Article directory
-
-
- 01. Kafka replication
- 02. kafka replica information
- 03. What do ISR, AR and OSR stand for in kafka?
- 04. What does ISR scaling in kafka mean?
- 05. Under what circumstances will a broker be kicked out of the ISR?
- 06. What are the roles of kafka replicas and ISR?
- 07. What does it mean if the kafka replica is not in the ISR for a long time?
- 08. How to synchronize kafka follower copy with leader copy?
- 09. How does kafka achieve master-slave synchronization?
- 10. Kafka controller election?
- 11. The Kafka controller is responsible for the leader election of the partition
- 12. Which places in Kafka require election, and what are the election strategies for these places?
- 13. kafka Partition Leader election
- 14. kafka Partition Leader election process
- 15. What do kafka HW and LEO stand for?
- 16. How to understand the relationship between ISR collection, HW and LEO?
-
01. Kafka replication
1. Classification of kafka replicas
Kafka is often described as "a distributed, partitioned, replicable commit log service." The reason why replication is so important is that it ensures the availability and durability of Kafka even when individual nodes fail. Kafka data is stored in topics. Each topic is divided into several partitions, and each partition can have multiple copies. Replicas are stored on brokers, and each broker can store replicas of hundreds or thousands of topics and partitions. There are two types of replicas:
① Leader copy: Each partition has a leader copy. To ensure consistency, all producer and consumer requests go through this copy. Clients can read data from either the leader replica or the follower replica.
② Follower copies: All copies except the leader are follower copies. If not specified, follower replicas will not handle requests from clients; their main task is to copy messages from the leader and maintain a consistent state with the leader. If the leader collapses, one of the followers will be promoted to the new leader.
2. Replica synchronization
Another task of the leader is to figure out which follower copies have the same status as himself. In order to stay in sync with the leader, followers will try to copy messages from the leader, but they may not be able to stay in sync with the leader for various reasons. For example, network congestion causing replication to slow down, or a broker crashing and restarting, will cause replication lag across all replicas.
To stay in sync with the leader, the follower needs to send a Fetch request to the leader, which is the same request a consumer sends to read messages. In response, the leader returns a message to the followers. The Fetch request message contains the offset of the message that the follower wants to obtain. These offsets are always in order. This way, the leader knows if a replica has fetched all messages before the most recent message. By checking the last offset requested by each replica, the leader knows how lagging each replica is.
If a replica does not send a request within 30 seconds, or if it does send a request but is more than 30 seconds removed from the latest message, then it is considered out of sync. If a replica fails to keep up with the leader, it will no longer be able to become the new leader if the leader fails - after all, it does not have all the messages.
A replica that continuously issues requests for the latest messages is called a synchronized replica. When a leader fails, only synchronized replicas are eligible to be elected as the new leader. How long a follower is allowed to be inactive or how long a follower is allowed to become an out-of-sync replica is configured via the replica.lag.time.max.ms parameter. This time directly affects client behavior and data retention mechanisms during leader election.
3. Preferred leader
In addition to the current leader, each partition has a preferred leader, which is the leader selected when the topic was created. The reason why it is preferred is that when the partition is created, the distribution of partition leaders among the brokers is already balanced. Therefore, we hope that when the preferred leader becomes the current leader, the load among the brokers is balanced. By default, Kafka's auto.leader.rebalance.enable will be set to true, which will check whether the preferred leader is the current leader and whether it is synchronized. If it is synchronized but not the current leader, a leader election will be triggered, making the preferred leader the current leader.
The preferred leader can be easily found from the partition's replica list. The first replica in the list is generally the preferred leader, and this will not change regardless of which replica the current leader is, or if the replica is reassigned to another broker using the replica allocation tool. Note that if you manually reassigned replicas, the first assigned replica will be the preferred leader. Therefore, it is necessary to ensure that the preferred leaders are assigned to different brokers to avoid the situation where a small number of brokers containing leaders are overloaded and other brokers are unable to share the load for them.
