class QuickFind implements UF {
/**
* 并查集数组
*/
private int[] id;
public QuickFind(int size) {
id = new int[size];
// 初始化时, 每个ID都属于不同的集合
for (int i = 0; i < id.length; i++) {
id[i] = i;
}
}
}
- 在自定义并查集UF接口中的isConnected(p, q)中, 只需要查找IDp和q所对应的集合编号是否相等就可以判断它们是否属于同一个集合. 通过索引访问, 时间复杂度为O(1).
/**
* 查找元素编号p所对应的集合编号
*
* @param p
* @return
*/
private int find(int p) {
if (p < 0 || p >= id.length) {
throw new IllegalArgumentException("p is illegal.");
}
return id[p];
}
/**
* p编号与q编号是否属于同一个集合
*
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
- 在自定义并查集UF接口中的unionElements(p, q)中, 如果合并ID为 4和5 的集合, 就相当于将ID 0-4 和 5-9 的集合合并, 设置同一个集合编号. 需要遍历赋值操作, 时间复杂度为O(n).
/**
* 合并编号p和编号q所属的集合
*
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pID = find(p);
int qID = find(q);
// 编号p和编号q属于同一个集合
if (pID == qID) {
return;
}
for (int i = 0; i < id.length; i++) {
if (id[i] == pID) {
id[i] = qID;
}
}
}
基于Quick Find的实现的并查集, 查询操作的时间复杂度为O(1), 合并操作的时间复杂度为O(n). 在数据很大的情况下O(n)复杂就不容乐观. 因此引出Quick Union方式优化.
3.Quick Union方式实现的并查集
以树结构来描述并查集, 将每一个元素看做是一个结点. 较特殊的是:
- 孩子结点指向父亲结点
- 根结点指向根结点
底层还是用数组存储元素:
- 数组索引为编号ID具体意义根据业务需求而定(如学生编号, 员工编号)
- 数组元素内容存储的是编号ID对应的父节点编号ID
每个节点的父节点编号都是它自己,说明每个节点都是一个根节点,那么这个数组就表示一个森林

合并编号ID 4, 3; 合并编号ID 6, 5

合并编号ID 6, 4: 找到 6 和 4 的对应的根节点,然后让 6 的根节点指向 4 的根节点

public class QuickUnion implements UF{
/**
* 并查集数组
*/
private int[] parent;
public QuickUnion(int size) {
parent = new int[size];
// 初始化时, 每个ID都属于不同的集合
for (int i = 0; i < parent.length; i++) {
parent[i] = i;
}
}
/**
* 查找编号ID为p所在的根结点集合编号ID
*
* @param p
* @return
*/
private int find(int p) {
if (p < 0 && p >= parent.length) {
throw new IllegalArgumentException("p is Illegal.");
}
while(p != parent[p]) {
p = parent[p];
}
return p;
}
/**
* p编号与q编号是否属于同一个集合
*
* @param p
* @param q
* @return
*/
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
/**
* 合并编号p和元素q所属的集合
*
* @param p
* @param q
*/
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
// 编号p和编号q属于同一个集合
if (pRoot == qRoot) {
return;
}
// p编号所在根结点的编号指向q编号所在根结点的编号
parent[pRoot] = qRoot;
}
@Override
public int getSize() {
return parent.length;
}
}
基于Quick Union的实现的并查集, 查询操作和合并操作的时间复杂度都为O(h). h为树的高度
4.Quick Find 与 Quick Union 性能比较
/**
* 对并查集的合并(union)和查询(find)的操作先后执行各count次
*
* @param uf
* @param count
* @return
*/
private static double testUF(UF uf, int count) {
int size = uf.getSize();
Random random = new Random();
long startTime = System.nanoTime();
for (int i = 0; i < count; i++) {
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.unionElements(a, b);
}
for (int i = 0; i < count; i++) {
int a = random.nextInt(size);
int b = random.nextInt(size);
uf.isConnected(a, b);
}
long endTime = System.nanoTime();
return (endTime- startTime) / 1000000000.0;
}
public static void main(String[] args) {
int size = 10000;
int count = 10000;
QuickFind uf1 = new QuickFind(size);
System.out.println("QuickFind: " + testUF(uf1, count) + " s");
QuickUnion uf2 = new QuickUnion(size);
System.out.println("QuickUnion: " + testUF(uf2, count) + " s");
}

合并和查询操作执行1万次时, Quick Union 的性能略比 Quick Find 快些. 但在100万次操作下, Quick Find 远比 Quick Union 快, 如图:

