接上篇,我们的思路已经很清楚了,就是将U-Net改为1维处理ECG信号。可问题来了,数据怎么来?要知道,既然想用模型完成更高级的功能,那给出更为详尽的人工标注几乎是必然的。在这个任务里面,我们要给出的监督信号要包括各个片段中的信号类型以及它们精确的分界点。常用的MIT-BIH数据库只是给出了心拍的类型标记,而QT数据库中的信号虽然给出了心拍的边界参考,但大部分也是用某个算法来做的,真正人工标记的数据很少,况且,如果我们手头上有自己的数据,那怎么才能用到训练中呢?这里我提供了一种方式可以来自己做符合要求的数据。
首先介绍一个工具labelme。这个是计算机视觉领域用来制作带标签图像数据的工具之一,具体安装和使用方法可参考:https://blog.csdn.net/shwan_ma/article/details/77823281。总之,其作用就是,你可以通过操作鼠标,把图片中的目标物体用位置框框定以及标定类型,然后保存具体坐标位置和类别信息到一个json文件。
ECG本身是一个一维信号,似乎这里我们可以将信号保存成一张图像,然后按照图像标定信息,就像这样:

不过这里需要注意的有两点:
- 保存的ECG图像长度与该信号实际长度往往并不等同,例如一张长度为3000像素的图片保存了实际长度为1000采样点的信号,而labelme只会记录标定框在图片中的位置,如果不做额外处理是无法得到实际位置的;
- 虽然我们画了一个个矩形框,但由于ECG本质上是一维信号,所以真正有意义的是水平方向,也就是时间方向的位置是有意义的,垂直方向,也就是振幅方向,在知道水平方向的位置后可以直接得到精确的幅值。因此,在标记时我们只需要保证水平方向能够精准地分割信号就可以了。
对于第1点中的问题,也有解决办法。我们可以将一定长度的ECG片段的图片统一保存成相同分辨率的,没有白边的图片,这样,ECG的实际长度跟图片长度具有了固定的变换关系。例如,长度为3000像素的图片保存了实际长度为1000采样点的信号,labelme记录了某个点的水平位置为2700,则它在信号上的实际位置应为1000*(2700/3000)=900。可见经过一小步的换算,就可以解决问题。另外,labelme中似乎只能对矩形框的四个点分别地独立进行调整,这就容易导致一个问题:当我们在打标记时,往往需要微调,这样就容易使得原来的矩形变成不规则四边形,相对的两条边不平行。采用如下方式解决:设图片长度为Li,信号实际长度为Ls,labelme边界框四个点的水平位置坐标分别为xl1,xl2,xr1,xr2,在严格的矩形中xl1=xl2,xr1=xr2,但是由于微调导致上述关系不再严格成立,而又需要确定唯一的实际水平边界位置,进行如下换算:
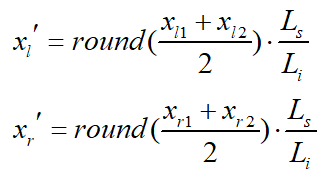
其中,xl’ 和xr’ 为左右边界在信号上的实际位置。另外,在生成ECG片段的图像时,需要实现将心拍类型也标记上去,比如在上面的图中,在正常心拍上标记了一个小圆圈,表示正常,在早搏的心拍上标记了一个小方框,表示早搏。这些信息都是来自数据库的专家标记,这样方便我们在做标记时知道各个心拍的类型,并且准确标记它们的边界。其实说白了,以MIT-BIH数据库为例,专家们已经给出了各个心拍的类型,我们要提供的信息只是各个心拍的精确边界,以及把专家标注的心拍类型“复制”一下进行再标注,以备后用。
然而,关于数据方面最大的问题是,人工标记耗时巨大,而且需要有专业经验的人来标记才能尽量准确。在MIT-BIH数据库众多的心律不齐类型中,个人认为早搏是最明显的,可能不需要太多医学上的经验就可以进行边界标记;另外人工标注实在是太耗费时间了,我选择了MIT-BIH中119这条信号,主要包含了正常和PVC心拍,抽时间标记了很长时间,才得到了600条有效数据,真心枯燥!!!不过咬咬牙还是免费分享给大家,以下的实验都是围绕这些数据展开。原始文件可在(链接:
https://pan.baidu.com/s/1wL59jTiCq5D9dgskC-xA6Q 提取码:1yh2)下载,解压即可。不要求别的了,请大家多多点赞和github给星吧。。。。。。。
这一部分的代码分别由开源项目中的几个代码文件完成,运行时要注意先后顺序:
- generate_files_for_manualLabel.m:用于生成用于人工标记的图像。其中调用了自定义函数rdecg,用于读取信号文件和对心拍的标注信息;
- data_preproc.py:用于人工标记后的文件(就像上面下载的文件那样,解压后可得119_MASK文件夹)整理。运行前先在同目录下新建一个文件夹119_SEG。注意,由于代码中包含了对文件的删除,因此在原始人工标记后的文件119_MASK中仅能运行一次。建议运行前先将原始文件备份!!!若遇到错误可重新恢复并重新执行。
- generate_labels.py:用于生成训练时的标签,将labelme生成的json文件中的信息转换为.npy文件存储。运行前先在同目录下新建一个文件夹119_LABEL。
- generate_train_val.py: 生成训练集和验证集。前面说了,我这里提供了自己标注的600个样本,选择其中500个做训练,100个做验证,分开保存。运行前新建文件夹train_sigs, train_labels, val_sigs, val_labels,分别保存训练集信号,标签,验证集信号,标签。
当然想省劲直接开始训练U-Net的,可以直接下载我提供的文件(链接:https://pan.baidu.com/s/1U8gyDi8X7N_aUoKO2MiRDQ 提取码:kecc),解压可得相应文件夹。
下篇是模型及其训练事宜。
github开源地址:https://github.com/Aiwiscal/ECG_UNet
喜欢请给star哦~~~