02. kafka replica information
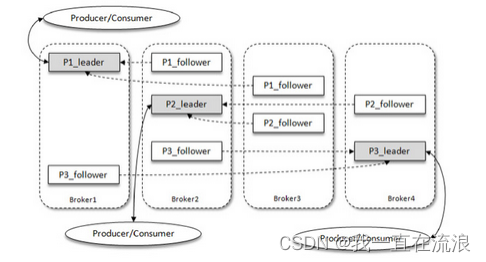
Kafka introduces a multi-replica mechanism for partitions, which can improve disaster recovery capabilities by increasing the number of replicas. The same message is stored in different copies of the same partition. Each partition has a leader copy and multiple follower copies. The leader copy is responsible for processing read and write requests, and the follower copy is only responsible for synchronizing messages with the leader copy. The replicas are in different brokers. When the leader replica fails, Kafka will automatically elect a new leader replica from the follower replica to provide external services. This process is called replica reallocation. During replica redistribution, Kafka will still function normally, but some delays may occur. Kafka implements automatic failover through a multi-replica mechanism, and can still ensure service availability when a broker in the Kafka cluster fails.
As shown in the figure, there are 4 brokers in the Kafka cluster, 3 partitions in a topic, and the replica factor (number of replicas) is also 3, so each partition has 1 leader replica and 2 follower replicas. Producers and consumers only interact with the leader copy, and the follower copy is only responsible for message synchronization. In many cases, the messages in the follower copy will lag behind the leader copy.
Kafka’s replication mechanism can provide the following benefits:
① Data reliability: Even if a copy fails, the data can still be recovered from other copies.
② High availability: Even if a replica fails, Kafka can still work normally.
③ Improve reading performance: Since messages can be read from any replica, reading performance can be improved.
The Kafka consumer also has certain disaster recovery capabilities. Consumer uses the Pull mode to pull messages from the server and saves the specific location of consumption. When the consumer comes back online after being down, it can re-pull the required messages for consumption based on the previously saved consumption location, so that there will be no causing message loss.
03. What do ISR, AR and OSR stand for in kafka?
Kafka is a distributed stream processing platform, in which ISR, AR and OSR are three important concepts in Kafka.
① ISR (In-Sync Replicas): refers to the set of replicas that are synchronized with the Leader replica. When the Producer sends a message to the Kafka cluster, only the replica in the ISR will write the message, ensuring data reliability and consistency. If a replica in the ISR cannot stay synchronized with the leader, the replica will be removed from the ISR until it is resynchronized with the leader.
② OSR (Out-of-Sync Replicas): refers to the set of replicas that are out of synchronization with the Leader replica. When a replica in the ISR cannot be synchronized with the Leader, the replica will be moved to the OSR until it is resynchronized with the Leader.
③ AR (Assigned Replicas): refers to the set of replicas assigned to a Partition. AR includes ISR and OSR.
In short, ISR is an important mechanism in Kafka to ensure data reliability and consistency, while AR and OSR are replica sets related to Partition.
All replicas in a partition are collectively called AR. All replicas (including the leader replica) that maintain a certain degree of synchronization with the leader replica form an ISR. The ISR set is a subset of the AR set. The message will be sent to the leader copy first, and then the follower copy can pull the message from the leader copy for synchronization. During the synchronization period, the follower copy will lag behind the leader copy to a certain extent. The "certain degree of synchronization" mentioned earlier refers to the tolerable lag range, which can be configured through parameters. The replicas (excluding the leader replica) that are too late in synchronization with the leader replica form an OSR. It can be seen that AR=ISR+OSR. Under normal circumstances, all follower copies should maintain a certain degree of synchronization with the leader copy, that is, AR=ISR and the OSR set is empty.
The leader copy is responsible for maintaining and tracking the lagging status of all follower copies in the ISR set. When a follower copy lags too far behind or fails, the leader copy will remove it from the ISR set. If a follower copy in the OSR set "catches up" with the leader copy, the leader copy will transfer it from the OSR set to the ISR set. By default, when the leader replica fails, only replicas in the ISR set are eligible to be elected as the new leader, while replicas in the OSR set do not have any chance.