造成此原因有如下几点:
- Quick Find 的并查集查询的操作时间复杂度为 O(1), Quick Union的合并和查询都是O(h)
- Quick Union生成的树的深度很高, 最差的情况有可能退化成链表(没有对树的高度进行任何优化和限制)
依次执行合并操作: union(0,1), union(0,2), union(0,3)

5. 基于size的优化
节点个数少的树指向节点个数多的树, 如执行union(0,4)

public class QuickUnion_Size implements UF{
private int[] parent;
/**
* sz[i] 表示以i为根的集合中元素个数
*/
private int[] sz;
public QuickUnion_Size(int size) {
parent = new int[size];
sz = new int[size];
// 初始化时, 每个ID都属于不同的集合, 每个根结点一开始也只有一节点
for (int i = 0; i < parent.length; i++) {
parent[i] = i;
sz[i] = 1;
}
}
private int find(int p) {
if (p < 0 && p >= parent.length) {
throw new IllegalArgumentException("p is Illegal.");
}
while(p != parent[p]) {
p = parent[p];
}
return p;
}
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
// 节点个数少的树指向节点个数多的树
if(sz[pRoot] < sz[qRoot]) {
parent[pRoot] = qRoot;
sz[qRoot] += sz[pRoot];
} else {
parent[qRoot] = pRoot;
sz[pRoot] += sz[qRoot];
}
}
@Override
public int getSize() {
return parent.length;
}
}
性能比较: 对三个并查集的合并(union)和查询(find)的操作先后执行各10万次

基于size的优化(结点个数少的树指向节点个数多的树): 并不代表结点个数与树的深度成正比, 比如 union(2, 4), 2所在的根结点的结点数为3, 4所在的根结点数为2, 合并后书的高度由原来的3变成4

反之, 如果将2的根结点指向4的根结点, 那么树的深度还是原来的3, 显然基于size的优化方式还是有缺陷的
6. 基于rank的优化
深度低的树指向深度度高的树

public class QuickUnion_Rank implements UF {
private int[] parent;
/**
* rank[i] 表示以i为根的树的深度
*/
private int[] rank;
public QuickUnion_Rank(int size) {
parent = new int[size];
rank = new int[size];
// 初始化时, 每个ID都属于不同的集合, 每个根结点一开始也只有一节点
for (int i = 0; i < parent.length; i++) {
parent[i] = i;
rank[i] = 1;
}
}
private int find(int p) {
if (p < 0 && p >= parent.length) {
throw new IllegalArgumentException("p is Illegal.");
}
while (p != parent[p]) {
p = parent[p];
}
return p;
}
@Override
public boolean isConnected(int p, int q) {
return find(p) == find(q);
}
@Override
public void unionElements(int p, int q) {
int pRoot = find(p);
int qRoot = find(q);
if (pRoot == qRoot) {
return;
}
// 根据根节点所在树的层级来判断合并方向
// 深度低的树指向深度度高的树, 只有rank相等的情况才需要维护rank
if (rank[pRoot] < rank[qRoot]) {
parent[pRoot] = qRoot;
} else if (rank[qRoot] < rank[pRoot]) {
parent[qRoot] = pRoot;
} else {
parent[pRoot] = qRoot;
rank[qRoot] += 1;
}
}
@Override
public int getSize() {
return parent.length;
}
}
性能比较: 对并查集的合并(union)和查询(find)的操作先后执行各10万次

7. 路径压缩的优化
路径压缩的优化基于rank的基础上进一步优化, 优化时机是在执行 find(p)操作 的时候对其进行路径压缩.
- 在find(int p)方法中, 查找编号ID为p所在的根结点集合编号ID, 一层一层的往上找, 直到找到根结点. 此时我们在往上找的步骤之前, 改变p编号的指向父结点编号ID为上上个父结点编号ID.

private int find(int p) {
if (p < 0 && p >= parent.length) {
throw new IllegalArgumentException("p is Illegal.");
}
while(p != parent[p]) {
// 改变p编号的指向父结点编号ID为上上个父结点编号ID.
parent[p] = parent[parent[p]];
p = parent[p];
}
return p;
}
- 在find(int p)方法中, 查找编号ID为p所在的根结点集合编号ID, 一层一层的往上找, 直到找到根结点. 此时我们在往上找的步骤中, 改变p编号的指向父结点编号ID为根结点编号ID.

private int find(int p) {
if (p < 0 && p >= parent.length) {
throw new IllegalArgumentException("p is Illegal.");
}
if (p != parent[p]) {
//改变p编号的指向父结点编号ID为根结点编号ID.
parent[p] = find(parent[p]);
}
return parent[p];
}