04. What does ISR scaling in kafka mean?
Scaling in ISR refers to the dynamic changes of replicas in ISR. When a replica falls behind the leader, it is removed from the ISR until it becomes synchronized with the leader again. When a replica catches up with the leader replica, it will be rejoined in the ISR. This dynamic change can be completed automatically through Kafka's replica management mechanism, thereby ensuring that the replica set in the ISR is always synchronized with the leader replica.
05. Under what circumstances will a broker be kicked out of the ISR?
ISR (In-Sync Replicas) is a mechanism used in Kafka to ensure data reliability and high availability. The replica in the ISR is synchronized with the Leader replica, which ensures that when the Leader replica goes down, the replica in the ISR can replace it as the new Leader replica, thereby ensuring data reliability and high availability.
Generally, a broker will be kicked out of the ISR under the following circumstances:
① Replica synchronization delay: If the synchronization delay between the replica in the ISR and the Leader replica exceeds a certain threshold, the replica will be kicked out of the ISR.
② Copy failure: If the copy in the ISR fails, such as network failure, hardware failure, etc., then the copy will also be kicked out of the ISR.
③ Copy expiration: If the copy in the ISR is not synchronized with the Leader copy for a long time, the copy will also be kicked out of the ISR.
It should be noted that when a broker is kicked out of the ISR, troubleshooting and repairs need to be carried out in a timely manner to ensure data reliability and high availability.
06. What are the roles of kafka replicas and ISR?
Replicas and ISR (In-Sync Replicas) are very important concepts in Apache Kafka. They play the following roles:
① Copies: Each partition in Kafka has multiple copies, and each copy is a complete copy of the partition data. The role of replicas is to improve the reliability and availability of data. When the broker where a replica is located goes down, other replicas can continue to provide services, ensuring that data will not be lost.
② ISR: ISR refers to the set of replicas that are synchronized with the leader replica. When the leader copy fails, a copy in the ISR will be elected as the new leader copy. Only replicas in the ISR can be elected as new leader replicas because they ensure data consistency. If a replica becomes out of sync with the leader replica, it will be removed from the ISR until it is back in sync with the leader replica.
Therefore, replicas and ISR are important means for Kafka to achieve high availability and data consistency.
07. What does it mean if the kafka replica is not in the ISR for a long time?
In Kafka, ISR (in-sync replicas) refers to the set of replicas that are synchronized with the leader replica. If a replica is not in the ISR for a long time, it means that there is a problem with data synchronization between the replica and the leader replica, which may be due to network failure, hardware failure, or other reasons. In this case, the replica may fall behind other replicas, causing data inconsistency. Therefore, Kafka will remove the copy from the ISR to avoid data inconsistency. When the replica returns to normal, Kafka will rejoin it in the ISR to ensure data synchronization.
08. How to synchronize kafka follower copy with leader copy?
The follower copy in Kafka maintains consistency with the leader copy by synchronizing data with the leader copy. The process of synchronization between the follower node and the leader node is as follows:
① The follower node sends a pull request to the leader node, requesting the latest data.
② After receiving the pull request, the leader node sends the latest data to the follower node.
③ After the follower node receives the data, it writes it to the local log file and sends a confirmation message to the leader node, indicating that the data has been successfully received.
④ After the leader node receives the confirmation message, it marks the message as having been received by the follower node.
⑤ The follower node regularly sends heartbeat messages to the leader node to maintain the connection with the leader node.
⑥ If the follower node does not send a heartbeat message to the leader node within a certain period of time, or the leader node does not receive a confirmation message from the follower node within a certain period of time, the leader node will consider the follower node to have failed and move it from the replica set. remove.
09. How does kafka achieve master-slave synchronization?
Kafka uses a copy mechanism to achieve master-slave synchronization. Each partition has multiple replicas, with one replica designated as the leader and the other replicas as followers. The leader is responsible for handling all read and write requests, while followers simply copy the leader's data.
When a producer sends a message to Kafka, it sends the message to the leader replica. The leader replica writes the message to the local log and replicates the message to all follower replicas. Once all follower replicas have confirmed that the message was successfully replicated, the leader replica will send an acknowledgment message to the producer.
When a consumer reads a message from Kafka, it reads the data from the leader replica. If the leader replica is unavailable, consumers can read data from the follower replica. Kafka uses ZooKeeper to manage switching between leader and follower replicas to ensure high availability and data consistency.
10. Kafka controller election?
Kafka's controller is actually a broker, but in addition to providing general broker functions, it is also responsible for the leader election of the partition.
① Controller election is implemented through ZooKeeper. Only one broker can become the controller. Other brokers will monitor changes in the controller node. Once the controller node changes, other brokers will re-elect the controller.
The first broker started in the cluster will make itself the controller by creating a temporary node named /controller in ZooKeeper. Other brokers will also try to create this node when starting up, but they will receive a "node already exists" exception and "realize" that the controller node already exists, which means there is already a controller in the cluster. Other brokers will create a ZooKeeper watch on the controller node so that they can receive change notifications from this node. This way we ensure there is only one controller in the cluster.
② If the controller is shut down or disconnected from ZooKeeper, this temporary node will disappear. The ZooKeeper client used by the controller does not send heartbeats to ZooKeeper within the time specified by zookeeper.session.timeout.ms. This is one of the reasons for the disconnection. When the temporary node disappears, other brokers in the cluster will be notified that the controller node has disappeared and try to become the new controller themselves. The first broker to successfully create a controller node in ZooKeeper will become the new controller, and other nodes will receive a "node already exists" exception and will create a ZooKeeper watch again on the new controller node.
③ Each newly selected controller will obtain an epoch with a larger value through the ZooKeeper conditional increment operation. Other brokers will also know the current controller's epoch, and if they receive messages from the controller that contain smaller epochs, they will ignore them. This is important because controllers can become disconnected from ZooKeeper due to long garbage collection pauses—during which a new controller is elected. When the old controller resumes after a pause, it is unaware that a new controller has been elected and will continue sending messages - in this case the old controller is considered a "zombie controller". The epoch in the message can be used to ignore messages from the old controller, which is a way to defend against "zombie".
11. The Kafka controller is responsible for the leader election of the partition
The controller must load the latest replica set state from ZooKeeper before it can begin managing cluster metadata and perform leader elections.
When the controller discovers that a broker has left the cluster, all partitions whose original leader was on that broker need a new leader. It will go through all the partitions that need a new leader and decide which partition should be the new leader (probably the next replica in the replica set). It then persists the updated state to ZooKeeper and sends a LeaderAndISR request containing the new leader and follower information to all brokers that contain replicas of these partitions. Each new leader knows that it will start processing requests from producers and consumers, and followers also know that they will start replicating messages from the new leader. Each broker in the cluster has a MetadataCache, which contains a map that stores information about all brokers and replicas. The controller sends information about leader changes to all brokers through UpdateMetadata requests, and the brokers update their caches after receiving the request. A similar process occurs when starting a broker replica - the main difference is that all partition replicas of the broker are followers and need to be synchronized with the leader before they are eligible to be elected as the leader.
In general, Kafka will use ZooKeeper's temporary nodes to elect the controller and notify the controller when the broker joins or leaves the cluster. The controller is responsible for leader election when a broker joins or leaves the cluster. The controller will use epochs to avoid "split brain". The so-called "split brain" means that two brokers think that they are the current controller of the cluster at the same time.
12. Which places in Kafka require election, and what are the election strategies for these places?
① Controller election
The Controller is a node in the Kafka cluster and is responsible for managing the metadata information of the cluster, including Broker online and offline, Partition allocation, etc. When the current Controller node fails, a new Controller node needs to be elected to take over its responsibilities.
The controller election strategy is implemented through Zookeeper. Each Kafka Broker will create a temporary node on Zookeeper. The path of the node is /brokers/ids/[broker-id], where broker-id is the unique identifier of the Broker. When a Broker wants to become a Controller, it creates a temporary node /brokers/controller_epoch on Zookeeper. The value of the node is the current epoch value, and then tries to acquire the lock of the /brokers/controller node. If the lock is acquired successfully, the Broker becomes the new Controller node; otherwise, it will listen for changes in the /brokers/controller node and wait for the lock to be released.
② Partition Leader election
Each Partition has a Leader node in the Kafka cluster, which is responsible for processing read and write requests for the Partition. When the current Leader node fails, a new Leader node needs to be elected to take over its responsibilities.
The Partition Leader election strategy is implemented through collaboration between replicas. Each Partition has multiple copies, one of which is the Leader and the other copies are Followers. When the Leader node fails, the Follower node will initiate an election to elect a new Leader node.
The specific election process is as follows:
- The Follower node sends a Leader election request to all other replicas, and the request contains the offset value of the last message of the Partition.
- If the offset value of the last message of one of the other replicas is greater than or equal to the offset value of the Follower node, the replica becomes the new Leader node.
- If the offset value of no replica is greater than or equal to the offset value of the Follower node, the Follower node waits for a period of time and then re-initiates the election request.
It should be noted that in order to avoid split-brain, Kafka requires that at least one copy of each Partition is active, otherwise the Partition will be unusable. Therefore, when conducting Leader election, only those replicas that are active can participate in the election.
13. kafka Partition Leader election
Kafka is a distributed messaging system that divides messages into multiple partitions and stores them on multiple Brokers. Each partition has a Leader and multiple Followers. The Leader is responsible for processing read and write requests, and the Followers synchronize data from the Leader.
When a Broker goes down or a network failure prevents the Leader from working properly, Kafka needs to conduct a Partition Leader election to select a new Leader to handle read and write requests. The election process is as follows:
① Each Broker will regularly register its Broker information with Zookeeper and create a temporary node. The path of this node is /brokers/ids/[broker-id], and the value of the node is a string in JSON format, including the Broker's IP address, port number and other information.
② When a Broker goes down or a network failure causes the Leader to fail to work normally, Zookeeper will detect that the Broker's temporary node has been deleted and then notify other Brokers.
③ Other Brokers will check all Partitions. If the Leader of a Partition is a downed Broker, then it will try to become the new Leader. It will create a temporary node /brokers/topics/[topic]/[partition]/[broker-id] to Zookeeper, indicating that it wants to become the leader of this Partition.
④ If multiple Brokers try to become the Leader, Zookeeper will elect the Leader based on the order of node creation time. The node with the earliest creation time will become the new Leader.
⑤ After the election is completed, the new Leader will update the Partition's metadata to Zookeeper, and other Brokers will obtain the latest metadata from Zookeeper and update their caches.
It should be noted that Kafka's Partition Leader election is asynchronous, which means that after the election is completed, there may be a period of time when some messages cannot be processed normally. Therefore, Kafka's high availability relies on the existence of multiple replicas to ensure that even if a Broker goes down, the reliability and availability of messages can be guaranteed.
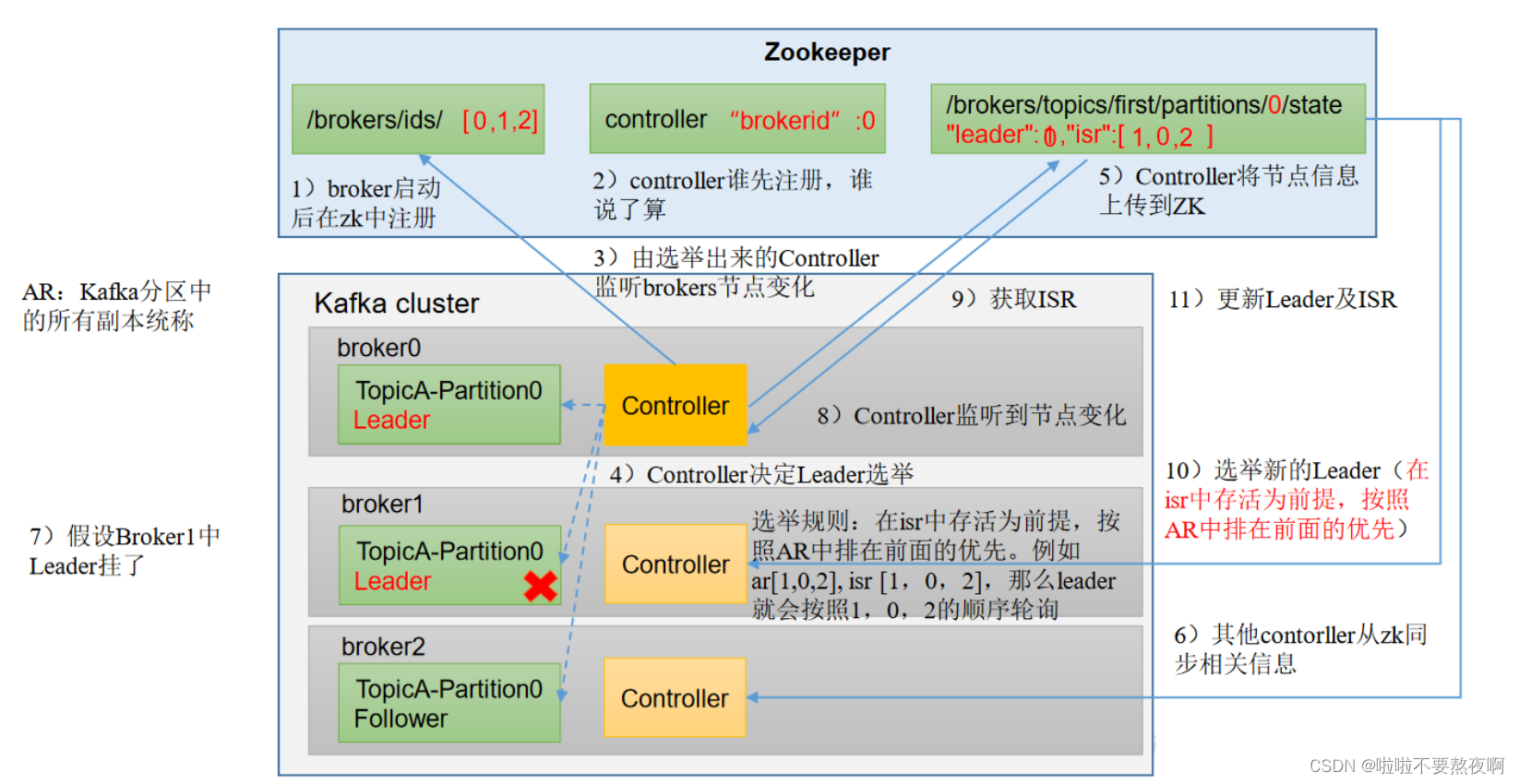
14. kafka Partition Leader election process
The Controller of a broker in the Kafka cluster will be elected as the Controller Leader and is responsible for managing the online and offline operations of the cluster broker, the distribution of partition copies of all topics, and Leader election. Controller's information synchronization work relies on Zookeeper.
Election process:
① Every time Kafka starts a node, it will register a node information in zookeeper. Each broker node has a corresponding Controller. They will compete to register the Controller first. Whoever registers first will be elected as the Controller Leader.
② The elected Controller will monitor broker node changes, decide the election of Leader, upload node information to zookeeper, and other Controllers will synchronize relevant information from zookeeper.
③ Assuming that the Leader in Broker1 hangs up, the Controller will monitor the node changes, then obtain the ISR, elect a new Leader (survive in the ISR is a prerequisite, and the priority in the AR will be followed), and update the Leader and ISR.
Use a cluster of 3 servers (brokerId=0,1,2) to verify the entire process above:
① Create a new topic, 3 partitions, and 3 copies:
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --create --partitions 3 --replication-factor 3 --topic test1
② Check the Leader distribution:
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test1 Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
③ Stop the kafka process with brokerId=0 and check the Leader partition:
If the kafka process with brokerId=0 hangs, then the Leader with Partition 2 will be re-elected. The election rules are: survival in the ISR is the premise, and the priority in AR is based on the priority, that is, the new Leader will be 2 .
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1,0
Topic: test1 Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2,1
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1
Topic: test1 Partition: 2 Leader: 2 Replicas: 0,2,1 Isr: 2,1
④ Stop the kafka process with brokerId=2 and check the Leader partition:
If the kafka process with brokerId=2 hangs, then the Leaders of Partition1 and Partition2 will be re-elected. The election rules are: survival in the ISR is the premise, and the priority in AR is given, that is, the new Leaders of Partition1 and Partition2 Both will be 1.
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 2,1
Topic: test1 Partition: 2 Leader: 2 Replicas: 0,2,1 Isr: 2,1
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1
Topic: test1 Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1
Topic: test1 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1
⑤ Start the kafka process with brokerId=0 and check the Leader partition:
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1
Topic: test1 Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1
Topic: test1 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0
Topic: test1 Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1,0
Topic: test1 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1,0
⑥ Start the kafka process with brokerId=2 and check the Leader partition:
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test1 Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1,0,2
Topic: test1 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1,0,2
⑦ Stop the kafka process with brokerId=1 and check the Leader partition:
If the kafka process with brokerId=1 hangs, then the Leaders of Partition0, Partition1 and Partition2 will be re-elected. The election rules are: survival in the ISR is the premise, and the priority in AR will be followed, that is, the Leader of Partition0 will is 0, the Leader of Partition1 will be 2, and the Leader of Partition2 will be 0.
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 1 Replicas: 1,0,2 Isr: 1,0,2
Topic: test1 Partition: 1 Leader: 1 Replicas: 2,1,0 Isr: 1,0,2
Topic: test1 Partition: 2 Leader: 1 Replicas: 0,2,1 Isr: 1,0,2
[root@localhost kafka-01]# bin/kafka-topics.sh --zookeeper localhost:2182 --describe --topic test1
Topic:test1 PartitionCount:3 ReplicationFactor:3 Configs:
Topic: test1 Partition: 0 Leader: 0 Replicas: 1,0,2 Isr: 0,2
Topic: test1 Partition: 1 Leader: 2 Replicas: 2,1,0 Isr: 0,2
Topic: test1 Partition: 2 Leader: 0 Replicas: 0,2,1 Isr: 0,2
It can be seen that the election is polled according to the order in AR, not the order in ISR.
15. What do kafka HW and LEO stand for?
HW is the abbreviation of High Watermark, commonly known as high water mark. It identifies a specific message offset (offset). Consumers can only retrieve messages before this offset.
As shown in the figure, it represents a log file. There are 9 messages in this log file. The offset of the first message is 0, and the offset of the last message is 8. The message with offset 9 is represented by a dotted box, which represents the next message to be written. incoming news. The HW of the log file is 6, which means that the consumer can only retrieve messages with an offset between 0 and 5, and messages with an offset of 6 are invisible to the consumer.
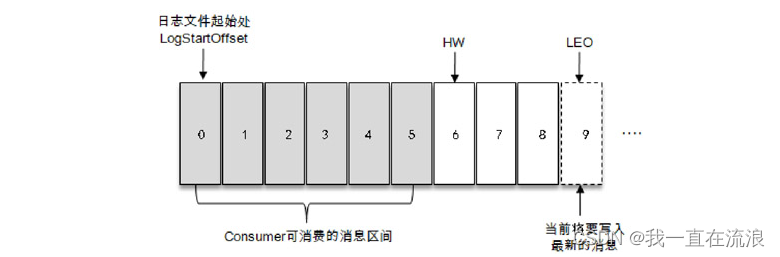
LEO is the abbreviation of Log End Offset, which identifies the offset of the next message to be written in the current log file. The position with offset 9 in the figure is the LEO of the current log file. The size of LEO is equivalent to the last message in the current log partition. The offset value is increased by 1. Each replica in the partitioned ISR set maintains its own LEO, and the smallest LEO in the ISR set is the HW of the partition. Consumers can only consume messages before the HW.
Important points to note: Many materials mistakenly regard the position with offset 5 in the picture as HW, and the position with offset 8 as LEO. This is obviously wrong.
16. How to understand the relationship between ISR collection, HW and LEO?
① Assume that there are 3 replicas in the ISR set of a certain partition, namely a leader replica and 2 follower replicas. At this time, the LEO and HW of the partition are both 3. After messages 3 and 4 are sent from the producer, they will first be stored in the leader copy:
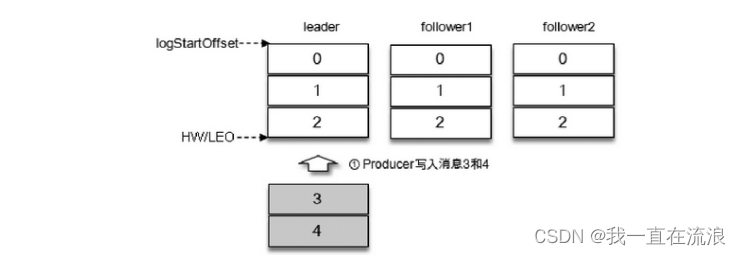
② After the message is written to the leader copy, the follower copy will send a pull request to pull messages 3 and 4 for message synchronization:
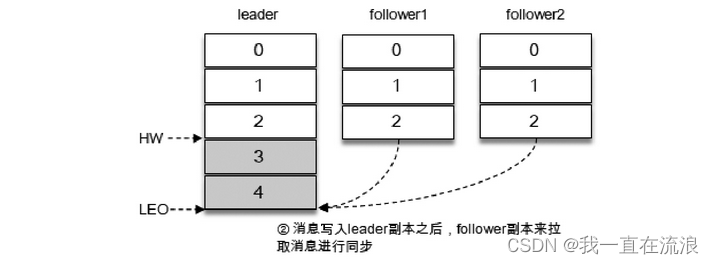
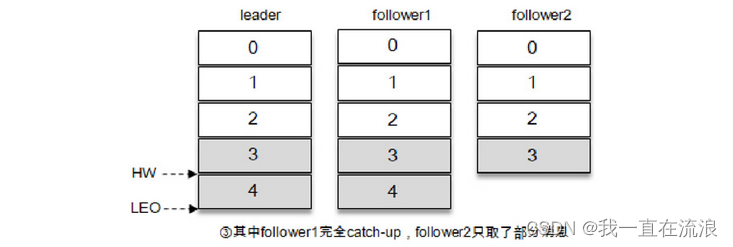
③ During the synchronization process, the synchronization efficiency of different follower copies is also different. At a certain moment, follower1 has completely caught up with the leader copy and follower2 has only synchronized message 3. In this way, the LEO of the leader copy is 5 and the LEO of follower1 is 5. , the LEO of follower2 is 4, then the HW of the current partition takes the minimum value 4. At this time, the consumer can consume messages with an offset between 0 and 3.
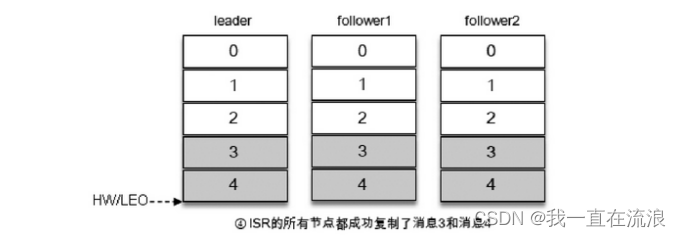
④ All replicas have successfully written message 3 and message 4, and the HW and LEO of the entire partition have become 5, so consumers can consume messages with offset 4.
Kafka's replication mechanism is neither completely synchronous replication nor purely asynchronous replication. In fact, synchronous replication requires that all working follower copies have been replicated before this message can be confirmed as successfully submitted. This replication method greatly affects performance. In asynchronous replication mode, the follower copy copies data from the leader copy asynchronously, and the data is considered successfully submitted as long as it is written by the leader copy. In this case, if the follower copy has not finished replicating and lags behind the leader copy, and the leader copy suddenly goes down, data loss will occur. The ISR method used by Kafka effectively weighs the relationship between data reliability and performance.